
- 전체보기(26)
- 모두의 딥러닝(8)
- Perceptron(2)
- 핸즈온머신러닝(2)
- 퍼셉트론(2)
- DecisionTreeClassifier(2)
- 다중 분류(2)
- SVM(2)
- 준지도 학습(2)
- scikit learn(2)
- multi classificiation(1)
- 서포트 벡터(1)
- 강화 학습(1)
- 지도 학습(1)
- stochastic gradient descent(1)
- 파라미터 모델(1)
- 과대적합(1)
- 랜덤 포레스트 기초(1)
- projection(1)
- SGD(1)
- 비파라미터 모델(1)
- Hard Margin Classification(1)
- large margin classification(1)
- 과소적합(1)
- 앙상블(1)
- 추천 시스템(1)
- BIRCH(1)
- recall(1)
- 배깅(1)
- Back Propagation(1)
- 다중 레이블 분류(1)
- soft margin classification(1)
- sigmoid(1)
- 주성분 분석(1)
- adam(1)
- 차원의 저주(1)
- StratifiedKFold(1)
- 배치 학습(1)
- OvO(1)
- RandomForestClassifier(1)
- 재현율(1)
- confusion matrix(1)
- DecisionTree(1)
- PR curve(1)
- 하드 마진 분류(1)
- decision threshold(1)
- 자기 지도 학습(1)
- validation set(1)
- 신경망(1)
- 모델(1)
- 오차 역전파(1)
- overfitting(1)
- Multiclass Classification(1)
- dbscan(1)
- RMSProp(1)
- ClassifierChain(1)
- 딥러닝(1)
- 선형 판별법(1)
- cluster(1)
- 다층 퍼셉트론(1)
- min_samples_leaf(1)
- 결정 임계값(1)
- 점진적 학습(1)
- cross_val_score(1)
- 로지스틱 회귀(1)
- precision(1)
- k-평균++알고리즘(1)
- 스펙트럼-군집(1)
- AdaGrad(1)
- 소프트 마진 분류(1)
- 온라인 학습(1)
- 결정 트리(1)
- f1 score(1)
- 투표 기반 분류기(1)
- 미니배치 k-평균(1)
- 엔트로피(1)
- OvR(1)
- 공짜 점심 이론(1)
- model(1)
- k fold(1)
