
- 전체보기(42)
- hadoop(12)
- spark(9)
- 용어 정리(3)
- battleground(3)
- aws(3)
- ec2(3)
- 장고(3)
- CentOS7(3)
- 인스턴스(2)
- Virtual Box(2)
- docker(2)
- virtualbox(2)
- CNN(2)
- 머신러닝(2)
- sql(2)
- 도커(2)
- ubuntu(2)
- hive(2)
- MapReduce(2)
- airflow(2)
- Gateway(1)
- 자료구조(1)
- ORM(1)
- 웹페이지(1)
- crontab(1)
- 사이킷런(1)
- queue(1)
- 이미지 크롤링(1)
- WHERE(1)
- django(1)
- 코딩테스트(1)
- 텐서(1)
- volume(1)
- url(1)
- templates(1)
- 스칼라(1)
- 11047번(1)
- centos(1)
- 스케줄링(1)
- GCP(1)
- FTP(1)
- 프라이빗 속성(1)
- 언더스코어(1)
- JOIN(1)
- 웹(1)
- 매트릭스(1)
- ecs(1)
- class(1)
- dropout(1)
- 전이학습(1)
- 시그모이드(1)
- 순환 신경망(1)
- 쿠버네티스(1)
- 모델링(1)
- VGG-16(1)
- -volume -from(1)
- 코테(1)
- LIT(1)
- 단어 임베딩(1)
- 조인(1)
- select(1)
- CASE문(1)
- cd(1)
- ReLU(1)
- mysql(1)
- PriorityQueue(1)
- html(1)
- @property(1)
- 스태틱메서드(1)
- 벡터(1)
- 볼륨(1)
- -v(1)
- Tanh(1)
- 랜덤포레스트(1)
- 의사결정나무(1)
- 클래스(1)
- filezilla(1)
- getter(1)
- setter(1)
- vagrant(1)
- 백준(1)
- 용어정리(1)
- RNN(1)
- 그리디 알고리즘(1)
- pyspark(1)
- 리눅스(1)
- GBM(1)
- 더블언더스코어(1)
- vpc(1)
- 데브옵스(1)
- parquet(1)
- WSL(1)
- wordcount(1)
- 보팅(1)
- 앙상블(1)
- Pseudo Code(1)
- ci(1)
- slack(1)
- 배깅(1)
- 서브쿼리(1)
- ORDER BY(1)
- 클래스메서드(1)
- graphviz(1)
- 선형대수(1)
- BigQuery(1)
[8월 미니프로젝트] Spark 사용해보기 - 2
쇼핑몰 데이터 EDA > 캐글에서 가지고 온 쇼핑몰 로그 데이터(8,9월 자료)를 병합하여 탐색한 내용 데이터 합치기 스파크 세션을 띄우고 스키마를 자동으로 설정하게 하고, 헤더가 있는 자료라는 옵션을 주어 불러왔다. 이후 union을 이용하여 합쳤다. union - 데이터를 합치고 중복된 행을 제거 unionAll - 데이터를 합치고 중복된 행을 유...
[7월프로젝트] 하둡 클러스터 사용하기- Spark
노트북 8대를 이용하여 클러스터를 구축 >openVPN을 통해 학원IP가 아니더라도 연결하여 작업을 수행할 수 있게 만들어 주었다. Spark 클러스터 모드로 데이터 전처리 하기 df.printSchema()을 확인해보니 아래와 같이 되어있었다. 총 322656건이 자료가 조회됐다. > 매치 데이터
[7월프로젝트] 3. 데이터 분석하기(2)
완성 화면 > 데이터 분석 과정 무기 상성과 무기 티어표 1. 무기 상성 > 개인전의 경우 killerweapon과 finisherweapon이 같아 문제가 없었지만, 다인전(듀오나 스쿼드) 의 경우 교전한 데이터인 killerweapon과 마지막 한발만을 친(막타) finsiherweapon에 차이가 있었다. 게임 내에서 교전 시에 승률을 알고 싶었...
