
VIDEO SCENE SEGMENTATION WITH GENRE AND DURATION SIGNALS
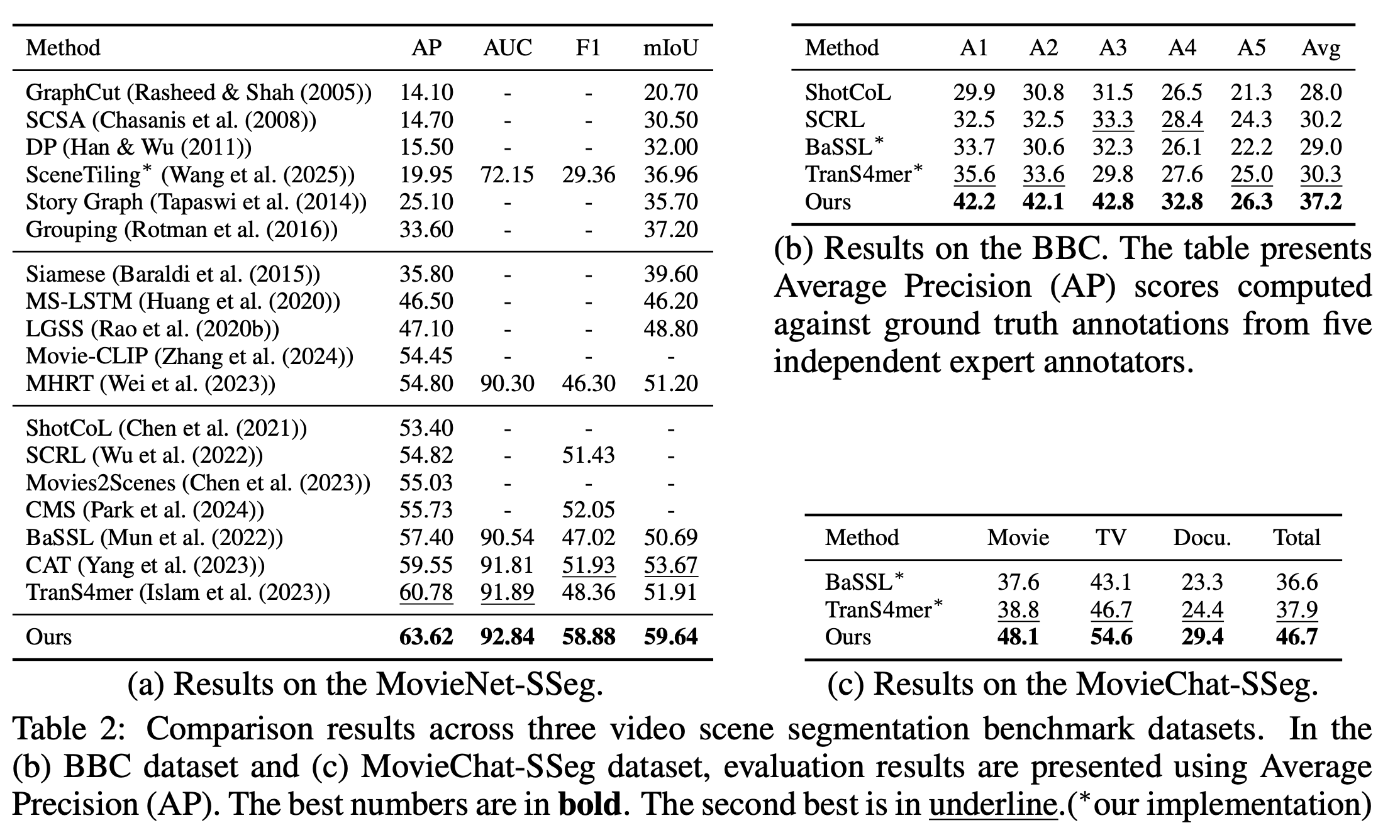
I. ABSTRACT 비디오 장면 분할은 긴 분량의 비디오에서 의미론적으로 일관된 경계를 검출하는 것을 목표로 하며, 이는 low-level의 시각적 신호와 high-level의 서사 이해 사이의 간극을 메우는 작업이다. 그러나 기존 방법론들은 주로 인접한 셧간의 시각
VideoMind: A Chain-of-LoRA Agent for Long Video Reasoning
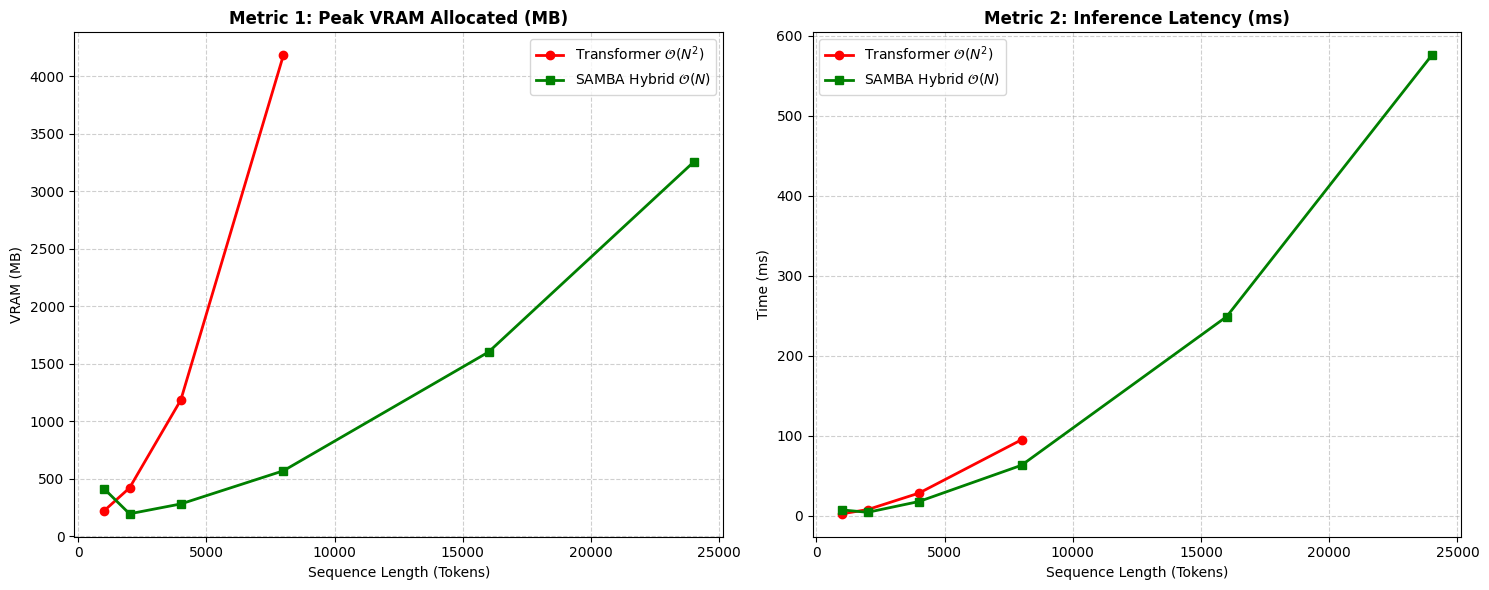
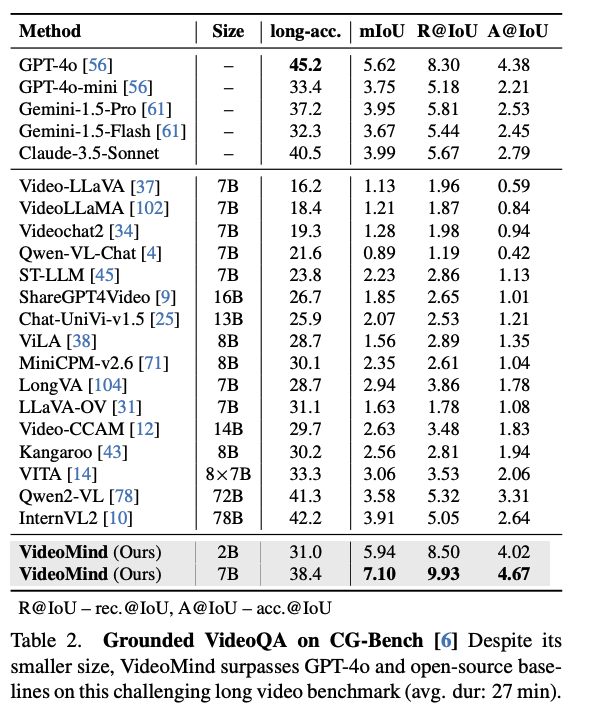
Abstract 비디오는 고유한 시계열적 차원을 지니고 있어, 답변이 해석 가능한 시각적 근거와 직접적으로 연결되는 Grounded Understanding을 요구한다.LLM의 추론 능력은 비약적 발전하였으나, 멀티모달 추론(특히 비디오)는 여전히 미개척 영역으로 남
Clothing Twin: Reconstructing Inner and Outer Layers of Clothing Using 3D Gaussian Splatting
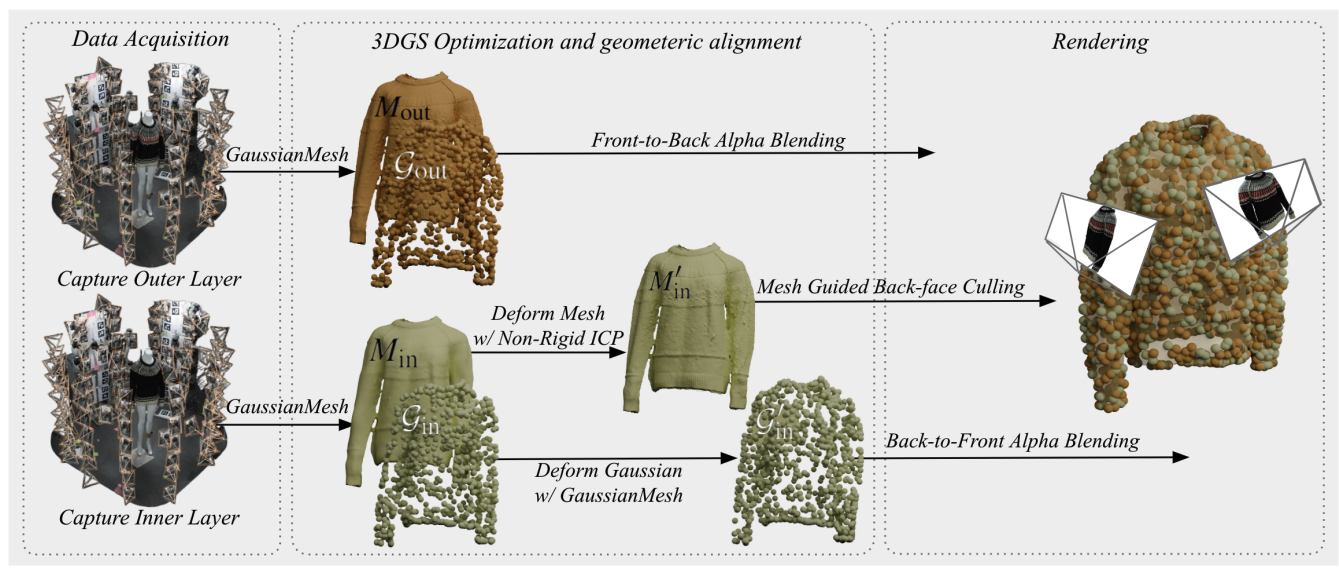
