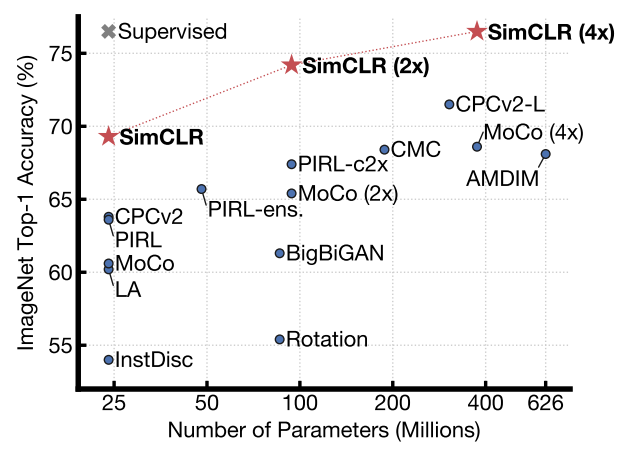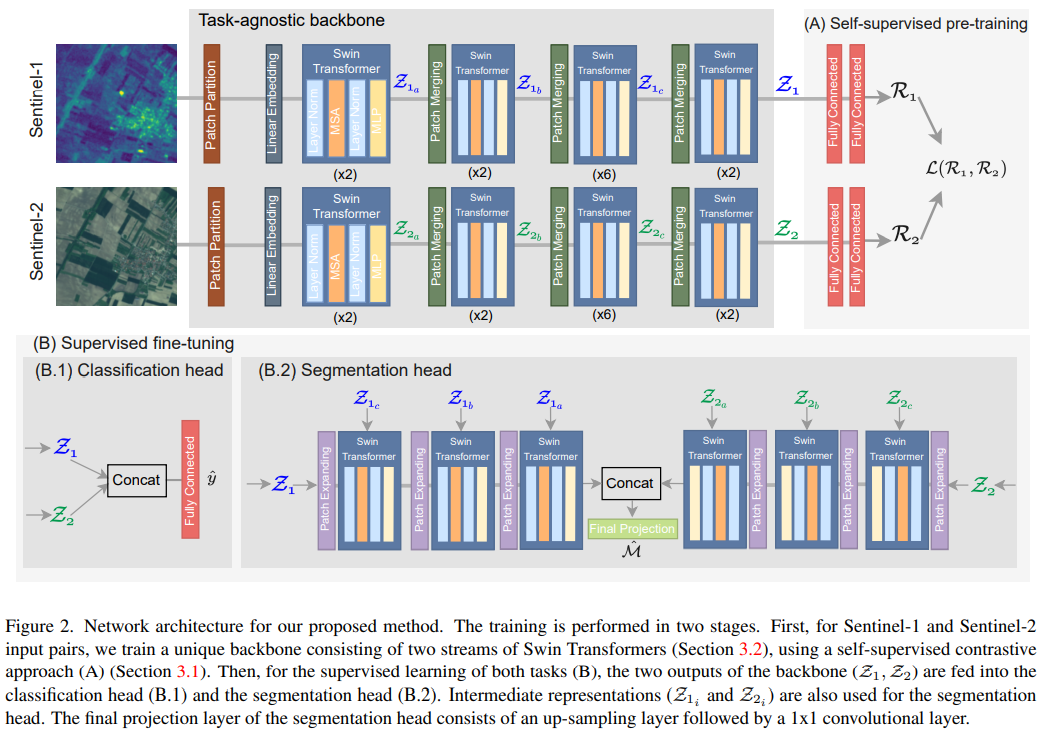
Review] Self-supervised Vision Transformers for Land-cover Segmentation and Classification
In this paper, it proposed the method to combine vision transformer architecture and self-supervied learning Overall structureThis work proposed two
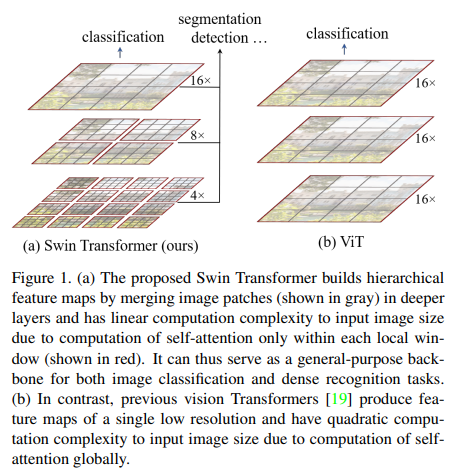
Review] Swin Transformer: Hierarchical Vision Transformer using Shifted Windows
The transformer structure shows that adaptation of attention module can outperform traditional CNN-based model.However the transformer has a problem t
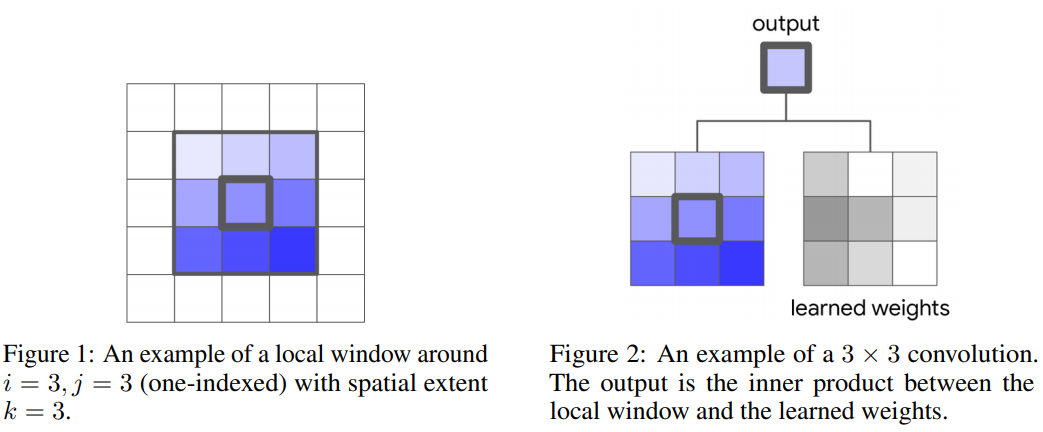
Review] Stand-Alone Self-Attention in Vision Models
Architecture of CNN has out-standing performance in computer vision applications. However, capturing long term arange interactions for convolutions is
