
[RL] TD-Learning(n-step, backward TD(lambda) 구현
전통적인 강화학습 분야에서 model-free(MDP를 모르는 상황) 즉 전이확률과 보상함수에 대한 정보가 없을 때 Monte carlo, TD-Learning(temporal diffrence learning)을 사용한다. 해당 포스트는 TD-learning 기법
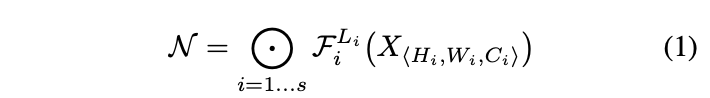
EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks
Is there a principled method to scale up ConvNets that can achieve better accuracy and efficiency?이전 연구에서는 depth(layer), width(channel), image size 중
Deep Residual Learning for Image Recognition(ResNet)
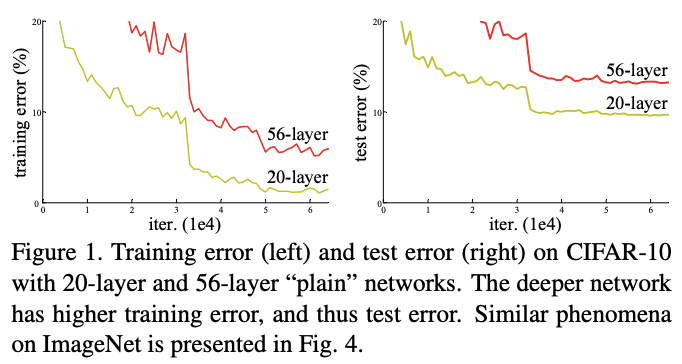
Deep convolutional neural networks는 층이 깊어질 수록 feature의 추상화 정도?가 올라감 → 즉 층이 깊어질 수록 다양한 이미지 표현가능기존의 vgg-net을 이용해서 층을 깊게 쌓았을 때의 figure층을 깊게 쌓았을 때 성능 저하가
[논문리뷰]Efficient Estimation of Word Representations in Vector Space
