
- 전체보기(73)
- 문과생(72)
- 데이터(52)
- 제로베이스(51)
- 데이터사이언티스트(44)
- 파이썬(18)
- LG AImers(13)
- 데이터 분석(13)
- 딥러닝(10)
- 머신러닝(10)
- AI(9)
- 수포자(7)
- 시각화(7)
- 부트캠프(6)
- 데이터사이언스(6)
- 데이터분석(6)
- sql(4)
- 태블로(4)
- pandas(3)
- Jupyter(3)
- tableau(3)
- PINKWINK(3)
- opencv(3)
- jupyter notebook(3)
- mysql(3)
- 텐서플로우(2)
- CNN(2)
- 딥러닝 기초(2)
- GPT(2)
- git(2)
- 취준생(2)
- 컴맹(2)
- 통계학(2)
- 데이터과학자(2)
- python(2)
- 자율주행(2)
- tensorflow(2)
- matplotlib(2)
- numpy(2)
- 연산자(1)
- 컴퓨터 비전(1)
- 신뢰성 개념(1)
- 취준(1)
- 인과효과(1)
- Ensemble Learning(1)
- 41위(1)
- 경진대회(1)
- 알고리즘(1)
- codeup(1)
- 기업 조사(1)
- selenium(1)
- 파이토치(1)
- 사용법(1)
- radar(1)
- Deep learning Flow(1)
- 문과생 데이터사이언티스트되기 4(1)
- 딥러닝의 4단계(1)
- anaylsis seoul cctv(1)
- scatch(1)
- 서울시 주유소(1)
- 데이터사이언스 스쿨 2(1)
- 비지도학습(1)
- 과제(1)
- 노코드(1)
- 텍스트마이닝(1)
- 문과생 데이터사이언티스트되기!(1)
- Bayes Theorem(1)
- 인구소멸지역계산(1)
- query(1)
- 관련 기사(1)
- 운동 분석(1)
- 추천알고리즘(1)
- code up(1)
- 영상 데이터(1)
- SL Foundation(1)
- Statistics(1)
- 코드업(1)
- 사이언티스트(1)
- xor(1)
- 주피터(1)
- html(1)
- 관계형(1)
- 데이터 애널리스트(1)
- mnist(1)
- 인코더(1)
- 캐글(1)
- VGGNet(1)
- fbprophet(1)