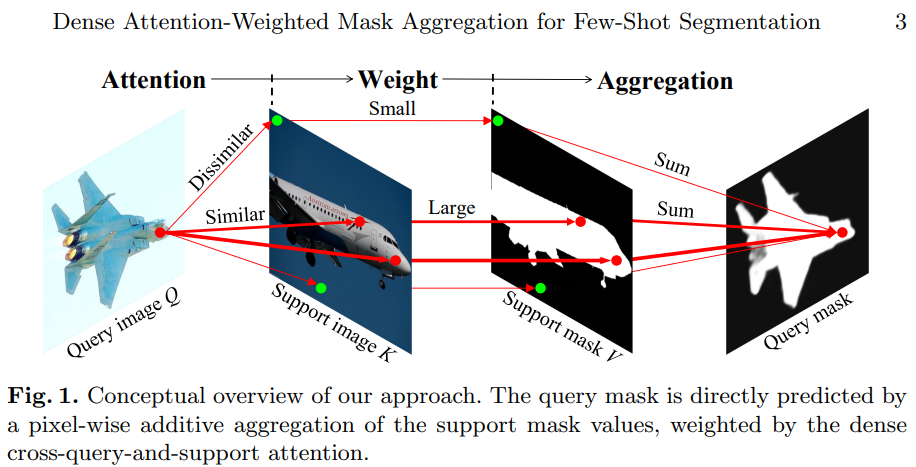
Reveiw] Dense Cross-Query-and-Support Attention Weighted Mask Aggregation for Few-Shot Segmentation - incomplete
1. Motivation
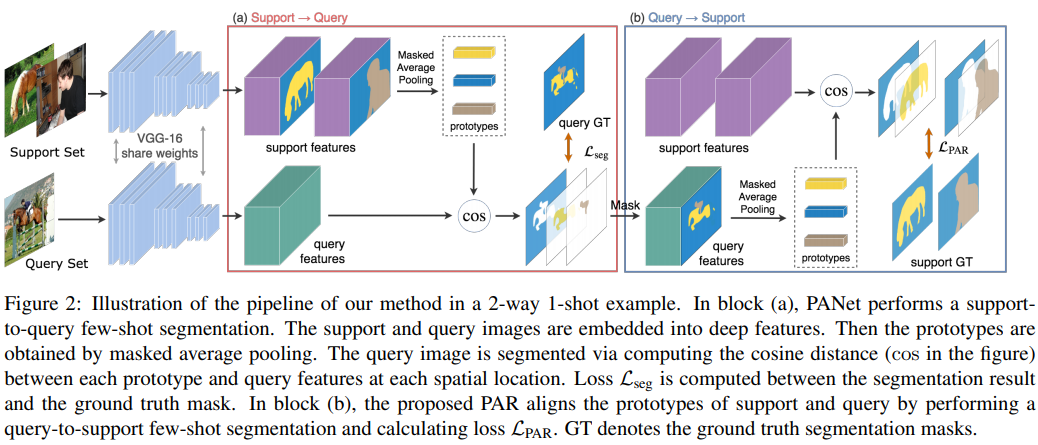
Review] PANet: Few-Shot Image Semantic Segmentation with Prototype Alignment
Previous few-shot segmentation method do not differentiate the feature extraction of the target object in the support set and segmentation process of

Review] Few-Shot Segmentation Propagation with Guided Networks
1. Motivation Semi- and weakly supervised segmentation methods cannot segment for a new input class. Therefore, this paper attempted to perform segmen
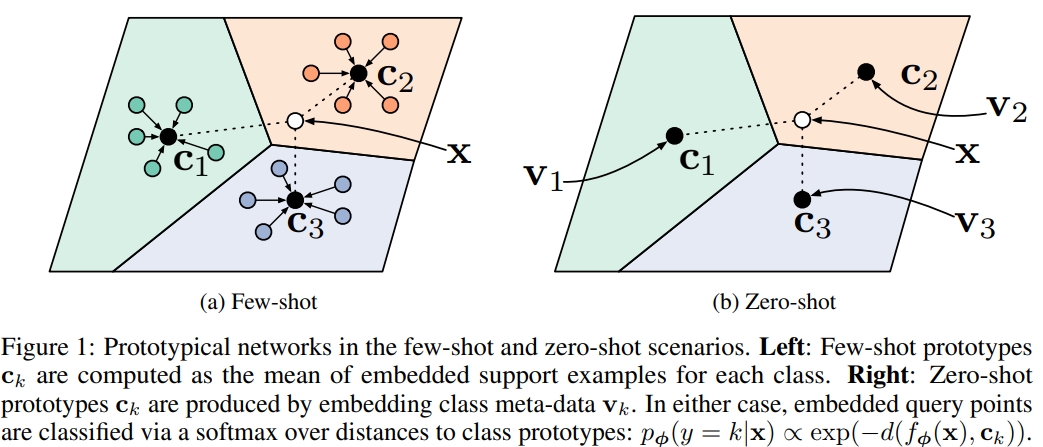
