
- 전체보기(97)
- python(39)
- data(10)
- 스터디(7)
- 데이터(7)
- basic(6)
- 기초(6)
- 논문(4)
- LDM(3)
- AI(3)
- ML(3)
- Stable Diffusion(3)
- 전처리(3)
- SVM(3)
- logit(2)
- 결과(2)
- 인공신경망(2)
- transformer(2)
- 라피신(2)
- 42서울(2)
- 이상치(2)
- 분석(2)
- 기초수학(2)
- NLP(2)
- opencv(2)
- ESTsoft(2)
- ANN(2)
- 응용(2)
- Experiments(2)
- CNN(2)
- DL(2)
- 알고리즘(2)
- 확률통계(1)
- 순차탐색(1)
- web(1)
- 일반화(1)
- 선택정렬(1)
- 컨퍼런스(1)
- Forge(1)
- sql(1)
- 거품정렬(1)
- 상관관계(1)
- Randomforest(1)
- 시간측정(1)
- absolute(1)
- 회귀함수(1)
- open(1)
- shell(1)
- Loss(1)
- 절대값(1)
- 원티드(1)
- merge(1)
- 멀티태스크(1)
- ROC(1)
- 집합자료형(1)
- stack(1)
- for문(1)
- image(1)
- heap(1)
- ViT(1)
- rag(1)
- 귀무가설(1)
- 데이터분석(1)
- 2번째(1)
- 자기소개글(1)
- 생성형 ai(1)
- 구글(1)
- 대용량데이터(1)
- 실험(1)
- Read(1)
- 미국(1)
- lake(1)
- 상관계수(1)
- Regression(1)
- mixed precision(1)
- KNN(1)
- unix(1)
- 차원 축소(1)
- 회귀모형(1)
- Data section(1)
- 가설(1)
- movingaverage(1)
- LSTM(1)
- 오르미(1)
- class(1)
- 비지도학습(1)
- 이미지변환(1)
- dropout(1)
- 사물인터넷(1)
- multi-head attention(1)
- 모형(1)
- 활성화함수(1)
- bootcamp(1)
- code section(1)
- 기계학습(1)
- Diffusers(1)
- Logitstic Regression(1)
- Outliers(1)
- 잡담(1)
- ols(1)
- CS(1)
- 제어문(1)