- 프로젝트(1)
- ROC curve(1)
- Linear Regression(1)
- 거리맵차트(1)
- 예측(1)
- 크롤링(1)
- 문과생 데이터사이언티스트되기 5(1)
- aws(1)
- 레이더센서의 이해(1)
- 원리정리(1)
- RNN(1)
- code(1)
- 지도학습(1)
- 팀프로젝트(1)
- Perceptron(1)
- 코딩(1)
- 웹 데이터 분석(1)
- 데이터시각화(1)
- 시계열 분석(1)
- 데이터 시각화(1)
- Causality(1)
- 한글 깨짐 오류(1)
- 네이버 API(1)
- 디코더(1)
- XAI(1)
- miniconda(1)
- 스타벅스 이디야(1)
- 올웨이즈(1)
- math(1)
- 오토인코더(1)
- HMTL(1)
- ServiceNow 크리에이터 워크플로우(1)
- SPC(1)
- 자연어 데이터 특징(1)
- 인과추론(1)
- 비전공자(1)
- 문고생(1)
- 미니콘다(1)
- 순반향 연산(1)
- 통계(1)
- 빅데이터(1)
- 분석화(1)
- 코딩테스트(1)
- operator(1)
- 데이터 분석 및 시각화(1)
- 영상데이터(1)
- 모델(1)
- NLP(1)
- 스타벅스와 이다야 매장 비교(1)
- velog(1)
- 2일차(1)

Transformer
입력 방법이 병렬처리가 되어 있다 => 성능을 높일 수 있다.skip connectionlayer nomalization기계번역 task에서 기존의 연구들보다 성능적으로 우수병렬적으로 처리가 가능한 모델 -> time complexity 감소이후에 사용되는 bert,
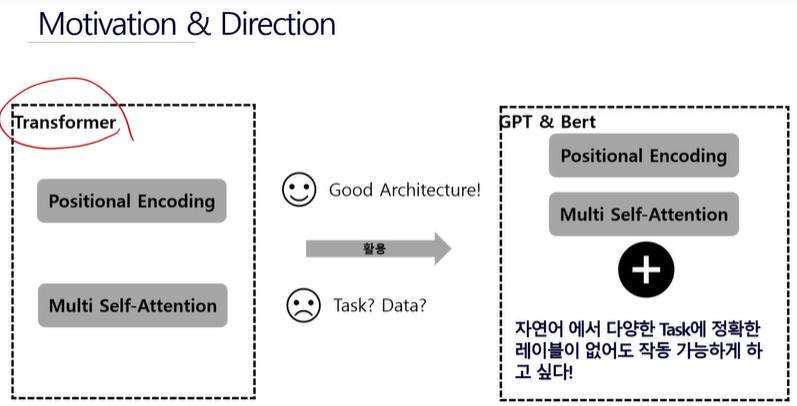
GPT 기초 설명
각각의 데이터 샘플들이 구성하고 있는 features는 독립적이미지 안의 의미있는 정보는 위치에 무관convolution 연산은 위치에 무관한 지역적인 정보를 추출하기 좋은 연산 문장을 구성하고 있는 단어들의 위치가 변해서는 안됨단어들 간의 관계가 중요하고 하나의 단어
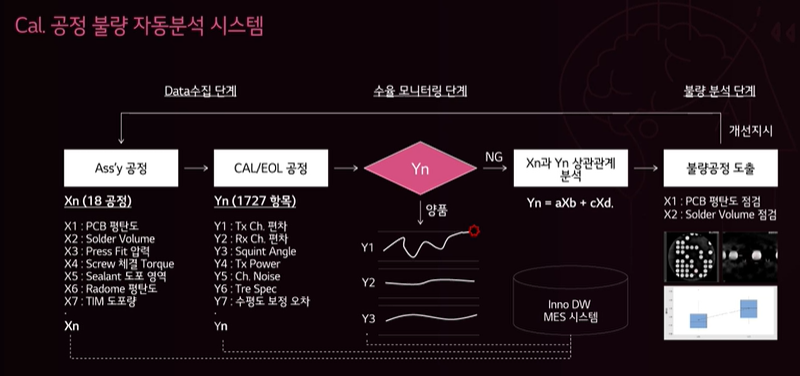
LG AImers - radar 제조 공정