이번 포스팅에서는 Pacific Graphics 2025에 발표된 3D 의상 복원 관련 논문을 리뷰한다. 기존 3DGS(3D Gaussian Splatting) 연구들이 겉면 복원에 치중했다면, 이 논문은 의상의 안감(Inner Layer)까지 완벽하게 복원하는 파이프

[The Machine Learning] 1장: 소개
랩실에서 논문을 쓰면서, 대학원을 준비하면서 논문들도 많이 읽게되는 중이다. 다만, AI에 대해서는 학부 수업에서 배운내용들, 버클리대학의 CS188 우리 아주 혐오스러운(?) 로봇친구와 함께 열심히 배웠다.내용도 재밌고 얻어가는 부분도 많았지만 최근 논문을 읽으며 느

PARTE: Part-Guided Texturing for 3D Human Reconstruction
논문 정보 > Title: PARTE: Part-Guided Texturing for 3D Human Reconstruction from a Single Image > Authors: Hyeongjin Nam, Donghwan Kim et al. (Seoul Natio
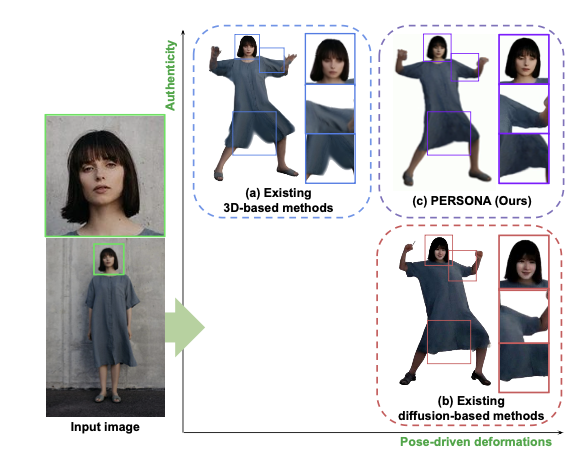
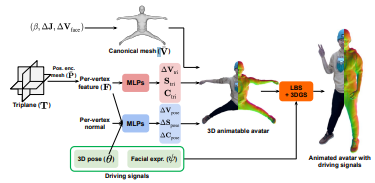
PERSONA: Personalized Whole-Body 3D Avatar with Pose-Driven Deformations from a Single Image