- triplet(1)
- Embedded(1)
- 첫시작(1)
- Attention(1)
- 단어(1)
- Stable Deffiusion(1)
- 최소자승법(1)
- tree(1)
- EST(1)
- 딥시크(1)
- 레버리지(1)
- 취업박람회(1)
- 콘솔입출력(1)
- 입출력(1)
- 대립가설(1)
- 함수(1)
- sqlite(1)
- 판별자(1)
- 회귀분석(1)
- if문(1)
- 교차검증(1)
- beck(1)
- 예외처리(1)
- 정수(1)
- 퀵정렬(1)
- ESTFamily(1)
- gamma(1)
- 심층학습(1)
- 로지스틱(1)
- 해외여행(1)
- self-attention(1)
- 인공지능(1)
- memory(1)
- C(1)
- 지도학습(1)
- 최대값(1)
- developers(1)
- 삽입정렬(1)
- R(1)
- 3기(1)
- 원핫인코딩(1)
- 합계(1)
- aws(1)
- 컴퍼런스(1)
- 스케일링(1)
- p-value(1)
- db(1)
- AMP(1)
- VISION(1)
- 선형탐색(1)
- 이진탐색(1)
- 여담(1)
- warehouse(1)
- multi-task(1)
- Database(1)
- 정렬(1)
- 결측값처리(1)
- triplet-loss(1)
- Latent(1)
- 탐색(1)
- 깃허브(1)
- 부트캠프(1)
- 파이썬(1)
- IoT(1)
- wassup(1)
- cost(1)
- 생성자(1)
- DEEPSEEK(1)
- gan(1)
- 파일입출력(1)
- google(1)
- CV(1)
- 기초통계(1)
- 자연수(1)
- 세미나(1)
- 최적화(1)
- 자동화(1)
- 팩토리얼(1)
- 9기(1)
- zero(1)
- 메모리(1)
- function(1)
- 정규표현식(1)
- 이미지 생성(1)
- 이동평균(1)
- 주성분 분석(1)
RAG를 활용한 DeepSeek 보강
https://github.com/electronicguy97/DeepSeek_Code(프로젝트 진행 중)
RAG 간단 리뷰
참고 자료논문(Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks)LangChainHayStackGitHub-Harrison ChaseRAG(Retrieval-Augmented Generation) 는 외