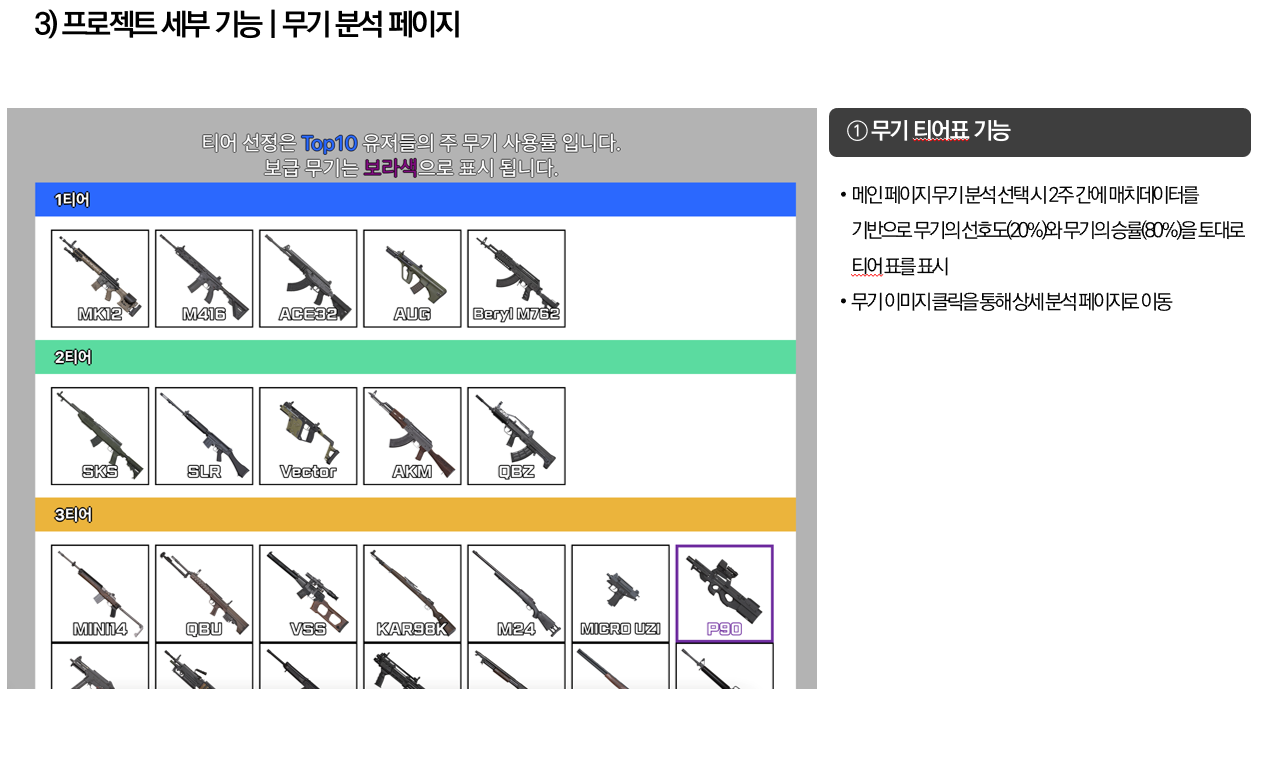
[7월프로젝트] 2. 데이터 분석하기
무기 데이터 분석하기 > 나는 이 프로젝트에서 무기 데이터 부분을 맡았다. RAW DATA에서 무기 데이터 관련만 파싱하는 코드, 그 데이터를 가지고 무기 티어, 무기 별 상성을 최신화 하는 airflow dag 코드를 작성했다. 완성 화면 과정 > 앞서서 유저 정보 페이지에서 유저가 가장 많이 사용하는 숙련도 top3을 보여주어 자신이 가장 잘 다...
[7월프로젝트] 1. 데이터 가져오기
7월 프로젝트로 진행하였던 배틀그라운드 API를 활용한 사이트(pd.gg)에 웹 기능 구상도 내가 주로 다루었던 페이지는 빨간색으로 표시한 무기 분석 페이지다. 필요한 데이터 파싱하기 배틀그라운드 개발자 센터 유저 정보 페이지에서 본인의 무기 숙련도 Top3을 보여줄 때 사용 유저 간 전투 데이터 > **무기
[8월 미니프로젝트] Spark 사용해보기
쇼핑몰 로그 데이터 분석해보기 >8대로 구성된 하둡, 스파크 클러스터를 활용하여 데이터 분석 흐름도 (예상안) 데이터셋 - (eCommerce behavior data from multi category store) 데이터셋 구조  - Spark
이전 포스트에서 다뤘던 spark 세션을 띄우고자 했지만, 실패한 것에 해결에 대한 기록 pyspark --master yarn --num-executors 5 명령어를 이용하여 YARN으로 PySpark를 실행하였지만, 이건 pyspark kernel이 아니라 Python 3 이었다. 단일 노드에서 spark를 사용하는 로컬 세션을 생성했던 것이었다...