rear occupant alert차량 내에 장착하여 후석 승객 유무를 감지in-cabin 모니터링 시스템에서는 카메라, 압력 센서, 초음파, 레이더 등 여러가지 센서 기술들이 사용하고 있다.5명의 탑승자 위치를 정확하게 파악하는 기술 PCB의 테스트 포인트를 통해 S

LG AImers - 자율주행의 메가 트렌드와 센서
미래 모빌리티 메가 트렌드의 핵심 키워드C : connectivityA : autonomousS : sharedE : electrificationA = 운전자 개입없이 스스로 안전하게 주행이 가능한 자율주행 고도화C = 고도화된 연결형 자율주행을 통한 탑승자의 안전 및
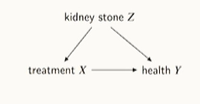
LG AImers - causal effect identification
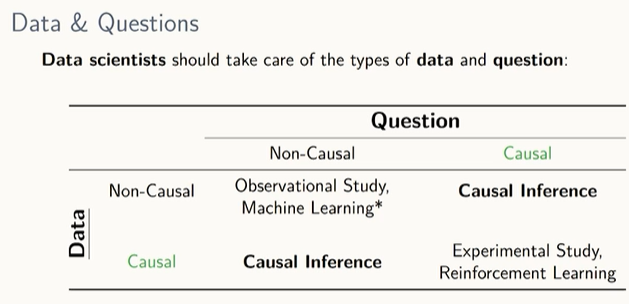
Querycausal diagramdata\-> causal inference engine 인과추론 알고리즘을 통해서 계산한다.인과 효과를 구하는 식 더 일반화한 방식x와 y의 전체 상관성은 두 가지, 직접 연결 관계 그리고 교란 변수에 의한 연결 관계 \- 데이
LG AImers - causality
causal decision making 효율적으로 환경과 인터렉션 하는 것을 연구 causal effect - causal discovery - causal decision making 서로를 돕는 역할 베이지안 네트워크 확률적 그래피컬 모델에 대한 기본적 지식
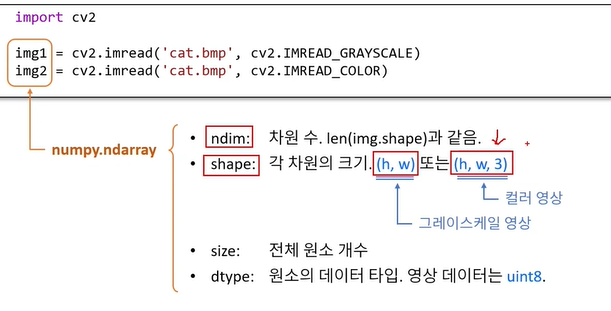
영상 데이터의 속성
openCV는 영상 데이터를 numpy.ndarray로 표현일반적으로 첫번째 줄의 표시를 주로 사용한다.cv2.CV_16F는 딥러닝에서 많이 사용된다.숫자 3은 3차원을 의미한다.

LG AImers - 설명 가능한 AI : Explainable AI(XAI)
딥러닝 학습의 한계점: 대용량 학습 데이터로 부터 학습하는 모델 구조 - 점점 더 복잡해지고 이해하기 어려워짐.모델 & 데이터셋의 오류 색출모델이 얼마나 편향되어 있는지 확인 가능사람이 모델을 쓸 때 그 동작을 이해하고 신뢰할 수 있게 해주는 기계 학습 기술
