

인공지능 예술가 달리2(DALL-E2)로 그림 그리기
그림 그려주는 인공지능 달리는 지난 2021년 1월 OpenAI에서 공개한 인공지능 시스템으로, 자연어로 그림을 묘사하면 그대로 그려주는 기능을 합니다. 올해는 훨씬 더 정확하고 해상도 높은 이미지를 생성하는 달리2를 공개했죠.

스포티파이 API로 음악 분석하기
여느때처럼 미디엄을 살펴보다가 발견한 [재미있는 분석] (https://medium.com/dev-genius/spotify-data-analysis-with-python-a727542beaa7)을 보고 따라해보기로 했습니다.

[빅분기] 빅데이터 분석 기사 공부기 (필기)
바로 어제 빅데이터 분석 기사 필기 예비 결과가 나왔습니다! 정식 결과는 29일 나오지만, 오늘 결과를 보고 이의 접수 기간을 가진다고 하네요.

[네트워크 분석] 할리우드 배우들의 네트워크를 알아보자
오늘은 imdb 영화 관련 데이터를 통해 같은 작품에 출연한 배우들의 네트워크를 만들어보고, 서로 다 연결이 되어 있는지, 누가 가장 인싸일지 보도록 하겠습니다.

트위터 스크래핑 라이브러리 twint 사용법
트위터를 스크래핑 하는 다양한 방법 중 가장 적법한 방법은 트위터 API를 사용하는 것입니다. 하지만 트위터 API에는 여러 한계가 존재합니다.

넷플릭스 데이터를 분석하자
지난번에 넷플릭스에서 어떤 데이터를 수집하고 제공하는지 알아봤었는데요, 저에 대해 많은 데이터를 수집한다는 것에 흠칫한 한편, 그걸 제가 다운로드 받을 수 있게끔 한 점은 흡족했습니다. 그럼 넷플릭스에서 줬으니까 제 데이터를 한번 잘 써보겠습니다!

넷플릭스에서는 어떤 데이터를 수집할까?
넷플릭스는 콘텐츠 서비스이기도 하지만 테크 기업의 이미지도 있습니다. 데이터를 굉장히 잘 활용하고 추천 알고리즘에 공을 들이는 것으로 알려져 있죠. 그래서 과연 넷플릭스에서는 데이터를 얼마나 수집하는지 궁금하기도 합니다.