[7월프로젝트] airflow 알림 메시지 보내기 - slack
slack_sdk를 활용하여 airflow 알리미 만들기 > 목표 : 프로젝트 중 무기 데이터의 집계를 하기 위한 데이터를 주기적으로 받아 GCP 스토리지에 저장해야 하는 작업이 필요했다. Raw Data를 받아와 우리가 사용할 데이터로 전처리하고 파싱하는 dag를 짰고, 이것이 잘 수행 중인지에 대해 slack bot을 통해 알림을 받고자 한다. 봇 만...
[7월프로젝트]하둡 클러스터 구축하기 (2) - Spark
Spark 설치 후 SparkSession 띄우기 이전에 작성했던 걸 보고 client에서 PySpark를 설치했다. 설치 후 datanode1~5에 spark 파일을 복사하였다. Spark 설치하기 <- spark_encore.tar.gz로 압축하여 각 노드에 ssh로 접속 후 압축 해제하는 과정을 진행했다. scp ./spark_encore.tar....
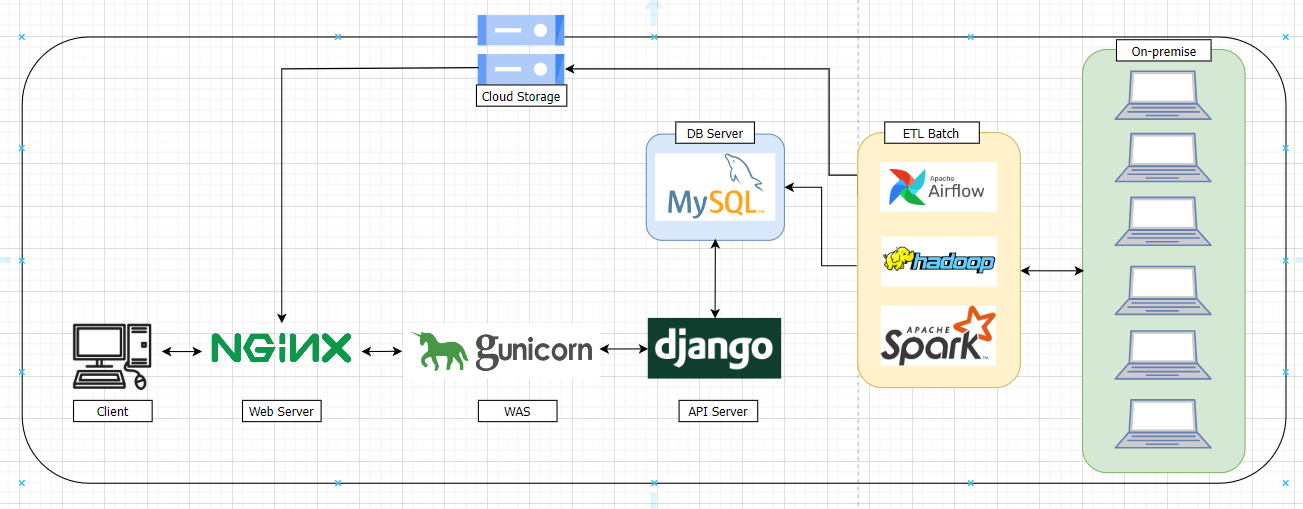
[7월프로젝트]하둡 클러스터 구축하기 (1)
개요 윈도우 8대 노트북을 우분투 22.04 LTS를 이용하여 각각의 서버로 만들어 하둡 구성하기 최종 프로젝트를 준비하던 중 데이터가 많아 결과를 보기까지가 오래걸려 분산처리를 한다면 얼마나 시간을 단축할 수 있을까?에 대한 생각으로 온프레미스 환경으로 노트북 8대를 연결하여 Hadoop 클러스터를 구성하였다. 데이터를 HDFS에 밀어넣어 PySpark를...
