
- 전체보기(286)
- 개념정리(46)
- OpenAI(46)
- chatGPT(37)
- paper-review(31)
- python(25)
- 환경(24)
- 강의노트(23)
- Conference(23)
- 꿀팁(21)
- 머신러닝(16)
- 딥러닝(15)
- IT지식(14)
- NLP(12)
- Timeseries(11)
- google(11)
- vibe coding(9)
- 이상탐지(9)
- trend-review(9)
- rag(9)
- git(8)
- linux(8)
- Lovable(8)
- CES(8)
- CIO(7)
- PyTorch(6)
- pandas(6)
- EXAONE(6)
- tools(5)
- 도서리뷰(5)
- CV(5)
- Graph(5)
- 차원축소(4)
- langgraph(4)
- Anthropic(4)
- SK(3)
- Distillation(3)
- Claude(3)
- snippet(3)
- 수학(2)
- pyenv/pipenv(2)
- Jupyter(2)
- network(2)
- Nvidia(2)
- AIS(2)
- splunk(2)
- IT정리(2)
- 통계(2)
- OLLAMA(2)
- Gemini(1)
- Snipppet(1)
- velog(1)
- 신호처리(1)
- visualization(1)
- prompt(1)
- 비지도학습(1)
- numpy(1)
- NotebookLM(1)
- agent(1)
- args(1)
- lg(1)
- vscode(1)
- langChain(1)
- Naver(1)
- streamlit(1)
Claude Code에서 디폴트로 Auto Mode 사용하기 (Windows·Linux)
요즘은 AI Agent에게 작업 대부분을 맡기는 시대입니다. 코드를 읽고 고치는 일은 물론이고, 셸 명령을 실행하고 환경을 정리하는 일까지 Agent에게 위임하는 흐름이 점점 자연스러워지고 있습니다.

[구글] 2026 Google I/O Developer Keynote정리: Agent가 주도하는 개발의 새 시대
Google I/O '26 Developer Keynote는 한마디로 정리할 수 있는 행사였습니다. "AI가 단순히 보조하는 시대는 끝났고, 이제 Agent가 직접 일을 처리하는 시대가 시작되었다"는 선언입니다.

[구글] 2026 Google I/O KeyNote 정리: Gemini 3.5, Omni, Antigravity 2.0 그리고 Agentic AI의 본격화
2026년 Google I/O 키노트는 AI 모델 발전을 넘어 Agentic AI(에이전트 AI)의 실용화가 본격 시작되었음을 알리는 자리였습니다.

첫 책이 나왔습니다 — <AI 바이브 코딩 마스터> 출간 후기
안녕하세요!! 서쿠입니다😊 오늘 포스팅에서는 작년 말부터 약 반년 가까이 퇴근 후·주말 시간을 쪼개 집필해온 첫 책 『AI 바이브 코딩 마스터』가 드디어 세상에 나왔다는 소식을 전하며, 어떤 책인지 짧게 소개드리고자 합니다.

[HAI] AI Index Report 2026 정리: 기술은 가속하고, 시스템은 뒤따라가기 바쁘다
Stanford HAI(Human-Centered AI Institute)가 매년 발간하는 AI Index Report는 AI 분야에서 가장 신뢰받는 독립 연감 중 하나입니다.

