
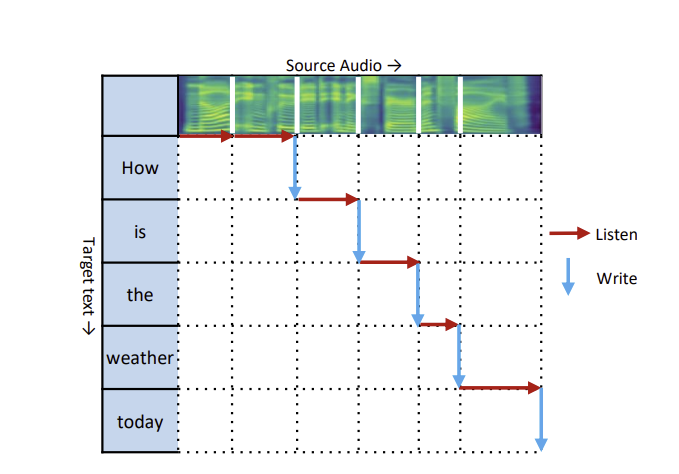
[논문 리뷰] SimulSpeech: End-to-End Simultaneous Speech to Text Translation
SimulSpeech: End-to-End Simultaneous Speech to Text Translation(https://aclanthology.org/2020.acl-main.350.pdf) 중간 단계를 없애고 음성에서 번역문을 직접 — 더 빠르고 더 정확한 동시 음성 번역 > 음성 인식 → 번역이라는 두 단계를 하나로 합치고, > CTC 분절기...
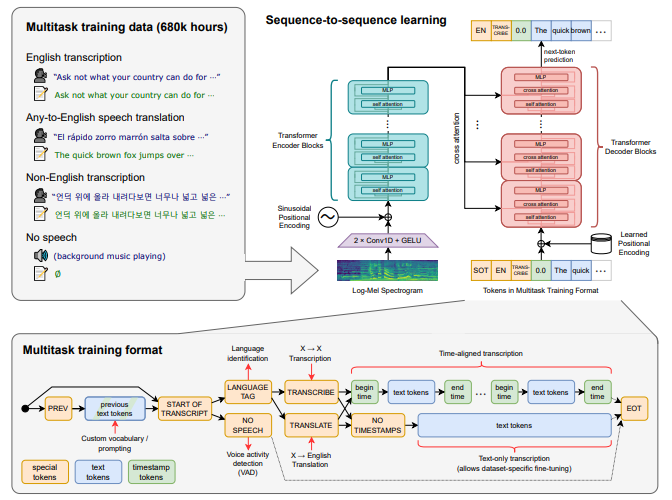
[논문 리뷰] Whisper: Robust Speech Recognition via Large-Scale Weak Supervision
Whisper: Robust Speech Recognition via Large-Scale Weak Supervision(https://arxiv.org/pdf/2212.04356) 680,000시간의 지저분한 인터넷 데이터로 만든 만능 음성 인식 — 추가 학습 없이 사람 수준에 도달하다 > 깨끗한 데이터 1,000시간 대신 지저분한 인터넷 데이터 68만...
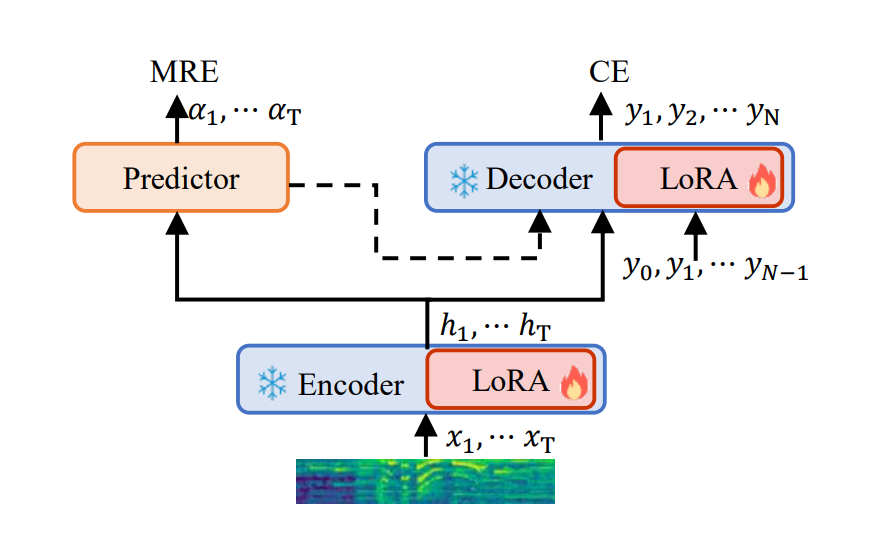
[논문 리뷰] Monotonic Finite Look-ahead Attention (MFLA)
Monotonic Finite Look-ahead Attention (MFLA) (https://arxiv.org/pdf/2506.03722) Whisper를 실시간으로 — 과거는 무한히, 미래는 딱 k개만 엿보는 스트리밍 음성 인식 > 훈련과 실전의 괴리를 CIF + MFLA + Wait-k 세 가지 조합으로 해결하여, > Whisper를 그대로 파인튜...