- 비지도학습(1)
- cart(1)
- 렐루함수(1)
- 매니폴드(1)
- 과적합(1)
- 부스팅(1)
- NAG(1)
- 비지도 학습(1)
- 오프라인 학습(1)
- 인공신경망(1)
- 정밀도(1)
- PCA(1)
- K-평균(1)
- softplus(1)
- 평균 이동(1)
- 서포트 벡터 머신(1)
- 실루엣 점수(1)
- 지니 불순도(1)
- momentum(1)
- 병합 군집(1)
- 군집(1)
- 유사도-전파(1)
- 센트로이드(1)
- KNeighborsClassifier(1)
- 랜덤 포레스트(1)
- 훈련 지도 방식(1)
- 전처리(1)
- 집단지성(1)
- 투영(1)
- Vanishing gradient(1)
- Multilayer Perceptron(1)
- ReLU(1)
- 스태킹(1)
- parameter model(1)
- DeepLearning(1)
- mnist(1)
- 머신러닝(1)
- 확률적 경사 하강법(1)
- ova(1)
- 지역 선형 임베딩(1)
- 페이스팅(1)
- 소프트플러스함수(1)
- 랜덤 투영(1)
- Logistic Regression(1)
- 사례 기반 학습(1)
- k-평균 속도 개선(1)
- nonparameter model(1)
- 모델 기반 학습(1)
- Binary Relevance(1)
- k-NN(1)
- Hands-On Machine Learning with Scikit-Learn, Keras, and TensorFlow(1)
- Multilabel classification(1)
- OneVsRestClassifier(1)
- 모멘텀(1)
- f1score(1)
- k겹 교차 검증(1)
- 혼동 행렬(1)
- 라지 마진 분류(1)
- DecisionTreeRegressor(1)
- 계층분화KFold(1)
- manifold(1)
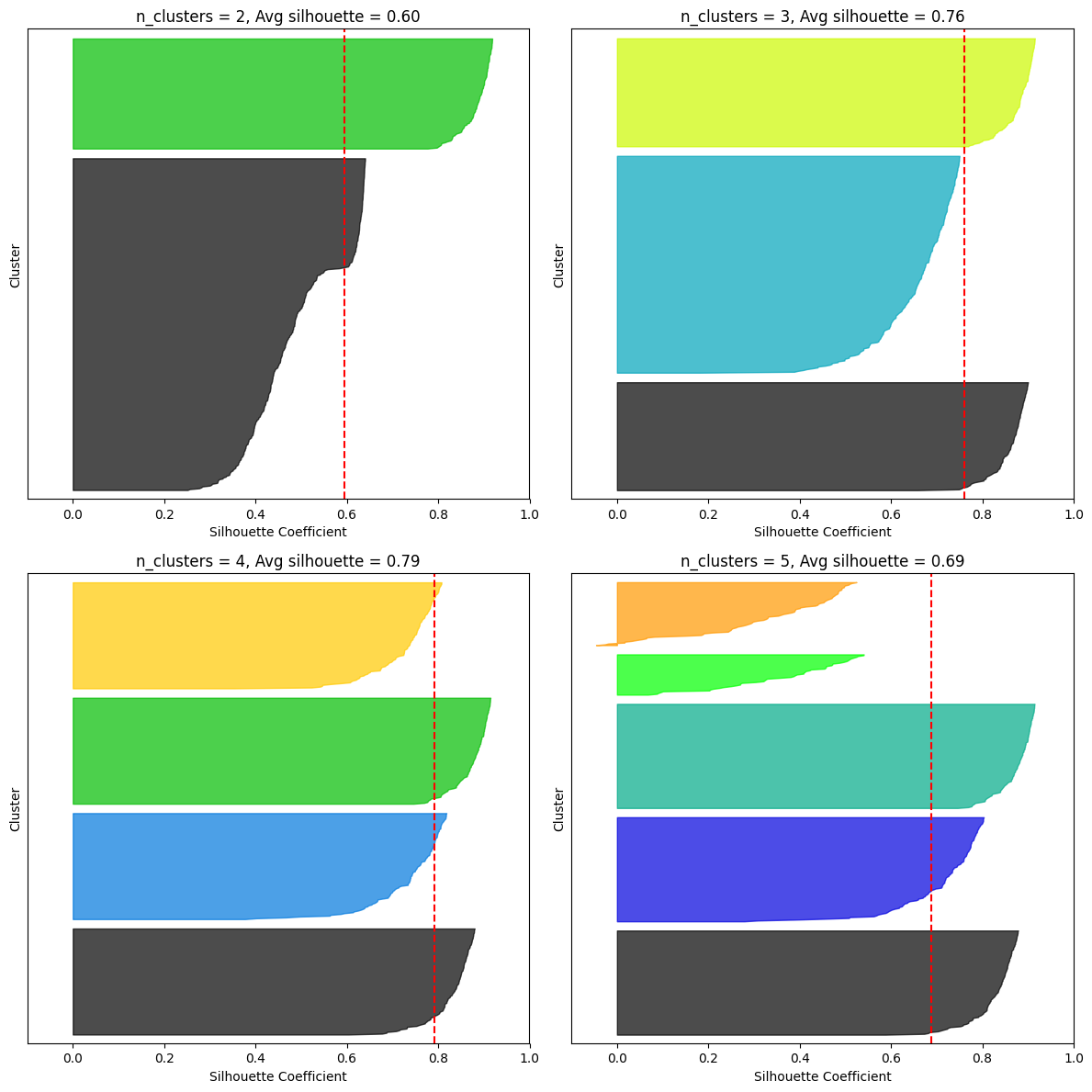
[Hands-On-Machine Learning]9장 9.1 군집
예전에 오픈랩 행사를 갔었는데, 교수님들 연구주제들 중에 군집 주행이 종종 등장했었다. 군집이란 단어를 들었었는데, 이게 다른 분야와 연관되어 사용될 수 있는 단어란 것을 알게 되었다.지도 학습과 달리 레이블이 없는 비지도 학습! 그 중 먼저 군집에 대해 다루어 보려고
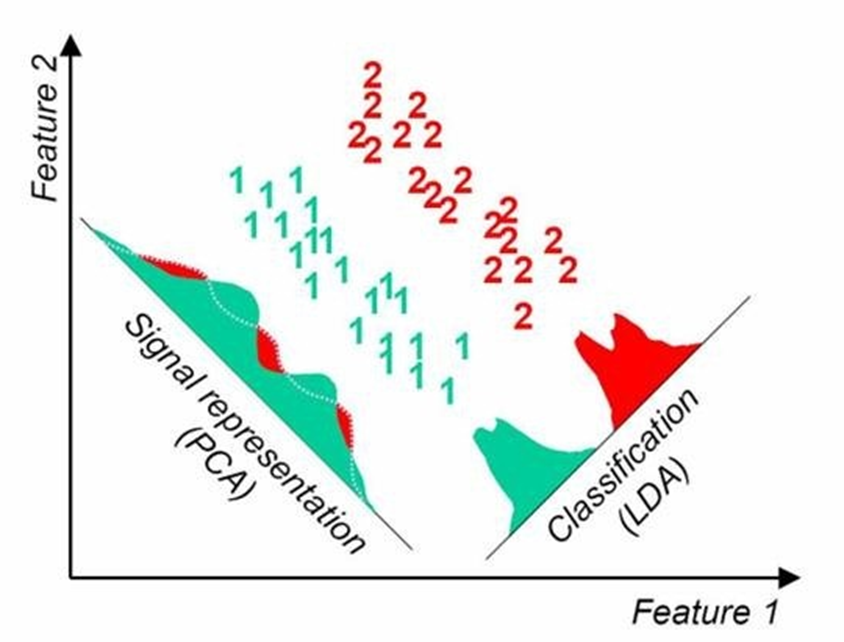
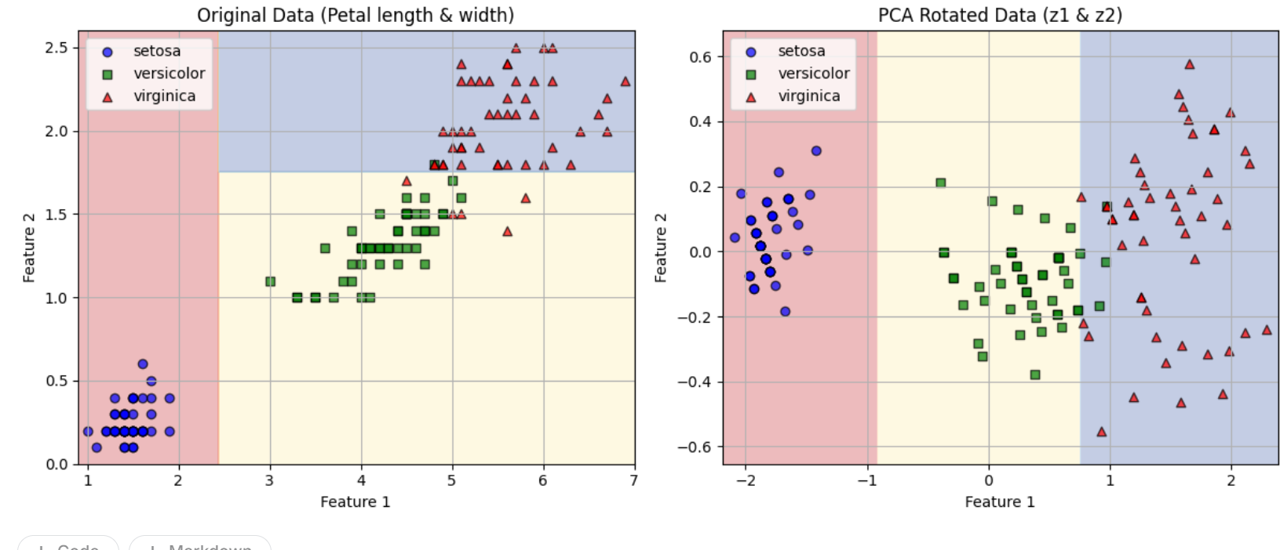