Review] Prototypical Networks for Few-shot Learning
Traditional approaches of neural networks have problem that need abundant amount of data. To overcome such problem, few-shot learning is proposed whic
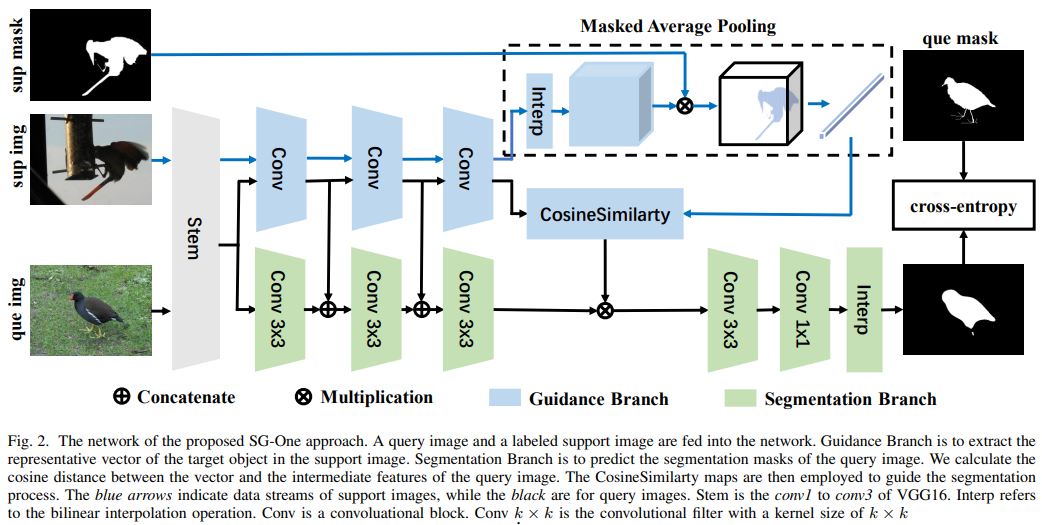
Review] Sg-one: Similarity guidance network for one-shot semantic segmentation
Traditional segmentation like Unet, FCN, extras require many loads for labeling tasks. To reduce the budget, one-shot segmentation is appliedThe one-s
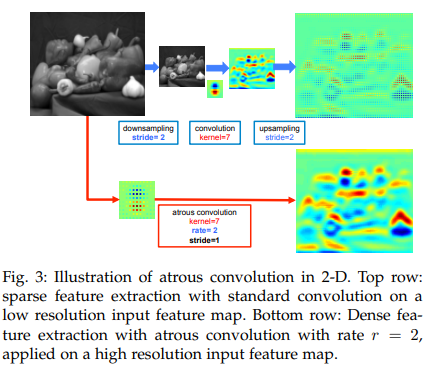
DeepLab: Semantic Image Segmentation with Deep Convolutional Nets, Atrous Convolution, and Fully Connected CRFs (Review)
1. Motivation There are three challenges in semantic segmantation with DCNN. (1) reduced feature resolution, (2) existence of objects at multiple scal