Absolute-Zero-Reasoner
Absolute Zero: Reinforced Self-play Reasoning with Zero Data Github 프로젝트 페이지 참고문헌 25년 3월에 Data 없이 AI에게 자기 합습 시키는 방법이 나와 다루어 보려고합니다. Absolute Zero 패러다
DeepSeek의 MLA (Multi-Head Latent Attention)
DeepSeek-V3에서 사용한 Multi-Head Latent Attention (MLA) 에서 Latent는 "잠재적인(hidden or latent) 변수"를 의미합니다. 여기서 잠재 변수(Latent Variable) 는 모델이 직접 관측할 수 없는 내재적인 정
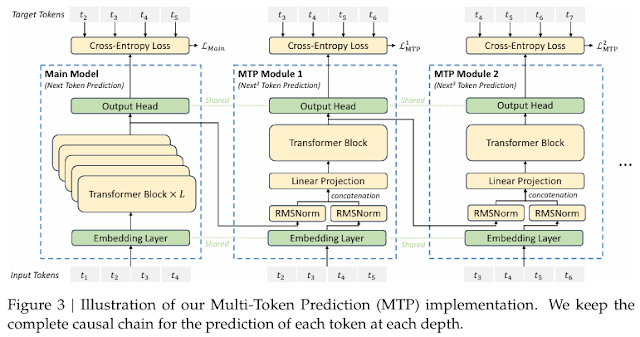
MoE와 다중 토큰 예측
이전 포스팅 글에서 DeepSeek에 대해 작성하며, MoE와 다중 토큰 예측을 다루어 좀 더 자세히 작성하기 위한 글입니다. MoE MoE (Mixture of Experts)란 MoE(Mixture of Experts)는 여러 개의 전문가(Experts) 모델을 두고, 입력에 따라 적절한 전문가를 선택해 학습과 예측을 수행하는 모델 구조입니다. -> ...
DeepSeek-V3: MoE 기반 AI 모델
DeepSeek-V3는 총 671억 개의 매개변수를 가진 Mix-of-Experts(MoE) 기반의 대규모 Transformer 언어 모델입니다.이 모델은 DeepSeek-R1의 지식을 전수받아 질문 응답, 코드 생성, 수학 문제 해결 등 다양한 작업에 최적화될 수 있
A4000 VS RTX 3060 * 2 + NVLink 개념 정리
단일 GPU(A4000, 16GB)하나의 GPU가 전체 16GB VRAM을 사용 가능큰 모델이나 대용량 데이터 처리가 가능RTX 3060 \* 2 (멀티 GPU, 각각 12GB)VRAM이 합쳐지지 않음 → 각 GPU는 독립적으로 12GB씩 사용모델이나 데이터가 단일 G
DeepSeek V3 & R1
DeepSeek는 V3가 발표될 당시만 해도 회의적인 시각이 많았고, 아직 갈 길이 멀다는 평가가 있었습니다. 그러나 올해 1월 R1이 발표되면서 AI 업계뿐만 아니라 다양한 산업군에서 DeepSeek에 대한 관심이 급격히 높아졌습니다. DeepSeek의 기술 발전