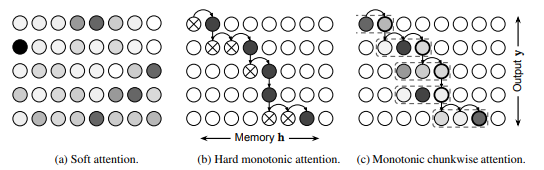
[논문 리뷰] Monotonic Chunkwise Attention (MoChA)
Monotonic Chunkwise Attention (MoChA) (https://arxiv.org/pdf/1712.05382) 실시간으로 달리면서 방금 지나온 길을 되돌아보는 어텐션 메커니즘 > 미래를 컨닝하지 않고 왼쪽에서 오른쪽으로만 진행하면서, > 멈춘 순간 바로 직전 2~8개를 묶어 소프트 어텐션으로 훑어보는 실시간 어텐션의 혁신. > ICLR...
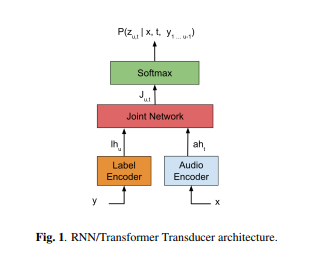
[논문 리뷰] Transformer Transducer
Transformer Transducer(https://arxiv.org/pdf/2002.02562) 트랜스포머의 똑똑함 + RNN-T의 실시간성 — 두 마리 토끼를 동시에 잡다 > RNN-T의 뼈대는 그대로 유지하면서 내부 엔진을 LSTM에서 Transformer로 교체하고, > 어텐션 마스킹으로 시야를 제한해 실시간 스트리밍까지 가능하게 만든 종단간 ...