[Spark] 사용해보기 - 실습예제
스파크 세션 열기 > 스키마는 DataFrame의 컬럼명과 데이터 타입을 정의 CSV나 JSON 같은 일반 텍스트 파일을 사용하면 다소 느릴 수 있음 하지만 Long 데이터 타입을 Integer 데이터 타입으로 잘못 인식하는 등 정밀도 문제가 발생할 수 있음 따라서 운영 환경에서 추출, 변환, 적재를 수행하는 ETL 작업에 스파크를 사용한다면 직접 스키마...
[Spark] 사용해보기 - DB와 데이터 주고 받기
VirtualBox 실행 > VirtualBox를 켜서 가상머신 4개 창을 계속 띄우니 화면이 복잡함 bat파일을 통해 창을 백그라운드에서 실행 > bat 파일이란? BAT 파일은 Batch 파일의 줄임말로, 윈도우 기반 컴퓨터에서 실행되는 스크립트 파일 이 파일 형식은 .bat 확장자를 가지며, 한 개 이상의 명령어를 포함하여 일련의 작업을 자동화할 ...
[Vagrant] Vagrantfile로 가상머신 만들기(간단)
Vagrant란? 가상화(Virtualization)는 실제 운영체제 위에 가상화 소프트웨어를 설치한 후에 소프트웨어를 통해 하드웨어(CPU, Memory, Disk, NIC 등)를 에뮬레이션한 후에 이 위에 운영체제(Guest OS)를 설치하는 것을 의미합니다. 가상화를 해 주는 소프트웨어를 하이퍼바이저(Hypervisor) 라고 하며 종류로는 이 책에...
[Hadoop] 로컬 환경에서 만들어보기(2) feat.Virtual Box
host 이름 변경 hostnamectl set-hostname client clinet로 이름 변경 sestatus 운영체제 보안 설정 확인 sudo sed -i 's/^SELINUX=enforcing$/SELINUX=permissive/' /etc/selinux/config > chatGPT 명령어정리 sudo: 명령어를 관리자 권한으로 실행하...
[Hadoop] 로컬 환경에서 만들어보기(1) feat.Virtual Box
Virtual Box 설치 >실행 시 오류 메세지를 보고 설치 c++ 2019 redistributable 검색 후 파일 다운받기 CentOS 설치
[Spark] 사용해보기(2)
준비 putty 접속 순서대로 실행 su hadoop start_dfs start_yarn start_mr Spark 실행 nohup pyspark --master yarn --num-executors 3 & 웹사이트에 client:8888로 접속 (client가 탄력적 ip가 아니라면 ec2에서 퍼블릭 Ipv4 주소 복사후 :8888 해주기 주피터 ...
[Spark] Spark 사용해보기
Spark 설치 wget https://dlcdn.apache.org/spark/spark-3.2.4/spark-3.2.4-bin-hadoop3.2.tgz 해서 다운로드 받기 tar xzf spark-3.2.4-bin-hadoop3.2.tgz 압축 해제 mv ./spark-3.2.4-bin-hadoop3.2 ./spark 이름 바꾸기 conf 파일 ...
[Hive] 사용해보기
Hive 예제 사용해보기 (영화 크롤링 파일) > Hive를 이용하여 영화 크롤링 파일 mapreduce 해보기 hadoop 유저 접속 제공해준 파일 tmdb.zip 파일 받기 clinet 에서 실행 unzip 설치 잘들어갔는지 확인 (namenode:500
[Hadoop] 하둡 WordCount(예제)
Hadoop에서 wordcount 하기 putty 접속 후 hdfs에 새로운 폴더 생성 hdfs에 데이터 넣기 Hadoop Cluster에서 텍스트 파일 검색하기 Hadoop MapReduce의 예제 중 하나인 grep 실행 하둡 클러스터에서 텍스트 파일을 검색 >/mydata 경로에 있는 텍스트 파일을 dfs[a-z.]+라는 문법 (dfs가 들어...
[Hadoop] 하둡 설정하기(2)
저장소 지정(workers) 하기 datanode1, datanode2, datanode3 입력 workers 파일 복사(scp 사용법) 다른 서버끼리 미리 ssh 연결되어 있어야 scp 명령어 사용 가능 이 작업을 완료하면 worker 노드를 식별하고 클러스터의 구성을 설정, 작업 분산을 할 수 있음 하둡 서버의 resource map ec2 보...