LG AImers - 전통기계학습과 딥러닝에서의 비지도학습
k-means clustering 데이터를 몇 개의 클러스터로 나누어서 비교적 비슷한 특징을 가지는 각각의 클러스터로 모으는 것을 목표 PCA 디멘션을 줄이기 위한 기법 EIGENVALUE DECOMPOSITION과 동일한 방식 전통적 머신러닝 low dimens
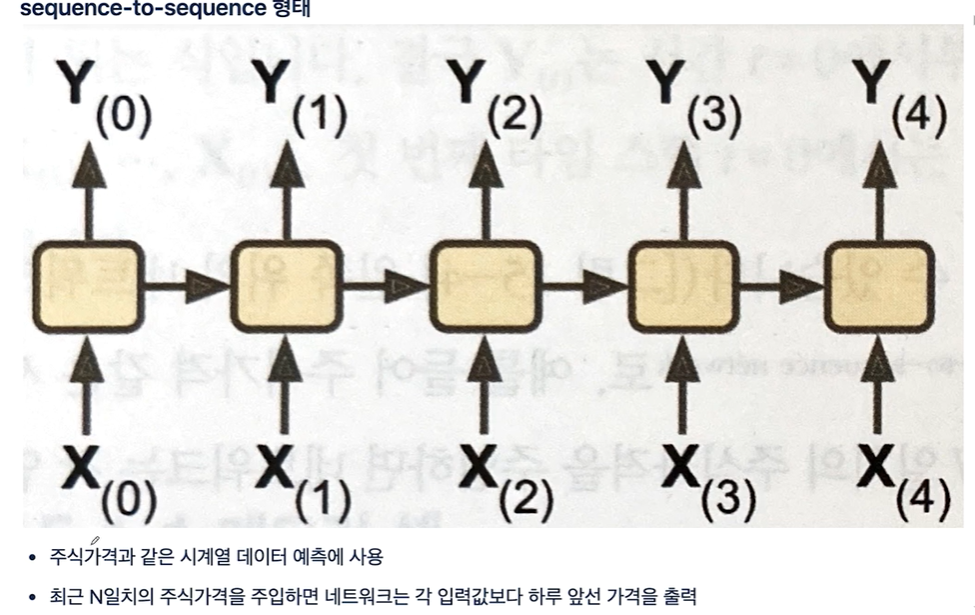
RNN include LSTM
순환신경망 \- 활설화 신호가 입력에서 출력으로 한 방향으로 흐르는 피드포워드 신경망 \- 순환 신경망은 뒤쪽으로 연결하는 순환 연결이 있음 \- 순서가 있는 데이터를 입력으로 받고 \- 변화하는 입력에 대한 출력을 얻음순환 뉴런의 출력은 이전 시간의
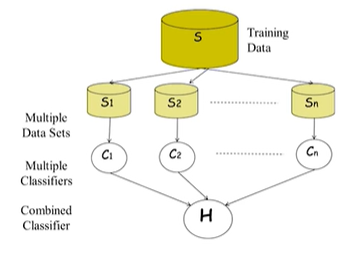
LG AImers - Ensemble Learning
이미 사용하고 있거나 개발한 알고리즘의 간단한 확장Supervised learning task에서 성능을 올릴 수 있는 방법Ensemble = 함께, 동시에, 한꺼번에 협력하여라는 의미머신러닝에서 알고리즘의 종류에 상관 없이 서로 다르거나, 같은 매커니즘으로 동작하는
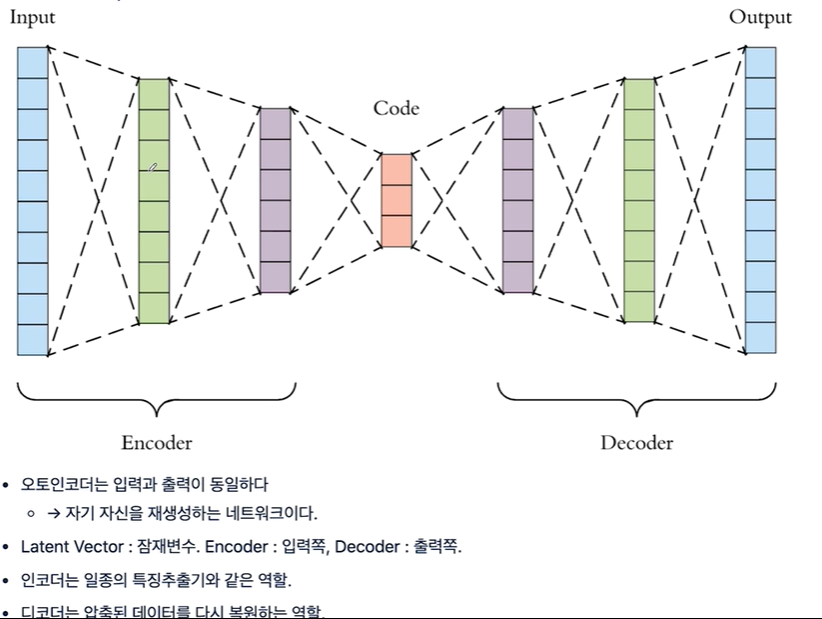
오토인코더
자기 자신을 출력으로 나오게 한다. \- 자기 자신이 비교 대상 train_x, train_x를 fit한 걸로 보아 train_x가 입출력하게 학습시키고 있다.그럼 결과 역시 자기 자신이 나온다는 것을 의미한다.DANSE 64 부분이 특성, code라고 할 수 있다
LG AImers - SL Foundation
DATA로부터 내재된 패턴을 학습하는 과정출력이 연속 변수인지 이산변수인지에 따라서 구분sl 머신러닝은 model output과 정답과의 차이인 error를 통해서 그 error를 줄여가면서 학습이 진행feature selection, model selection, o
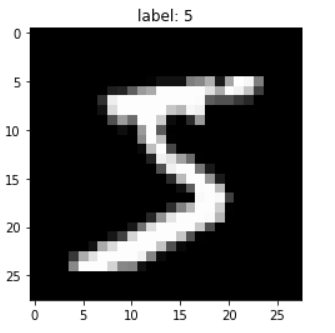
Pytorch MNIST 활용해보기