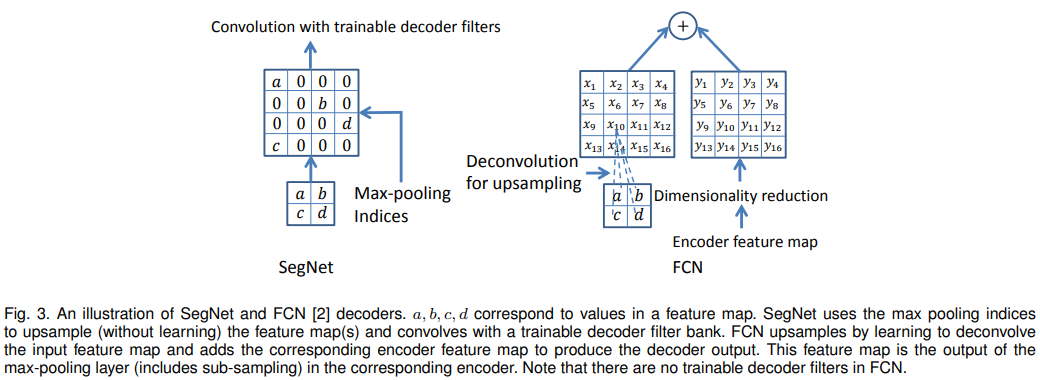
Review: A Deep Convolutional Encoder-Decoder Architecture for Image Segmentation(SegNet) - incomplete
The motiviation of this paper is to solve the problem of max pooling and sub-sampling reduce feature map resolution.Referencehttps://arxiv.org/pd
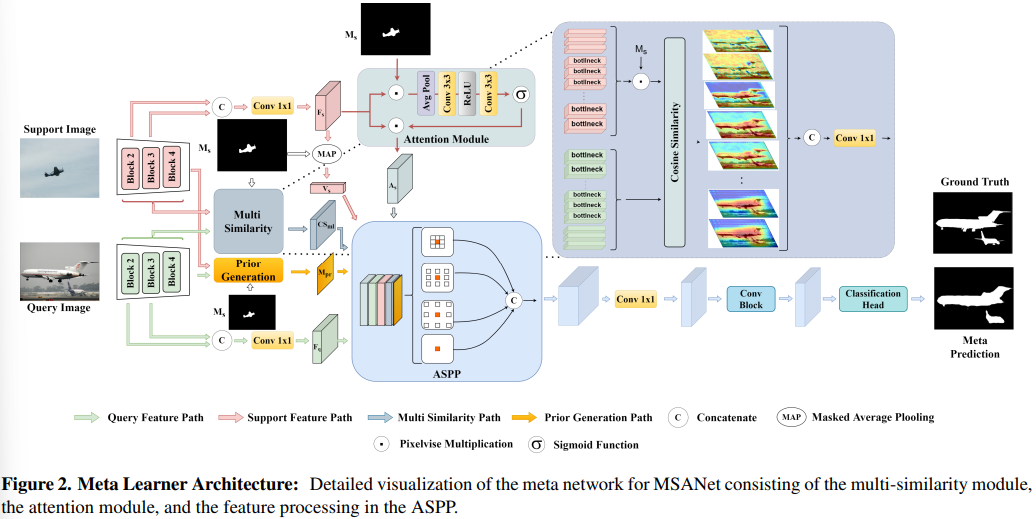
Review] Multi-Similarity and Attention Guidance for Boosting Few-Shot Segmentation(MSANet)
The problem of traditonal supervised CNN is that it needs the number of well-annotated data, the balance of class distribution and sample representati
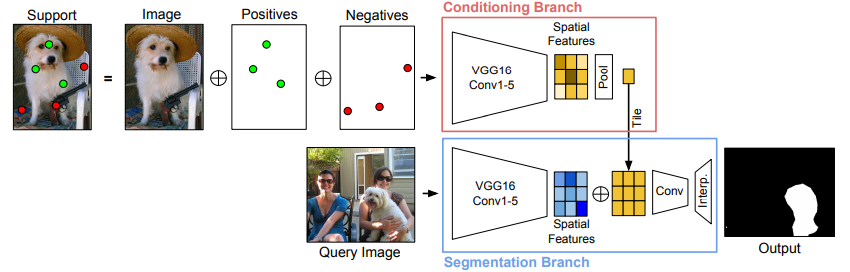
Review: CONDITIONAL NETWORKS FOR FEW-SHOT SEMANTIC SEGMENTATION
This paper proposed co-FCN network which make conditioning branch contain few-shot annotations. Samples for few-shot learning is selected from segment
