
- 전체보기(59)
- DL(29)
- ML(15)
- CV(14)
- CNN(8)
- NLP(6)
- Generation(3)
- LLM(3)
- project(3)
- ai competition(2)
- 통계(2)
- 현직자 특강(1)
- Object Detection(1)
- kaggle(1)
- Git&Github(1)
- dacon(1)
- transformer(1)
- Backbone(1)
- Data-Centric AI(1)
- 영어(1)
- algorithm(1)
- OPIC(1)
- simulation(1)
- RNN(1)
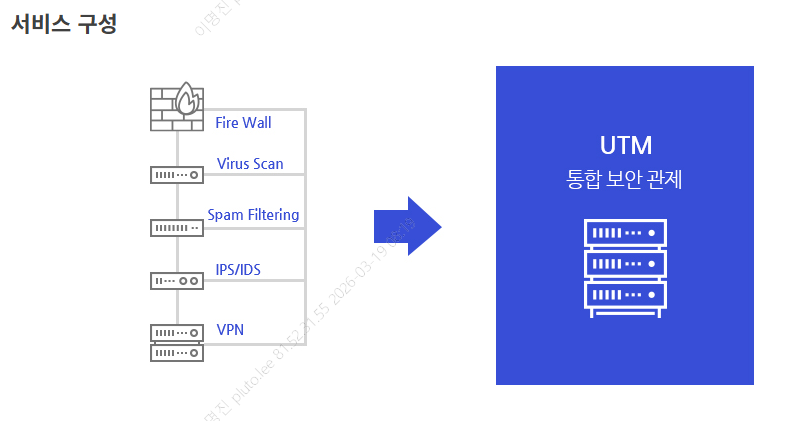
UTM
과거에는 방화벽, 안티바이러스, 스팸 차단기등 각각 별도의 장비를 구입해야했지만, UTM은 이 모든 보안 기능을 하나의 HW+SW에 통합한 솔루션 방화벽 + IPS(Intrusion Prevention System: 침입방지)+ IDS(Intrusion Detectio
프록시와 캐싱
프록시(proxy)는 중간에서 대신 연결을 처리해주는 서버나 SW쉽게 말해, 사용자가 직접 목적지 서버에 연결하지 않고, 프록시 서버를 거쳐서 인터넷이나 네트워크 자원에 접근하는 방식.내가 웹사이트 A에 접속하고 싶을 때 → 내 컴퓨터가 바로 A로 가지 않고, 프록시
[삼성기출] 2023 하반기 오전 1번 문제 - 왕실의 기사대결
기본 시뮬레이션- 격자 이동 왕실의 기사대결dict(key-value) 이용해서 units={1번 기사:r,c,h,w,k, 2번 기사 :r,c,h,w,k ...} 관리 격자 바깥 쪽으로도 이동 불가,arr = \[2(L+2)] + \[2+ list(map(int,inp
[Data-Centric AI] Data-Centric AI란?
AI 시스템을 이루는 두 가지 요소양쪽 모두 개선 필요(데이터 품질이 좋을 땐: 모델 개선효과가 더 중요 <-> 데이터 품질 안좋을 땐: 데이터 개선이 더 중요)Why?데이터는 곧 모델을 학습하는 데에 필요한 재료But동일한 데이터에 대해 서로 다른 어노테이션/라
[LM to LLM] 의미기반 언어 지식 표현 체계 이론
“단어가 나타나는 주변 맥락이 유사하면, 그 단어들의 뜻도 서로 비슷하다”는 것을 의미즉, 비슷한 의미를 가진 단어는 주변 단어 분포도 비슷함을 의미“단어의 의미는 그 단어가 사용되는 맥락에 의해 결정된다”라는아이디어를 기반으로 단어의 의미를 이해하는 방법론ex) Te
[LM to LLM] 카운트 기반 언어모델
국소 표현(Local Representation): 해당 단어 그 자체만 보고, 특정 값을 맵핑하여 단어를 표현하는 방법 예) 고양이: 1, 귀여운: 2, 동물: 3분산 표현(Dense Representation): 그 단어를 표현하고자 주변을 참고하여 단어를 표현하는
[LM to LLM] 언어모델이란 무엇인가?