1. Introduction 해당 연구 당시 많은 NLP연구가 단어를 atomic units으로 여겼다.(단어간 유사성 개념이 없음) 이런 방법은 복잡한 모델로 작은 양의 데이터를 학습시키는 것보다 간단한 모델로 많은 양의 데이터를 학습시키는 것이 성능이 더 좋다는 것
[논문리뷰] SEMI-SUPERVISED CLASSIFICATION WITH GRAPH CONVOLUTIONAL NETWORKS
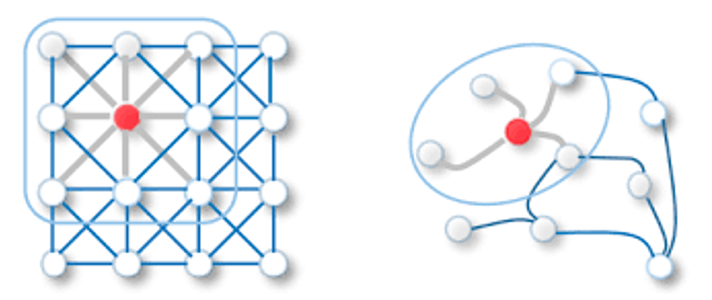
Background 1. Graph란? 점들과 그 점들을 잇는 선으로 이루어진 데이터 구조이다.위그림과 같이 사람과 사람간의 관곌르 나타내거나, paper들 사이의 관계 3D model에서 mash들 사이의 관계 분자 구조를 나타낼 때 graph 데이터가 사용될 수
[논문리뷰] ELECTRA: PRE-TRAINING TEXT ENCODERS AS DISCRIMINATORS RATHER THAN GENERATORS
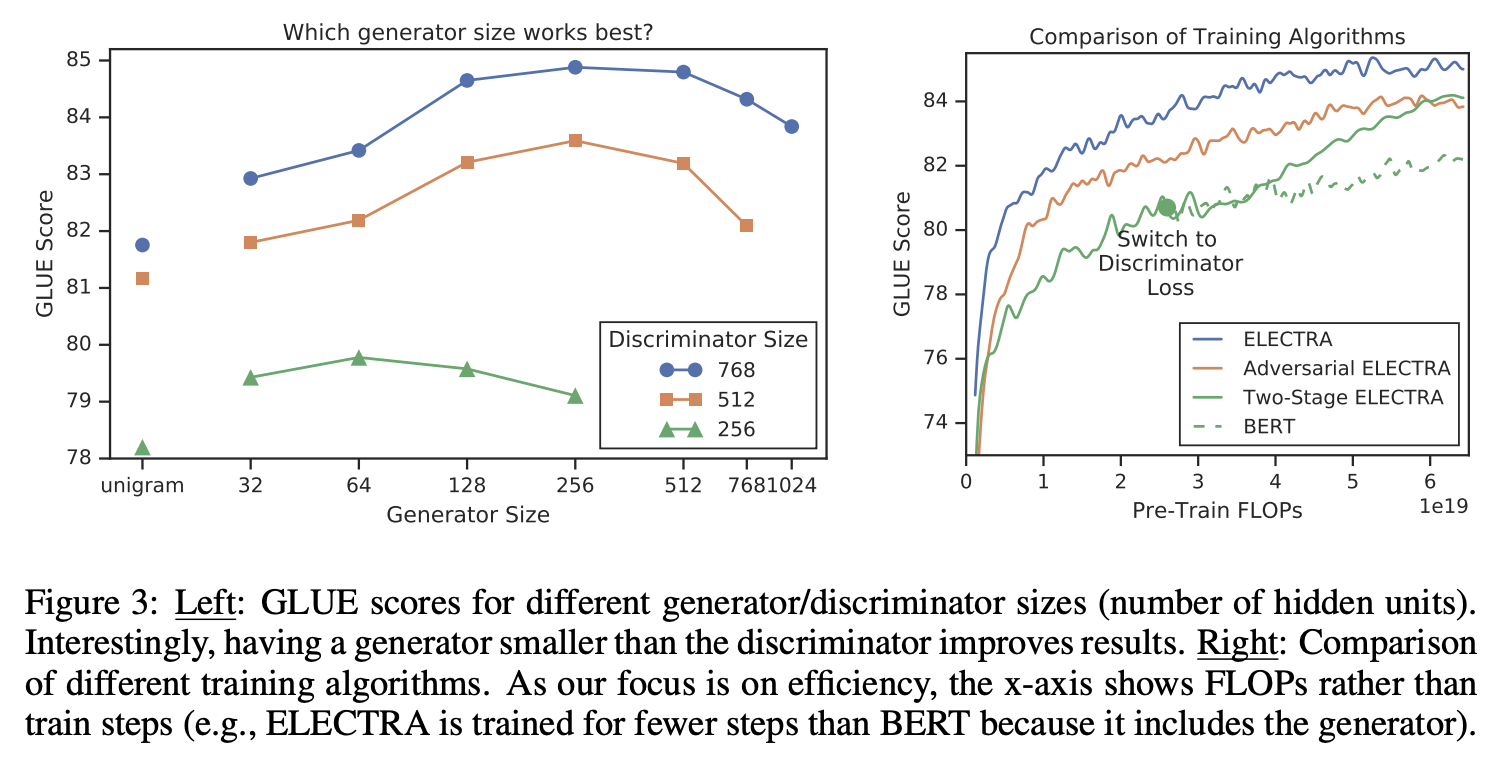
1. Introduction 당시 SOTA representation learning 방법은 일종의 denoising autoencoder 방법이다. 입력 시퀀스의 토큰중 대략 15%를 마스킹하여 복원하는 모델링을 MLM(masked language modeling)이
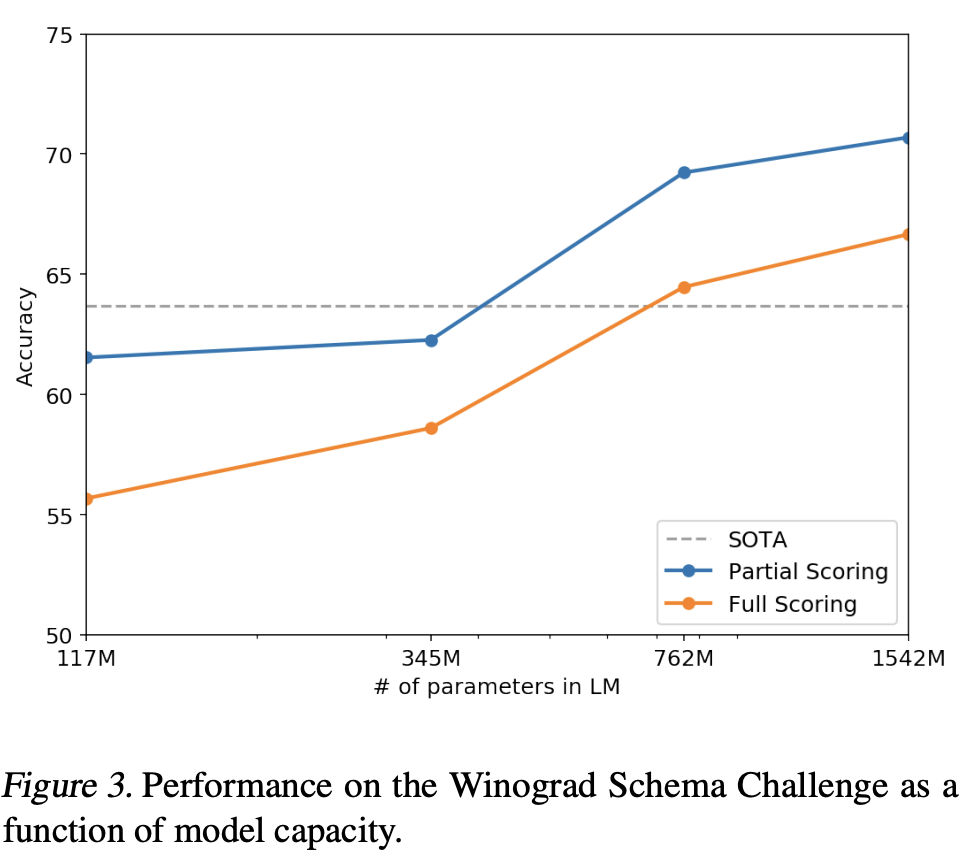
[논문리뷰] Language Models are Unsupervised Multitask Learners
1. Introduction 각 task마다 라벨링하는 작업 수고 없이 많은 task에서 잘 수행하는 general 모델을 만들고자 함 2. Approach GPT-2의 핵심 접근법은 language modeling이다. language modeling은 입력 $$