NVIDIA GTC 2026 키노트 완벽 정리: Inference Inflection부터 Physical AI까지
2025년 3월 17일, NVIDIA의 CEO Jensen Huang이 GTC 2026 키노트를 통해 AI 산업의 현재와 미래를 조망했습니다.
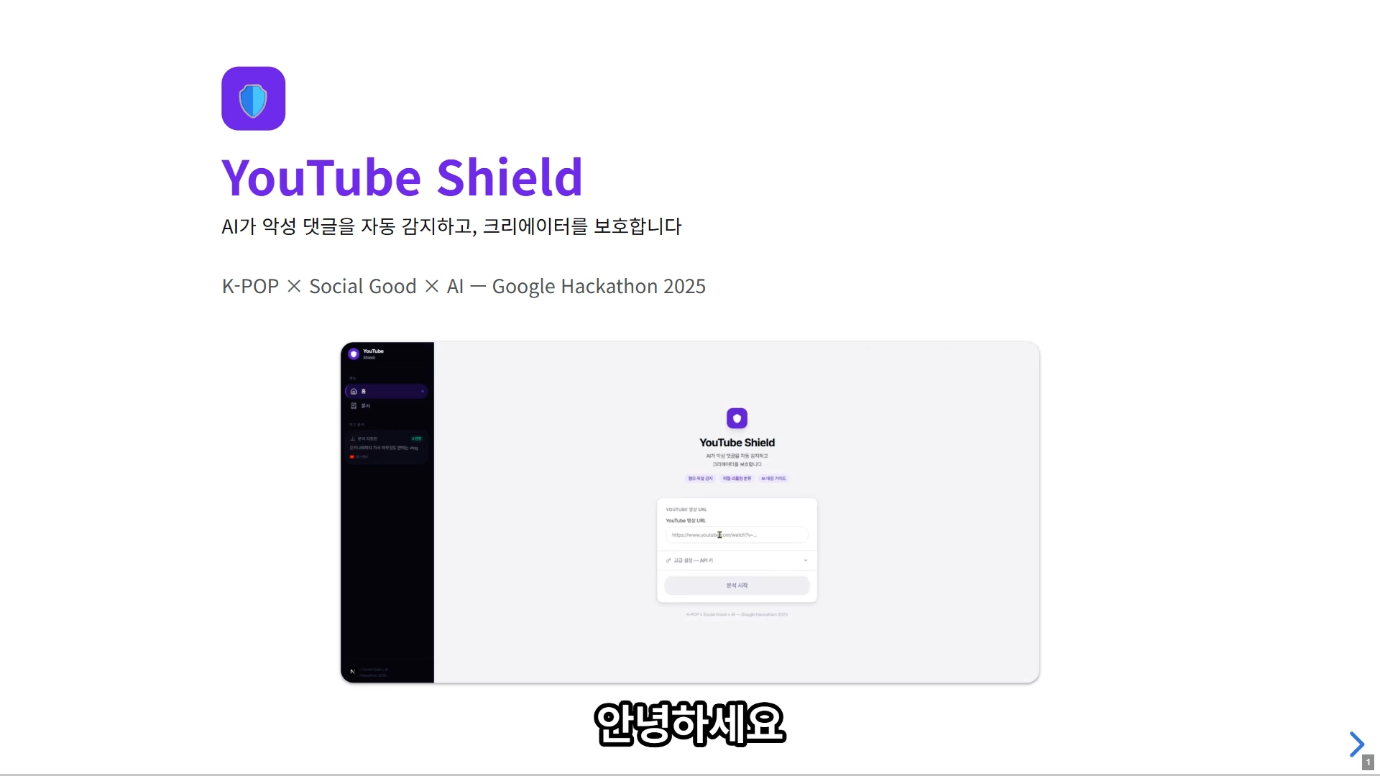
[Gemini 해커톤] Creator Hub: AI로 YouTube 악성 댓글을 자동 분석하는 풀스택 서비스
2026년 Google Gemini 해커톤에서 탄생한 Creator Hub. YouTube URL 하나로 한국어 악성 댓글을 Rule 엔진과 Gemini AI의 이중 파이프라인으로 자동 분석하고, 크리에이터에게 대응 방안까지 제시합니다.