논문 정보 > Title: PERSONA: Personalized Whole-Body 3D Avatar with Pose-Driven Deformations from a Single Image > Authors: Geonhee Sim, Gyeongsik Moon (Ko

DiffExp: Efficient Exploration in Reward Fine-tuning for Text-to-Image Diffusion Models
논문 정보Title: DiffExp: Efficient Exploration in Reward Fine-tuning for Text-to-Image Diffusion ModelsAuthors: Daewon Chae, June Suk Choi, Jinkyu Kim, Ki
Expressive Whole-Body 3D Gaussian Avata
I.Abstract ExAvatar를 전신 파라메트릭 메쉬 모델(SMPL-X)과 3D Gaussian Splatting(3DGS)을 결합한 형태로 설계 주요 도전 과제는 1) 비디오 내 얼굴 표정과 포즈의 제한된 다양성과 2) 3D 스캔이나 RGBD 이미지와 같은
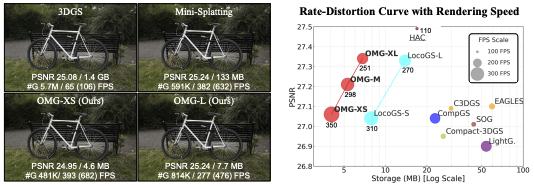
Optimized Minimal 3D Gaussian Splatting