[LoRA와 4-bit 양자화] NLP 모델 튜닝을 위한 최적화
자연어 처리(NLP) 모델은 계속해서 대규모화되고 있으며, 이를 훈련하거나 활용할 때 필요한 리소스가 엄청나게 증가하고 있습니다. 특히 대형 모델을 활용할 때는 메모리 부족 문제와 계산 비용이 큰 부담이 될 수 있습니다. 이러한 문제를 해결하는 데 있어 LoRA (Lo
딥시크 리뷰
딥시크 논문 및 깃허브 연구의 목적 기존 연구는 지도학습(SFT)에 의존해 대규모 언어 모델(LLMs)의 성능을 개선하였으나, 지도 학습 데이터는 수집과 라벨링에 많이 시간과 비용을 소요되어 이것을 개선하기 위해 연구 목표 지도학습 없이 강화학습(RL)만으로 LLM
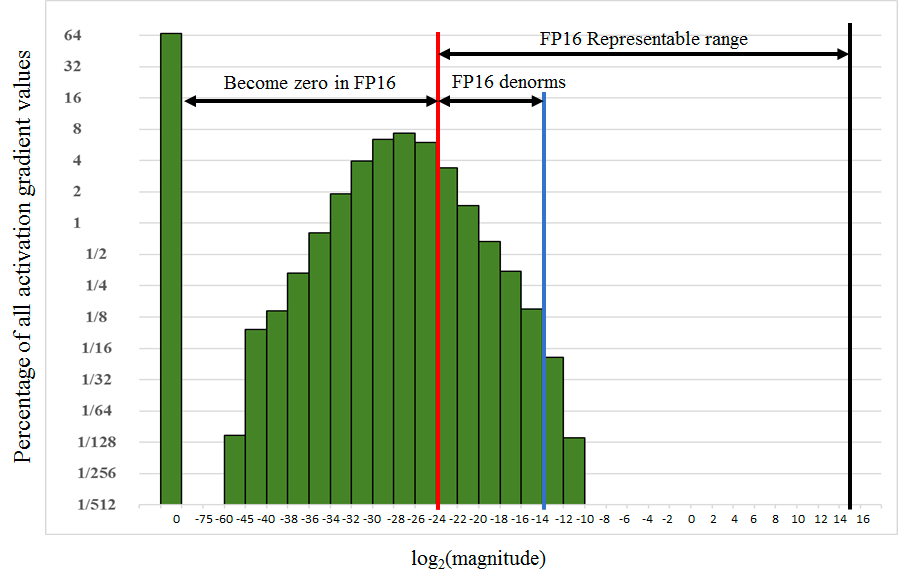
Mixed Precision Training
Mixed Precision Training해당 논문을 요약하자면 32-bit가 아닌 16-bit로 표현하여 배치 사이즈를 늘리고, 그에 따라 학습 속도를 빠르게 할 수 있는 Mixed Precision Training이라는 기술을 다룹니다.해당 과정에서 발생할 수 있
[LDM-Experiments] Image Generation with Latent Diffusion
해당 내용은 High-Resolution Image Synthesis with Latent Diffusion Models논문을 다루었습니다. 결과표 및 요약 내용입니다. Unconditional LDM의 hyper-parameter 관련 표입니다. 해당 표는 $25

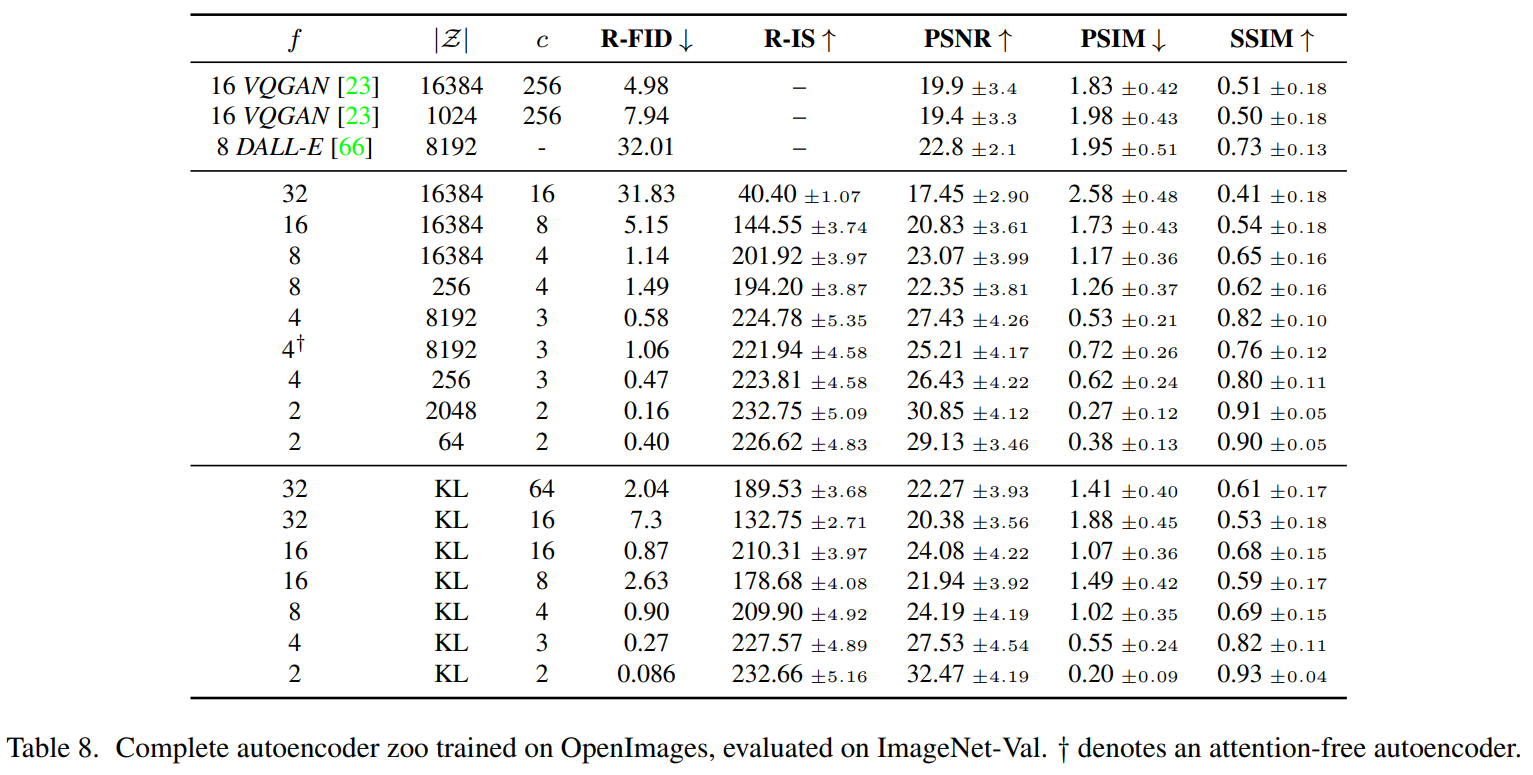
[LDM-Experiments] On Perceptual Compression Tradeoffs
해당 내용은 High-Resolution Image Synthesis with Latent Diffusion Models 관련 리뷰입니다.학습 및 inference 모두에서 픽셀 기반 diffusion model과 비교 및 장점 분석입니다.VQ-regularized l
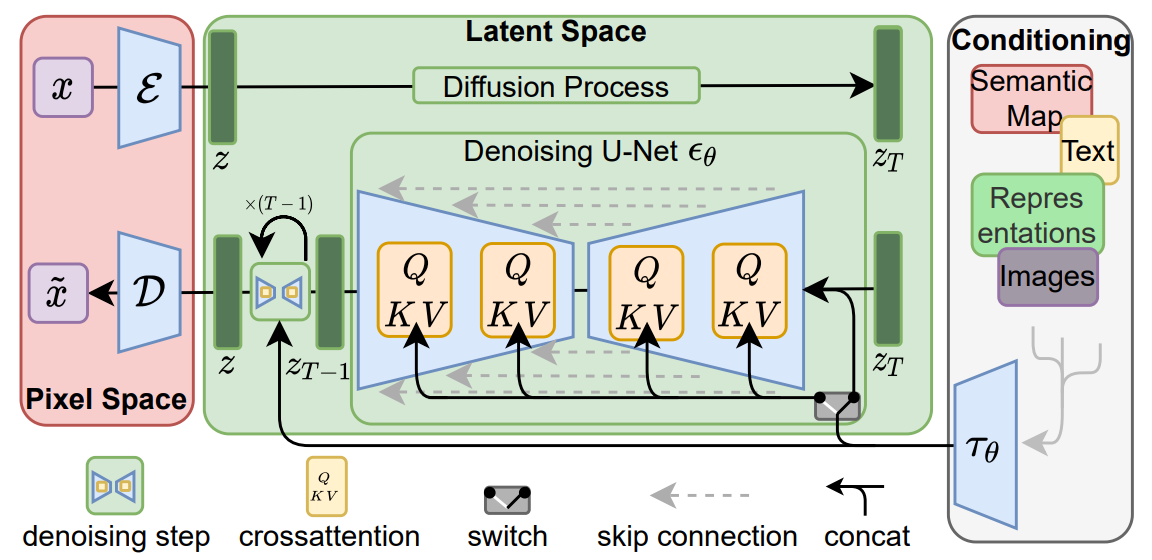
Conditioning Mechanisms(추가예정) 및 Diffusers 학습코드