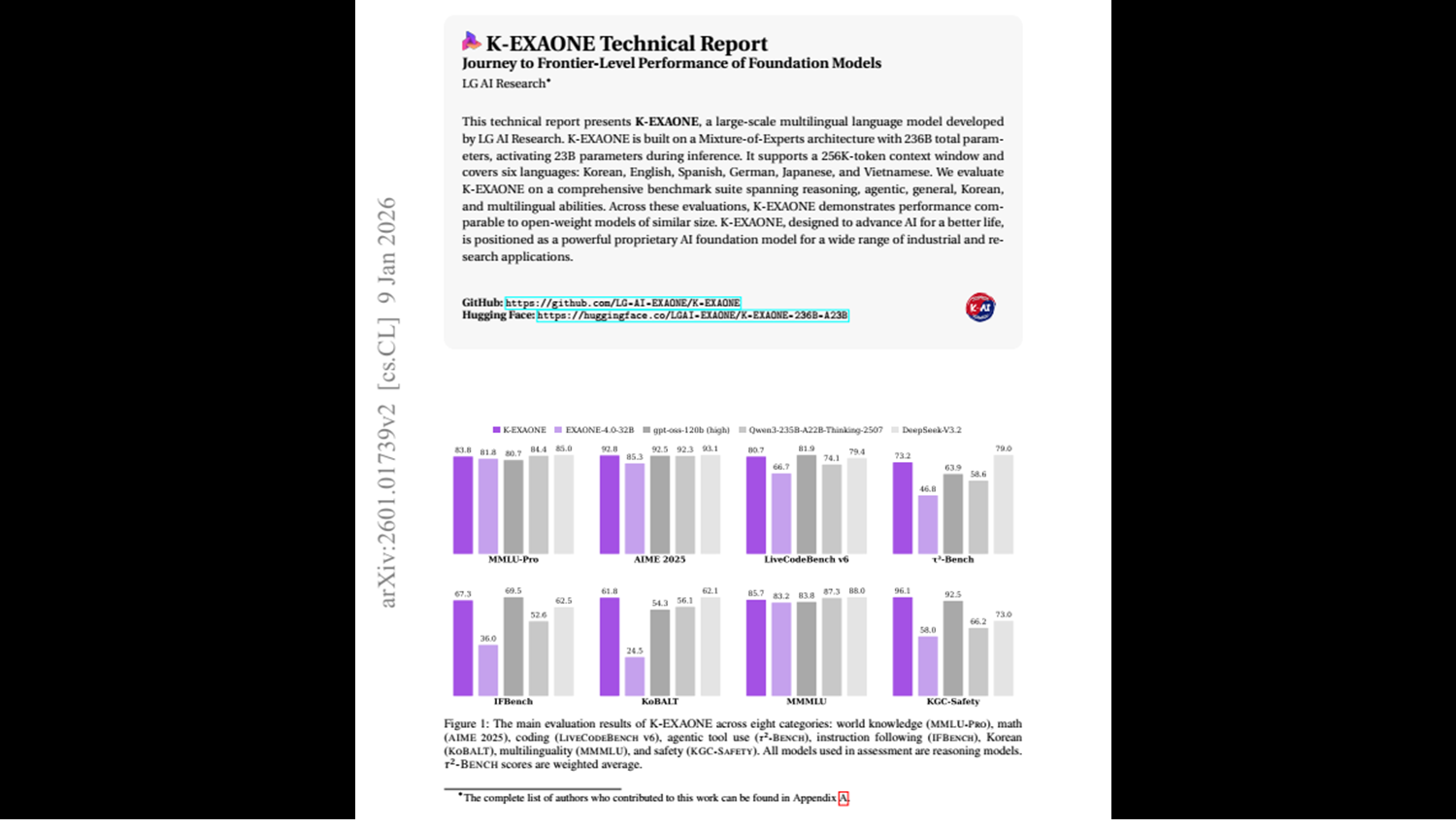
[Paper Review] K-EXAONE Technical Report
글로벌 대규모 언어 모델(LLM) 개발 경쟁이 치열해지고 있습니다. LG AI Research에서 새롭게 발표한 K-EXAONE에 대해서 살펴보겠습니다.
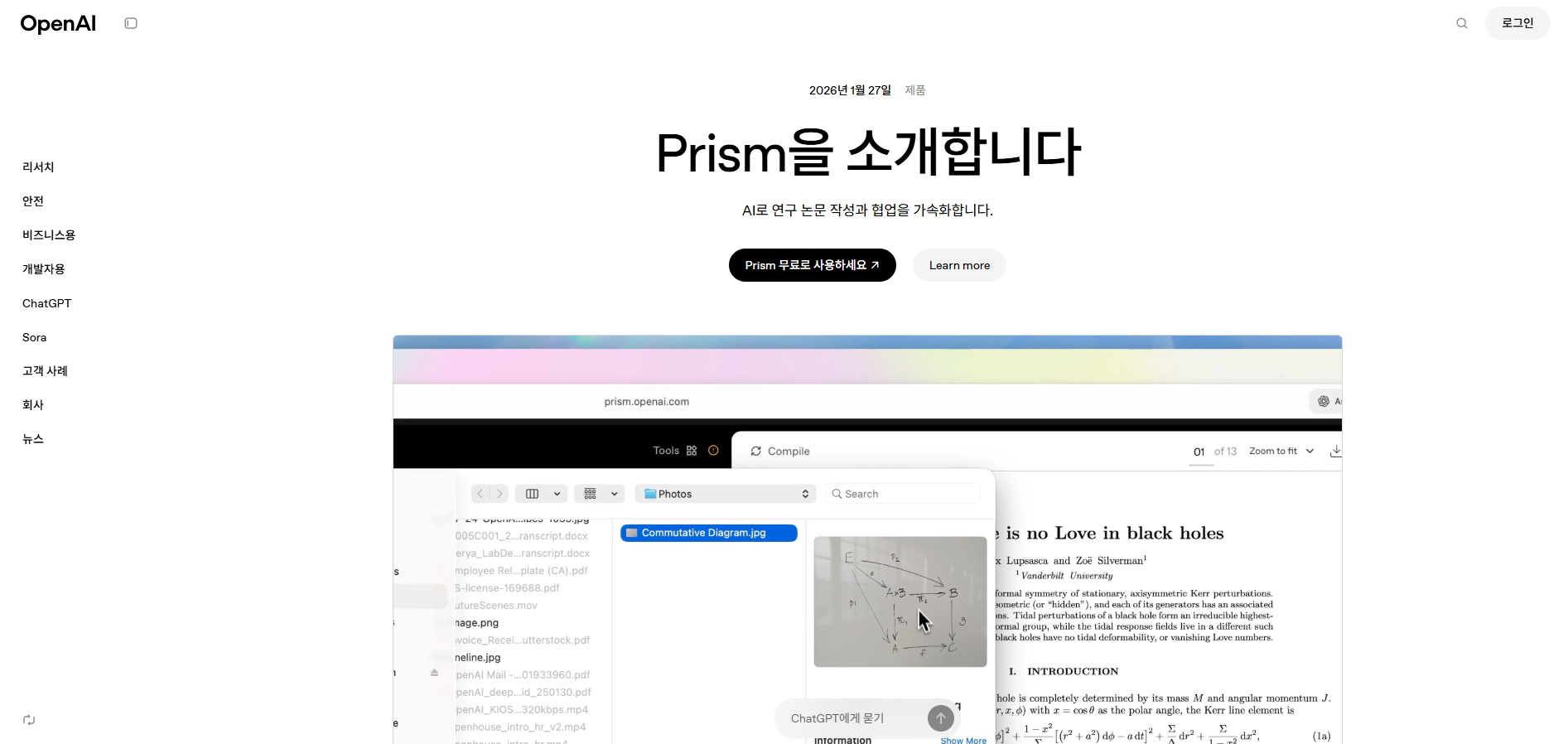
[OpenAI] Prism: GPT-5.2 기반 과학 논문 작성을 위한 무료 AI 워크스페이스
AI는 빠르게 발전해 왔지만, 정작 과학 연구 현장에서 반복적으로 수행되는 많은 작업은 여전히 수십 년간 크게 달라지지 않은 도구에 의존하고 있습니다.