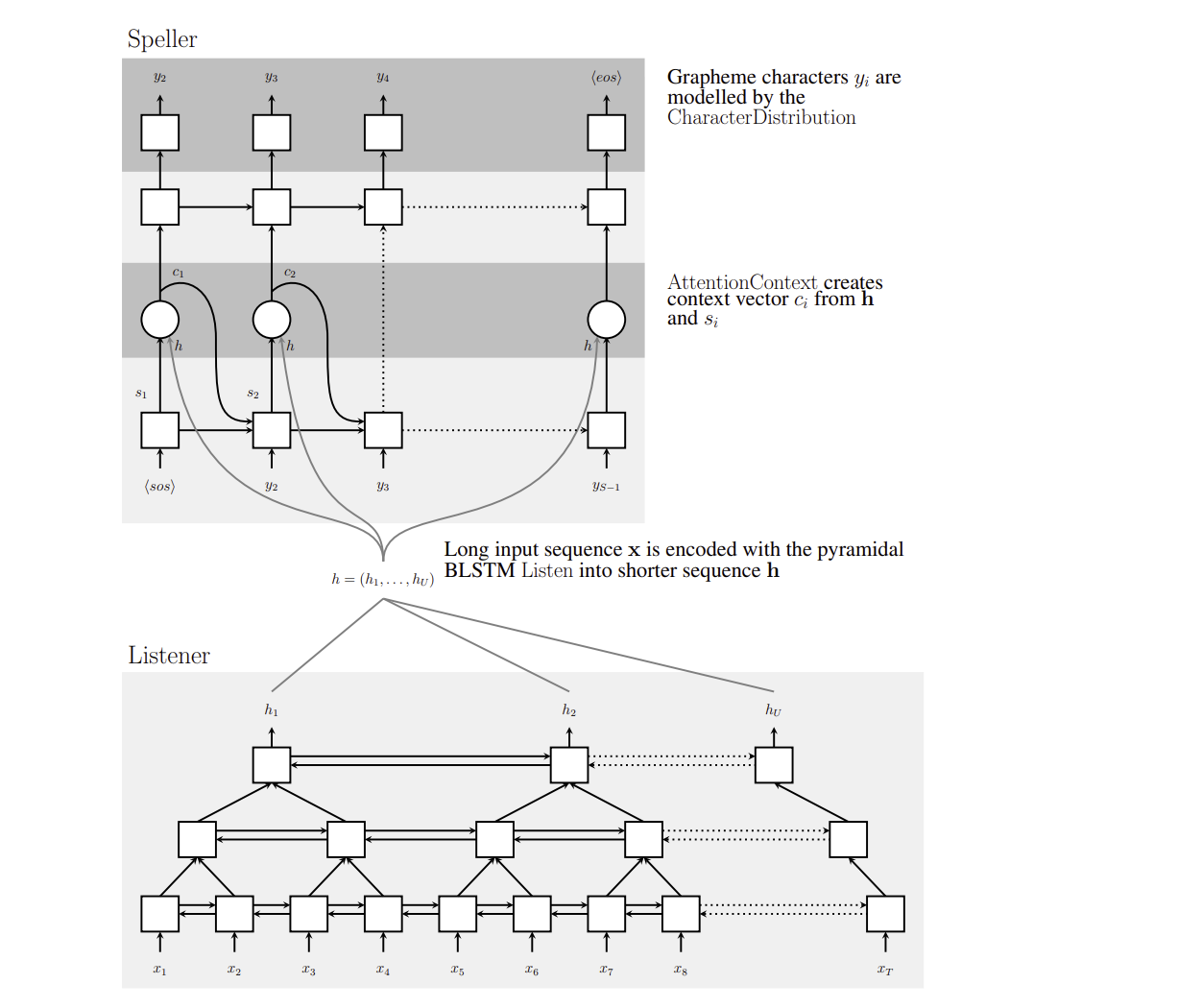
[논문 리뷰] Listen, Attend and Spell (LAS)
[논문 리뷰] Listen, Attend and Spell (LAS) (https://arxiv.org/pdf/1508.01211) 발음 사전 없이 소리를 문자로 번역하는 종단간 음성 인식의 탄생 > 수천 프레임의 오디오를 피라미드로 압축하고, 어텐션으로 한 글자씩 집중해서 읽어내는 > 단일 신경망 하나로 전통적 음성 인식 파이프라인 전체를 대체한 혁명적...
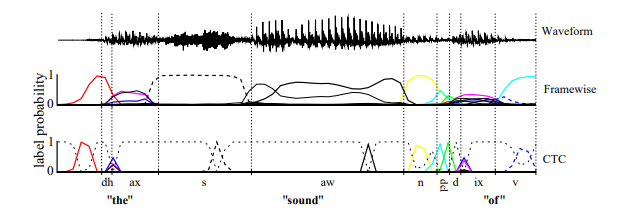
[논문 리뷰] Connectionist Temporal Classification (CTC)
Connectionist Temporal Classification (CTC) (https://www.cs.toronto.edu/~graves/icml_2006.pdf) 정답의 시간표 없이 스스로 학습하는 음성 인식의 혁명 > "안녕"을 0.5초에 말하든 2초에 말하든, 사람이 시간 짝을 맞춰주지 않아도 인공지능이 스스로 패턴을 찾아내는 수학적 마법. ...