[Hands-On-Machine Learning]8장 차원 타노스
매번 컬럼 많은 데이터만 나오는 우려먹는 얘기지만...LG Aimers 하면서 느꼈던 것... 우와 컬럼이 진짜 정말정말 많구나...!!대체 얼마나 충격을 받았었으면 하지만 이렇게 많은 특성이 있으면 훈련을 느리게 할 뿐만 아니라 좋은 솔루션을 찾기 어렵다! 그래서
[Hands-On-Machine Learning]7장 앙상블 학습과 랜덤 포레스트
드디어! 캐글 단골 소재 앙상블에 대해 알아보는 시간이다! 바로 가보자~ > ✅ 앙상블(ensemble) 앙상블은 일련의 예측기, 즉 여러 예측기(모델)를 모아둔 것으로 보면 된다! 그래서 여러 모델을 이용해서 예측을 하기에 앙상블 학습(ensemble learni
[optimization] Dual Problem
원 문제(primal problem) : 제약 있는 최적화 문제 → 쌍대 문제(dual problem)라고 하는 깊게 관련된 다른 문제로 표현 가능\*일반적으로 쌍대 문제의 해는 원 문제 해의 하한값But!! 어떤 조건 하에서는 원 문제와 똑같은 해 제공함.→ SVM에
[ML] SVM 이론
선형 SVM 모델 → 단순히 결정 함수를 계산해서 새로운 샘플 x의 클래스 예측결정 함수 : $\\boldsymbol{\\theta}^T \\textbf{x} = \\theta_0 +\\theta_1 x_1 + \\cdots + \\theta_n x_n$ | 결과 >
[Hands-On-Machine Learning]6장 결정 트리
알고리즘에서도 느끼는 거지만 Tree 구조가 정말 중요한 것 같다. 앞으로 랜덤 포레스트의 기본 구성 요소가 결정 트리라고 하니 잘 정리해 보려고 한다! 결정 트리는 분류와 회귀 작업, 다중 출력 작업까지 가능한 ML 알고리즘이다. 🔥6.1~6.2 결정 트리 학습
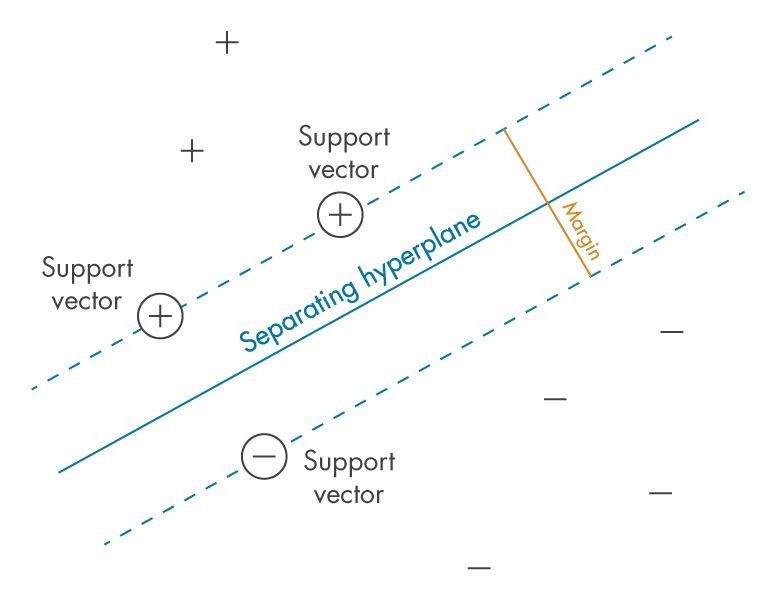
[Hands-On-Machine Learning]5장 서포트 벡터 머신
수식이 많아서 오늘은 광기를 담아 써야겠다 > 선형, 비선형 분류, 회귀, 특이치 탐지에도 쓸 수 있는 SVM! 골라 드세요! 주의 : 근데 데이터 많으면 별로... 😗 근데 어느 정도여야 많다고 보는 거지? 👶 샘플이 수십만~수백만 개일 때, 차원이 수천 개
[Hands-On-Machine Learning]4장 모델 훈련