[OpenAI] Town Hall 요약: Sam Altman이 말하는 AI 시대의 미래
2024년, OpenAI는 개발자 및 빌더 커뮤니티와의 Town Hall을 통해 차세대 AI 도구의 방향성을 논의했습니다.

BCG AI Radar 2026: CEO가 AI 투자의 중심에 서다
2026년 기업 AI 투자가 급증하면서, CEO들이 직접 AI 전략의 주도권을 쥐고 있습니다.

BCG AI Radar 2025: AI Impact Gap 해소를 위한 전략 보고서
BCG(Boston Consulting Group)가 2025년 1월 발표한 AI Radar 보고서는 전 세계 1,803명의 C-level 경영진을 대상으로 한 설문조사를 기반으로 합니다.

[OpenAI] GPT-5.2 프롬프팅 가이드: 엔터프라이즈 AI 에이전트를 위한 최적화 전략
OpenAI의 GPT-5.2는 엔터프라이즈 환경과 에이전트 워크플로우를 위해 설계된 최신 플래그십 모델입니다.

[OpenAI] : OpenAI 최신 프런티어 모델 GPT-5.2 출시
OpenAI가 전문 지식 업무에서 가장 뛰어난 성능을 제공하는 새로운 모델 시리즈 <GPT-5.2>를 공개했습니다.

[CS50] CS50x 2026 - Lecture 0 - Scratch
Harvard CS50: Introduction to Computer Science (https://cs50.harvard.edu/)

[CES] CES 2026 젠슨 황 기조연설 정리
NVIDIA는 AI 연산 수요 폭증에 대응하기 위해 Vera Rubin GPU를 양산하고, Cosmos/Alpamayo로 Physical AI 시대를 열며, 반도체부터 제조까지 전 산업에 AI를 통합하는 Full Stack 전략을 추진하고 있습니다.

[토크] LLM 완벽 입문 가이드: Andrej Karpathy 강의 정리
원본 강의: Intro to Large Language Models - Andrej Karpathy

AI 에이전트의 핵심 개념 20가지: 문제와 해결책으로 배우는 실전 가이드
AI 에이전트는 단순한 챗봇을 넘어 복잡한 작업을 자율적으로 수행하는 시스템으로 진화하고 있습니다. 하지만 이 과정에서 수많은 기술적 도전과제들이 존재합니다.

[Paper Review] LLaVA-PruMerge: Adaptive Token Reduction for Efficient Large Multimodal Models
제목: LLaVA-PruMerge: Adaptive Token Reduction for Efficient Large Multimodal Models저자: Yuzhang Shang, Mu Cai, Bingxin Xu, Yong Jae Lee, Yan Yan소속: Illi

[Paper Review] LLaVA: Visual Instruction Tuning - 멀티모달 AI의 새로운 패러다임
제목: Visual Instruction Tuning / 저자: Haotian Liu, Chunyuan Li, Qingyang Wu, Yong Jae Lee / 소속: University of Wisconsin–Madison, Microsoft Research