Layer-wise Relevance Propagation (LRP) vs Backpropagation
― 둘 다 “역방향”인데 뭐가 다를까? 논문 리뷰(https://aclanthology.org/P19-1580.pdf)를 하며, LRP와 BackPropagation의 차이가 뭔지 너무 궁금하여 작성하게되었다. > LRP도 뒤로 전파하고, Backpropagati
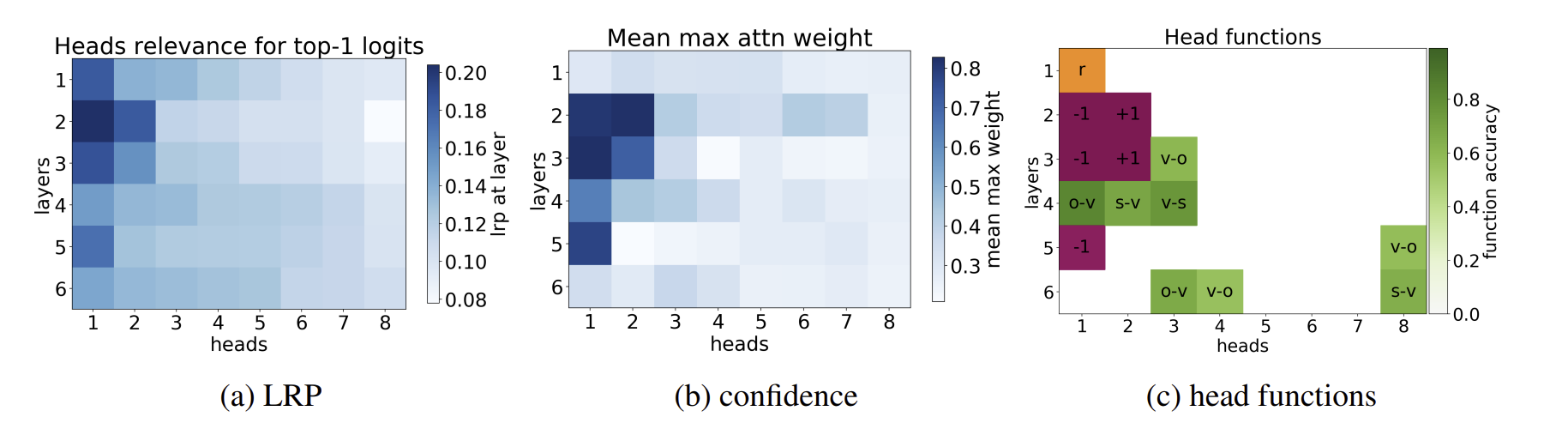
[논문 리뷰] Analyzing Multi-Head Self-Attention: Specialized Heads Do the Heavy Lifting, the Rest Can Be Pruned
Analyzing Multi-Head Self-Attention: Specialized Heads Do the Heavy Lifting, the Rest Can Be Pruned(https://aclanthology.org/P19-1580.pdf) 트랜스포머 속 엘리트
[논문 리뷰] Rethinking Attention with Performers
Rethinking Attention with Performers(https://arxiv.org/pdf/2009.14794) 메모리 폭발 없이 무한히 긴 문맥을 처리하는 트랜스포머 > 복잡한 어텐션 연산량을 선형 시간(Linear-Time)으로 확 줄이면서도 정보 손실이 전혀 없는 FAVOR+ 의 수학적 원리를 파헤쳐 봅니다. 목차 서론 Backg...