🔥4.1 선형 회귀 🔥4.2 경사 하강법 🔥4.3 다항 회귀 🔥4.4 학습 곡선 🔥4.5 규제가 있는 선형 모델 🔥4.6 로지스틱 회귀
[Hands-On-Machine Learning]3장 분류
어느덧 핸즈온 머신러닝도 3장 째다. 드디어 본격적으로 머신러닝 기법에 대해서 학습한다! 먼저 분류, 즉 Classification에 대해서 다루어 보려고 한다. 지금부터는 나중에 해당 주제에 대한 내용을 한 번에 몰아볼 수 있도록 글을 나누어 작성하려고 한다. 필요한
[ML] Multilabel classification
회귀의 한 종류인 다중 라벨 분류에 대해 정리하려고 한다 분류기가 샘플마다 여러 개의 클래스를 출력해야할 때가 있다, 이럴 때 사용되는 것이 바로 다중 레이블 분류다! 다중 레이블의 예시를 찾아보면 아래와 같다! 생각보다 다양하다. 음악 장르 분류 한 곡이
[Hands-On-Machine Learning]2장 머신러닝 프로젝트 처음부터 끝까지
동아리에서 캐글을 직접 하면서 가장 먼저 들었던 의문은... "대체 EDA가 뭐지?" 라는 것이다. 제대로 된 순서도 모르고 다른 훌륭한 선두자들의 코드를 따라가면서 어영부영 따라갔었다... 순서가 좀 달라진 것 같지만 이제 드디어 제대로 된, 정석적인? 머신러닝 과정
[ML] 머신러닝 시스템의 종류
Hands-On-Machine Learning에서 머신러닝 시스템을 분류하는 기준에 대해 다루었었다. 특별히 따로 글을 작성해서 제대로 정리하려고 한다. 종류가 많으면 항상 분류하는 기준이 존재한다. 1.4.1 ) 훈련 지도 방식 (학습하는 동안의 지도 형태나 정보량에
[Hands-On-Machine Learning]1장 한 눈에 보는 머신러닝
머신러닝 입문서로 불리는 핸즈온 머신러닝을 이해한 대로 정리해보려고 한다. 1.1 🔥머신러닝이란? 머신러닝의 공학적인 정의는 아래와 같다 > A computer program is said to learn from experience E with respect
[ML] Multiclass Classification
1. 다중 분류🔥 2개 이상의 클래스로 분류하는 것을 다중 분류라고 한다. Random Forest classifiers와 Bayes classifiers = multinomial classifiers의 경우, 다중 분류가 가능하다. 하지만 Support Vector Machine classifiers와 Linear classifiers는 이진 분류...