파이토치, matplotlib를 활용해야한다.current cuda device is cuda현재 cuda가 가능하다고 뜬다.train step: 1000 loss: 0.048train step: 2000 loss: 0.128train step: 3000 loss

LG AImers - 신뢰성 개념과 중요성
커뮤니티를 보니깐,,강의 내용을 캡처하면 안된다고 되어 있다..으아 그래서 앞으로는 부수적인 사진 자료를 참고할 수 없을 것 같다.!아쉽구만주어진 작동 환경에서 주어진 시간 동안 시스템이 고유의 기능을 수행할 확률출처: 산업자원부기술표준원품질의 분포 : 이형분포, 정규

LG AImers - 스마트 품질 경영
소비자들의 요구사항 증가 -> 많은 기업들은 여전히 전통적인 방식의 품질 관리 및 경영기법에 머물러 있다.제품 복잡도 및 다양성 증가, 제품주기 단축, 세계화 및 규제 변화 등은 효과적인 품질경영 수행을 어렵게 만드는 요인들ICT 융합을 통해 종전의 사후검사 및 보증에
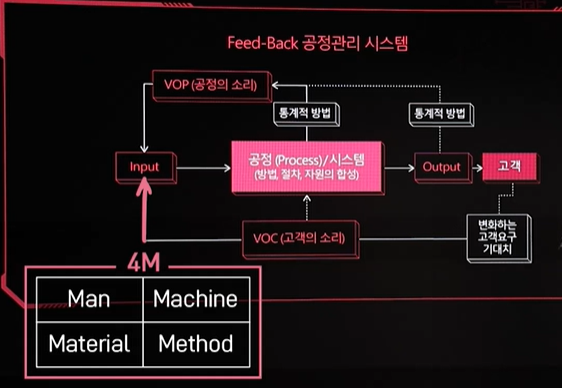
LG AImers - SPC의 필요성과 개념
품질은 4M, 재료, 장비, 작업방법, 작업자를 대상으로 지속적인 개선이 요구적은 데이터로부터 가능한 한 신뢰성이 높은 객관적인 정보를 얻는데 가장 유효한 수단품질 관리를 하는데 있어서 가장 필수적인 통계적 방법 \- 파레토 차트특성요인도체크시트히스토그램산점도그래프관

LG AImers- 품질 및 품질비용
우연히 지원한 LG의 새프로그램에 합격하여 LG 수업을 듣게 되었다.전통적 품질관리에서의 품질 : "규격에 부합하는 것"선험적 관점품질을 정의할 수는 없더라도 무엇인지 고객이 인지제품 관점바람직한 성분이나 속성의 함량 차이가 곧 품질의 차이사용자 관점용도 적합성제조 관
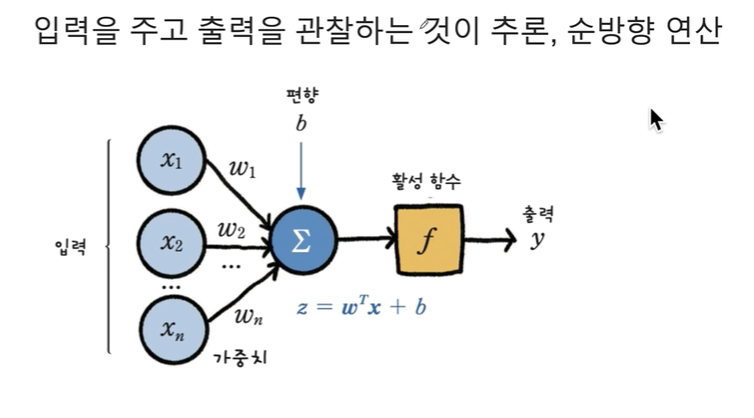
DeepLearning Scratch
array(\[-0.35626925, -0.54131108, 0.80274536])확인할 수 있다.가중치를 랜덤하게 선택했기에원래는 학습이 완료된 가중치를 사용해야 한다.값을 확인할 수 있었다.하지만 문제!!랜덤하게 잡았기 때문에 추론 결과는 아무런 의미가 없거나 틀