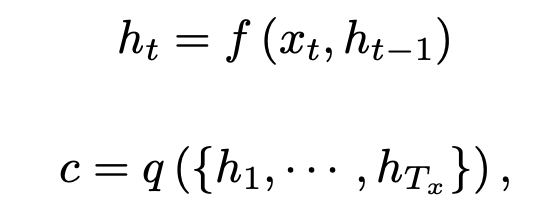

[강화학습] Balancing immediate and long-term goals
Agent의 목표는 에피소드나 특정 task를 수행하는 동안 return을 최대화하는 sequence of actions을 찾는 것.return = $G_t$$$Gt = R{t+1} + R{t+2} + R{t+3} +... + R_T$$할인율 $\\gamma$가 적용
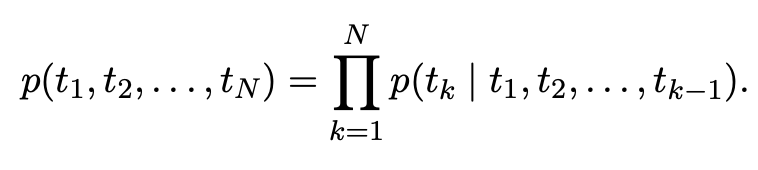
[논문리뷰]Deep contextualized word representations(ELMo)
단어의 복잡한 특성언어학적인 문맥 상에서 다르게 사용될 때 각 문맥에서의 맞는 representation이 필요하다(Ex 다의어)전체 문장을 input으로 받아 word representations을 만든다bidrectional LSTM을 활용하여 language mo
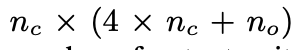
[논문리뷰] Long Short-Term Memory Recurrent Neural Network Architectures for Large Scale Acoustic Modeling
Abstract 1. LSTM은 RNN 계열의 모델중 하나로 기존 RNN보다 temporal sequences, long-range dependecies에서 성능을 개선했다. temporal sequences: 시간에 따라 변하는 데이터의 순서 ex) 음성신호,