[ML] ROC Curve
Receiver operating characteristicROC Curve는 이진 분류기에서 성능을 평가하는 데 자주 사용되는 도구다. 정밀도/재현 커브와 유사하지만, 여기서는 참 양성 비율(TPR)과 거짓 양성 비율(FPR)을 사용하여 그래프를 그린다.거짓 양성 비
[ML] Confusion Matrix와 이용
혼동 행렬을 이용해서 모델을 평가할 수 있다.혼동 행렬을 계산하려면 모델이 예측한 값들과 실제 값들이 필요하다. 테스트 세트에서 예측할 할 수 있긴 하지만 보통 테스트 세트는 프로젝트의 마지막 단계에서 최종 평가용으로 이용한다. 개발 과정 중에 테스트 세트를 사용하면
[ML] K-fold vs StratifiedKFold
교차 검증은 데이터의 편중을 막기 위해 데이터를 여러 부분으로 나누어 각각의 부분을 학습 및 검증에 사용하는 방법이다.Scikit-Learn에서는 cross_val_score() 함수를 이용해서 교차 검증 기법을 활용해서 정확도를 측정할 수 있다. y가 이진 클래스 또
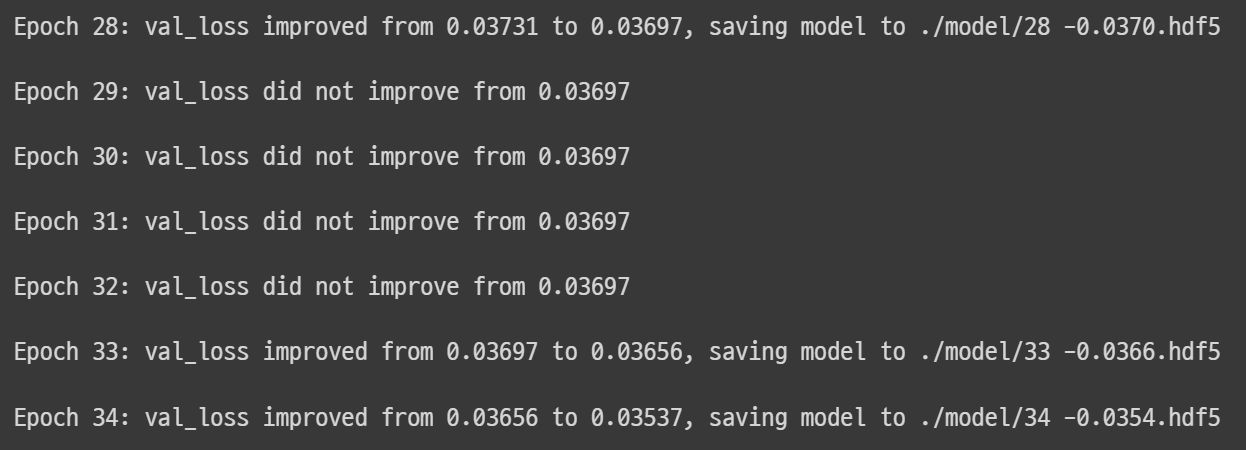
모두의 딥러닝 13장 overfitting
과적합 문제? 정확도가 100%? >과적합 overfitting 모델이 학습 데이터셋 안에서는 일정 수준 이상의 예측 정확도를 보이지만, 새로운 데이터에 적용하면 잘 맞지 않은 것을 의미 과적합이 생기는 경우 ① 층(layer)이 많은 경우 ② 변수가 복잡한 경