[BERT] KeyBert로 리뷰 키워드 추출하기
BERT는 2018년에 자연어 처리를 위해 구글에서 고안한 트랜스포머 기반의 머신러닝 기법입니다. BERT의 가장 큰 특징은 문장 전체의 구조를 양방향으로 학습하여 문맥을 파악할 수 있다는 것입니다.
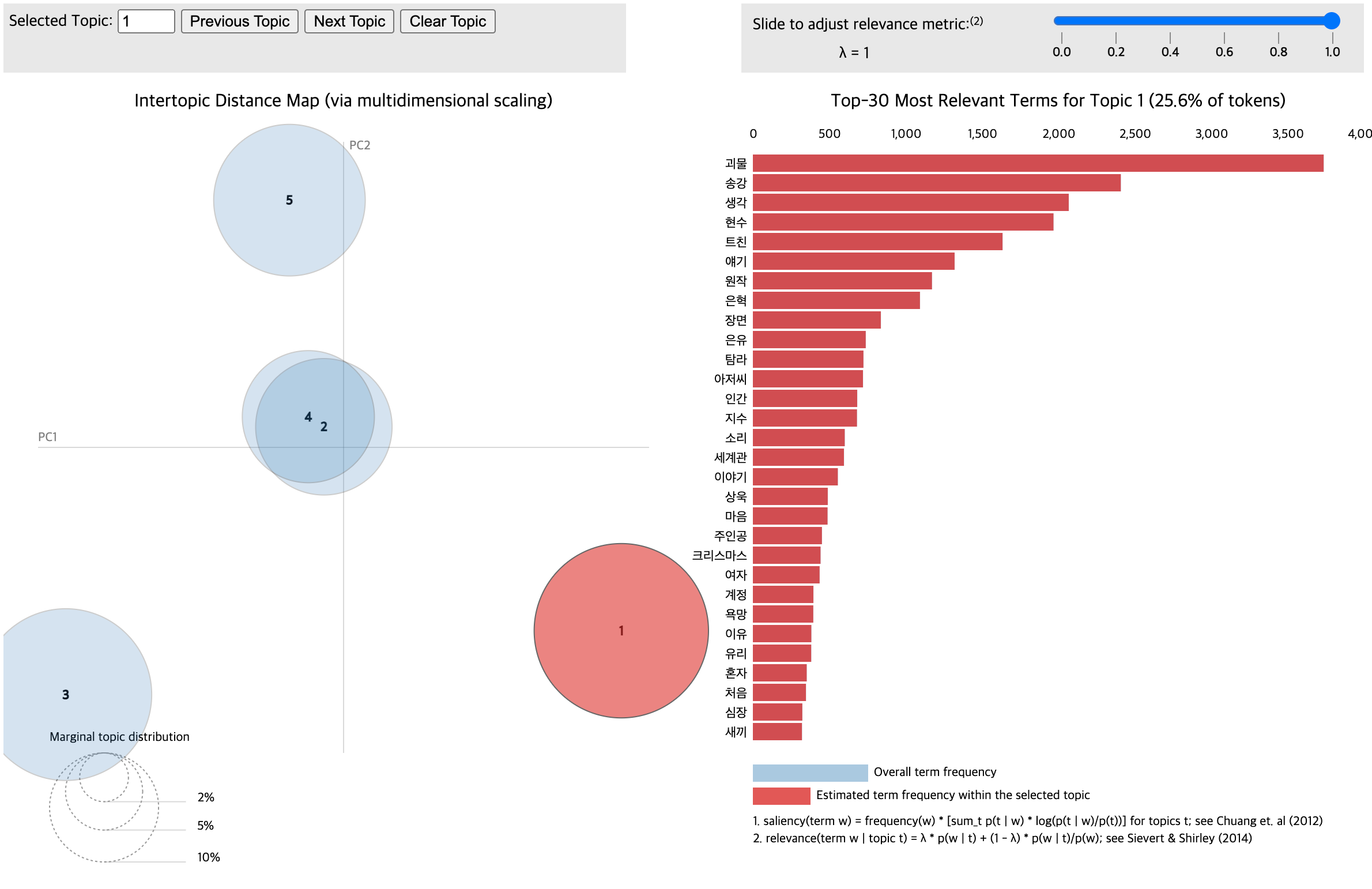
LDA 토픽 모델링으로 콘텐츠 리뷰를 분석하자
LDA 토픽 모델링은 다른 분석들 보다도 어떤 주제에 대해 여론이 형성되었지 확인하기 편리해서 특히 연구를 시작하는 단계에서 한번 해볼만한 분석이죠. 물론 토픽모델링 자체로도 하나의 연구가 될 수 있고요!

영화, 책을 부활시키다
앞에서는 원작의 힘을 알아봤다면 이번엔 반대로 영화화의 힘을 알아볼 차례입니다. 한국에서는 이른바 "스크린셀러"라는 말이 등장할 정도로 영화로 인해 베스트셀러가 된 책들도 많은데요, 영화의 흥행은 과연 원작에 어떤 영향을 줄 수 있을까요? 이번에는 두가지 연구문제를 함

원작이 인기있으면 영화도 흥행할까?
지난 편에서는 원작이 있는 영화는 관객 수가 더 많다는 결과를 얻었습니다. 그렇다면 원작의 인기와 영화의 흥행도 상관이 있을까요? 이번에는 원작이 본래 가진 힘에 더 집중해보도록 하겠습니다. ✏️ 연구 문제 원작 도서가 있는 영화는 그렇지 않은 영화보다 더 흥행할까?

원작이 있는 영화는 더 흥행할까?
분석에 들어가기 전에 연구문제를 다시 정립해보도록 하겠습니다. 이번 편에서 알고싶은 것은 원작, 그 중에서도 책이 영화화에 끼치는 영향이므로, 첫번째 연구문제는 "원작 도서가 있는 영화는 그렇지 않은 영화보다 더 흥행할까?"입니다. ✏️ 연구문제 원작 도서가 있는 영
.jpeg)
할리우드에는 책 스카우트 팀이 있다고?
<반지의 제왕>과 <해리 포터> 같은 장대한 판타지부터 설렘 치사량의 <콜 미 바이 유어 네임>, <내가 사랑했던 모든 남자들에게>, 그리고 진한 감동을 선사하는 <라이프 오브 파이>, <원더>에 이르기까지, 우리가 사랑한 영화들 중에는