Conditioning MechanismsPermalink 다른 유형의 생성 모델과 마찬가지로 diffusion model은 원칙적으로 $P(z|y)$ 형식의 조건부 분포를 모델링 할 수 있습니다. 조건부 denoision autoencoder $\epsilon\the
[Method] Latent Diffusion Models
저번 시간 Perceptual Image Compression에 이어 Latent Diffusion Models에 사용되는 Method를 알아보도록 하겠습니다. Latent Diffusion Models Diffusion model은 정규 분포 변수의 noise를 점
[Method] Perceptual Image Compression
고해상도 이미지 합성에 대한 Diffusion Model(확산 모델) 학습의 계산량을 낮추기 위해 Diffusion Model이 해당 손실 항을 적게 샘플링하여 Perceptual(지각적인) 세부사항들을 줄일 수 있지만, 그렇더라도 픽셀 공간에 대한 계산 비용이 많이
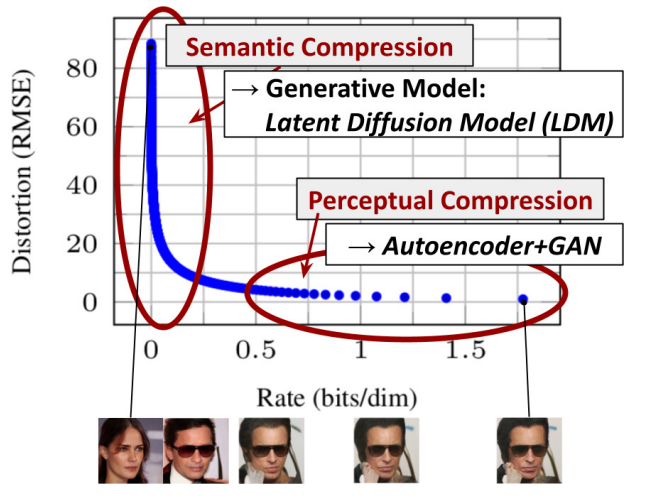
[Introduction]LDM(Latent Diffusion Models)
Diffusion model은 이미지 합성과 해상도 품질을 올리는 분야에서 좋은 성능을 보였지만, 데이터의 감지할 수 없는 세부 정보를 모델링 하는데 과도한 자원을 소비하는 경향이 있습니다.DDPM의 재가중된 목적 함수는 초기 노이즈 제거 단계에서 적게 샘플링하여 자원
Stable Diffusion
최근 추천 받은 DDPM(Denoising Diffusion Probabilistic Model)과 LDM(High-Resolution Image Synthesis with Latent Diffusion Models)을 학습을 시작하려고 합니다.우선 학습을 시작할 논문
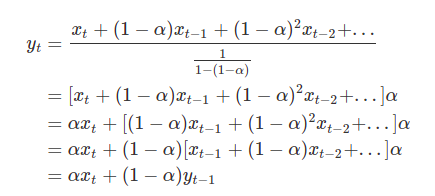
이동평균(Moving Average)
데이터가 방향성을 가지고 움직일 때, 이동하면서 구해지는 평균을 뜻합니다.동적으로 변화하는 것에는 어디든 이동평균을 적용할 수 있으며, 또한 1차원적인 방향성을 가지고 이동하기에 이동편균을 적용 가능합니다가정 m일의 평균(m = Window)n번째 데이터의 단순 이동평