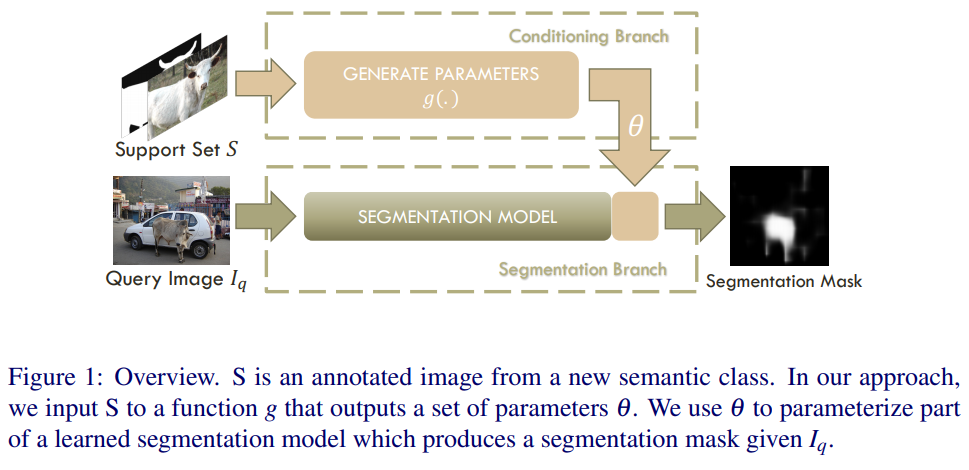
Review: One-shot learning for semantic segmentation
In this paper, it proposed semantic segmentation with one-shot learning which is pixel-level prediction with a single image and it's mask.A simple imp

Few Shot Learning
Human can recognize that the query is pangliln based on difference between four images, but it is chellenging for computer because there are a few ima
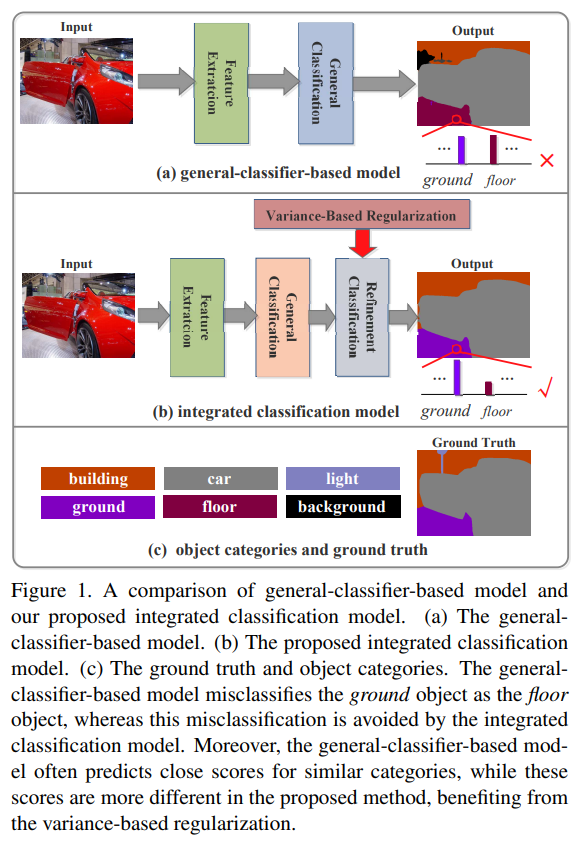
Review: Scene Parsing via Integrated Classification Model and Variance-Based Regularization ( incomplete )
Scene parsingScene parsing is to segment and parse an image into different image region associated with semantic catgories.Most of scene parsing model
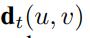
Review: Two-Stream Convolutional Networks for Action Recognition in Videos
1. Introduction In this paper, it tried to use CNN for recognizing human action which containing sptial and temporal information Architecture is based

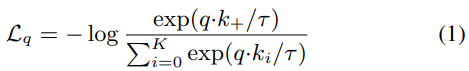
Momentum Contrast for Unsupervised Visual Representation Learning(MoCo) Review
1. Abstract & Introduction 이 논문은 dynamic dictionary(queue)와 contrastive loss를 이용한 이미지에서의 unsupervised learning을 실행하였다. 여기서 unsupervised learning은 dyna

Unsupervised Feature Learning via Non-Parametric Instance Discrimination(NPID) Review
이 논문의 주제는 ImageNet의 object recognition에서 나왔다고 한다. Figure 1에서 볼 수 있듯이 레오파드에 대한 top-5 classification error를 보면, 레오파드와 비슷하게 생긴 제규어나, 치타와 같은 동물들의 softmax값