가우시안 프리미티브의 개수를 최소한으로 유지하면서도 저장 용량을 최소화하는 것에 초점을 맞추고 증여한 가우시안들을 골라내 국소 구분도(local distinctiveness) 지표를 도입하였고 희소한 가우시안들에 대해 불규칙성과 연속성을 활용해 더 효율적인 속성 표현
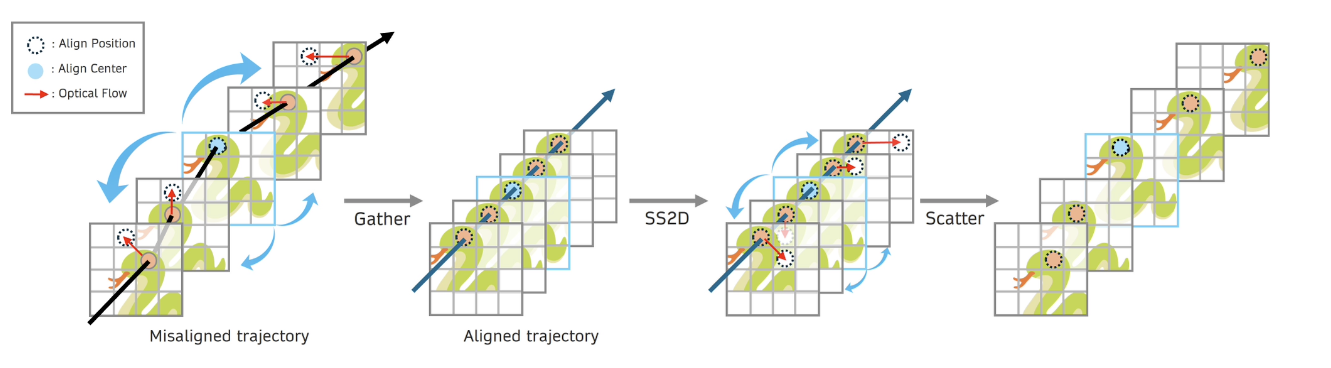
Gather-Scatter Mamba: Accelerating Video Super-Resolution
초록 상태 공간 모델(State Space Models, SSM)—가장 두드러지게는 RNN—은 역사적으로 순차 모델링에서 중심적인 역할을 수행해 왔습니다. 비록 트랜스포머(Transformers)와 같은 어텐션 메커니즘이 전역적 컨텍스트를 모델링하는 능력 때문에 이후
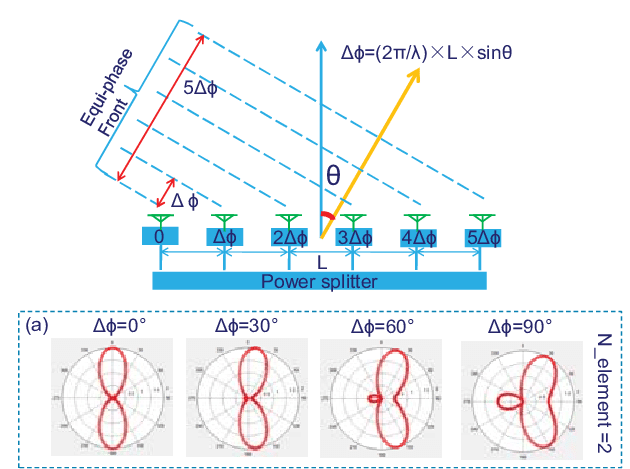
A Ka-Band Beam-Steering Radar Transmitter Using Active Multiplier and Coupled Delay Line Phase Shifter
본 논문은 결합형 바랙터 부하 전송선(VLTL, Varactor-Loaded Transmission Line) 위상천이기와 주파수 배수기(frequency multiplier)가 통합된 CMOS 송신 칩을 활용한 Ka-대역 빔 조향(beam-steering) 송신기를