인간의 언어정보전달의 수단이자 인간 고유의 능력으로 인공언어에 대응되는 개념언어를 이루는 구성 요소(글자, 형태소, 단어, 단어열(문장), 문단 등)에 확률값을 부여하여 이를 바탕으로 다음 구성 요소를 예측하거나 생성하는 모델단어 시퀀스에 확률을 할당(assign)=>
[NLP] RNN 및 LSTM, GRU 적용 자연어 처리
Sequence-to-sequence 이해하기 입력된 시퀀스(문장)을 다른 시퀀스로 변환하는 모델로, 인코더 RNN과 디코더 RNN로 구성 인코더 (Encoder) : 입력 시퀀스를 받아들여 고정된 길이의 벡터로 변환함. 이 벡터는 입력 시퀀스의 정보를 압축적으로
[NLP] 딥러닝 기반 자연언어처리 개괄
규칙 기반 모델• 적은 양의 데이터로 일반화 가능• 결론 도출의 논리적 추론 가능• 학습에 필요한 데이터가 비교적 적게 필요• 이를 제작한 전문가의 실력을 넘어서기 매우 어려움 • 해당 전문가의 오류를 동일하게 반복• 규칙 구축에 많은 시간과 비용 소요• Toy tas
[NLP] 텍스트 전처리
컴퓨터가 텍스트를 이해할 수 있도록 하는 Data Preprocessing 방법• HTML 태그, 특수문자, 이모티콘 • 정규표현식• 불용어 (Stopword)• 어간추출(Stemming)• 표제어추출(Lemmatizing)• 주어진 데이터를 토큰(Token)이라 불리
[Generation] AutoEncoder
입력 데이터의 패턴을 학습하여 데이터를 재건하는 모델 비선형 차원 축소 기법으로 활용 가능오토인코더는 입력 데이터의 효율적인 표현을 학습하는 비지도 학습 모델일반적으로 인코더(encoder)와 디코더(decoder) 두 부분으로 구성인코더는 입력 데이터를 저차원의 잠재
[Generation] 생성모델과 MLE
모델 파라미터 𝜃에 의존하는 분포 p(x; 𝜃) 를 따르는 n개의 데이터 x1, x2, ..., xₙ 관찰데이터로부터 모델 파라미터 𝜃를 어떻게 추정할 수 있을까? → 가능도를 최대화하는 파라미터를 찾자!가능도를 최대화하는 파라미터 𝜃를 찾는 방법일반적으로 가능
[Generation] 판별모델과 생성모델
판별 모델이란?데이터 X가 주어졌을 때, 특성 Y가 나타날 조건부 확률 p(Y|X)를 직접적으로 반환하는 모델판별 모델: 주어진 데이터를 통해 데이터 사이의 경계를 예측어떤 데이터를 서로 다른 클래스로 분류해주는 문제에 활용될 수 있음정상 데이터에 대한 경계를 최대한
[CV] 2-Stages Detector
Object Detection = Localization + Classification→ 두 가지의 task를 분리하여 2 stage로 따로 수행Stage 1: 이미지 내에서 object가 있다고 판단되는 위치 찾기 (Region proposal)Stage 2: 각 위
[CV] Transformer 이해
최근 computer vision domain에서도 transformer backbone이 주류Natural Language Processing (NLP)에서 생기는 문제점을 해결하기 위해 고안Long-term dependency기존 모델들은 sequence data를
[CV] EfficientNet
ResNet 이후 backbone 연구의 중요 한 축으로 wide & deep그 결과. CNN backbone의 이미지 이해 성능은 증가 했지만, parameter 크기가 커지고 속도가 느려짐성능은 좋지만, 속도가 빠르고 크기가 작은 모델에 대한 요구 증가일반적으로 효
[CV] Image Classification
Image Classification: 컴퓨터 비전 분야에서 대중적인 taskArchitecture: Backbone (CNN) + Classification head (FC Layer)backbone에서는 이미지에 대한 특징 추출 fc에서 이미지가 속할 가능성이 있
[DL] 다양한 최적화 함수
모멘텀(Momentum), RMSProp, 그리고 Adam은 딥러닝에서 널리 사용되는 최적화 알고리즘.각 알고리즘은 기존의 확률적 경사 하강법(Stochastic Gradient Descent, SGD)을 개선하여 보다 효율적으로 최적의 매개변수를 찾음.기본 개념: 모
AI Researcher 현직자 특강
업스테이지 악명의 7단계 Recruiting Process for Engineer/Developer Step 1 서류전형 | 자기소개서,이력서,포트폴리오 Step 2 알고리즘 코딩 테스트 Step 3 딥러닝 코딩 테스트 (for AIRE) Step 4 기술 인터뷰
[CV] CV Backbone Overview
Neural Radiance Fields는 3차원 장면을 디지털로 재구성하는 데 사용되는 딥러닝 기반 기술MLP는 input layer → hidden layers → output layer로 구성Input layer의 neuron 개수는 tabular data의 fe