[논문 리뷰] Online and Linear-Time Attention by Enforcing Monotonic Alignments
온디바이스 실시간 AI를 위한 직진하는 어텐션 > 데이터를 끝까지 기다리지 않고, 한 방향으로 스캔하며 즉각 결과를 뱉어내는 단조 어텐션(Monotonic Attention) 을 파헤쳐 봅니다. (https://arxiv.org/pdf/1704.00784) 목차
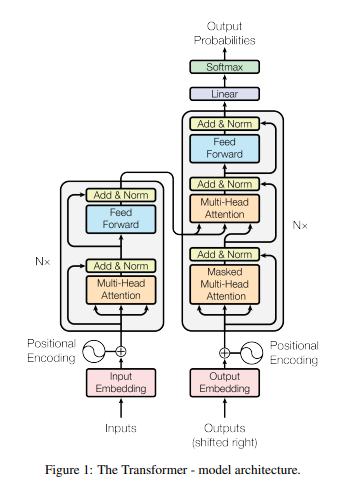
[논문 리뷰] Attention Is All You Need
최근 업무에서 RAG(검색 증강 생성) 시스템의 검색 성능을 높이는 작업을 하고 있습니다. 또한 다양한 거대 언어 모델(LLM)을 활용해 프롬프트를 최적화하는 일도 병행하고 있습니다. 이 과정에서 항상 비슷한 벽에 부딪혔습니다. "왜 모델은 입력 길이가 길어지면 앞부분
AWQ: Activation-aware Weight Quantization for LLM Compression and Acceleration
📝 AWQ: Activation-aware Weight Quantization for On-Device LLM Compression and Acceleration 한 줄 요약: 대규모 언어 모델(LLM)의 가중치를 4비트로 양자화할 때, 활성화(activation) 분포에 기반하여 중요한 가중치 채널을 보호함으로써 정확도 손실 없이 3배 이상의 추론 속...
KMMLU: 한국어 대형언어모델의 실전 시험지 – 45개 과목 35,030문항으로 본 한국어 이해력 벤치마크
🚀 도입: 이 논문을 주목해야 하는 이유 최근 MMLU(Massive Multitask Language Understanding) 같은 영어 기반 평가표준이 대형언어모델(LLM) 능력을 가늠하는 척도로 널리 쓰이고 있지만, 한국어·한국문화권 환경에서는 번역 기반 데
MobileLLM: Optimizing Sub‑billion Parameter Language Models for On‑Device Use Cases
🚀 도입: 이 논문을 주목해야 하는 이유 오늘날 대형 언어모델(LLM: Large Language Model)은 놀라운 성능을 보여주지만, 대부분이 클라우드 연산에 의존하고 있습니다. 그로 인해 지연(latency), 비용, 에너지 소비, 모바일·엣지 단말에서의
[개발공부] 싱글톤(Singleton) 과 추상 메서드(Abstract Method)
싱글톤: “프로그램에서 딱 1개만 있어야 하는 객체” 만들기. (설정/로거/커넥션 등) 추상 메서드: “자식이 반드시 구현해야 할 메서드” 강제(팀 규약 만들기). 파이썬은 모듈 전역 객체가 사실상 싱글톤처럼 동작. 필요하면 new+Lock, 또는 메타클래스로 확장. 1) 싱글톤: 진짜로 한 개만 만들기 1-1. 제일 쉬운 방법: 모듈 전역 객체 파이...
[Kaggle] Day-3. Child Mind Institute : EDA
이번 포스팅에서는 SII(Score Indicator Index)를 성별 및 나이대와 관련하여 분석한 과정을 정리합니다.데이터 전처리 및 탐색적 데이터 분석(EDA)에 사용한 방법과 코드를 함께 다룹니다.나이 데이터를 나이대(Age Group)로 변환하여 분석의 편의성
[HardWare] GPU 서버 필수 요소
이번에는 GPU 하드웨어와 학습 방식에 대해 간단히 정리해보았습니다. 아직 초기 단계라 구체적인 사양과 최적화 방법은 더 알아볼 계획이며, 추후 하드웨어 구성과 학습 전략도 세부적으로 정리할 예정입니다.현재 메인보드(마더보드)는 PCI 슬롯 4개를 사용하여 GPU 4장
[Kaggle] Day-2. Child Mind Institute : EDA
이번 EDA 과정에서는 PCIAT 데이터의 결측치 처리 및 SII 점수 재계산을 수행하였습니다. 이후 결과를 바탕으로 데이터의 이상값을 분석하고 시각화하는 과정까지 진행했습니다.결측치를 포함한 최대 점수를 계산하여 SII 카테고리를 재분류합니다.apply()를 통해 각
[Recommendation System] 추천시스템①
이번 게시물의 주제는 추천 시스템입니다. 😊추천 시스템은 특정 시점에 특정 고객에게 특정한 상품을 추천하는 시스템입니다.E-commerce, OTT 등 다양한 서비스에서 상품 구매 및 선호도에 대한 사용자의 피드백(예: 평점, 후기 등)을 바탕으로 아이템을 추천하는