
- 전체보기(13)
- AI(5)
- ML(3)
- NLP(2)
- SVM(2)
- 머신러닝(2)
- 클래스 불균형(2)
- 하이퍼파라미터 튜닝(2)
- Deep Learning(1)
- Computer Vision(1)
- SMOTE(1)
- 불용어제거(1)
- visualization(1)
- MBTI(1)
- 딥러닝(1)
- KNN(1)
- f1 score(1)
- cs231n(1)
- 선형대수학(1)
- transformer(1)
- 자연어처리(1)
- gm(1)
- XGBoost(1)
- accuracy(1)
- 생성모델(1)
- 전처리(1)
- Preprocessing(1)
- GridSearchCV(1)
- ANN(1)
- normal equation(1)
- DL(1)
- 리샘플링(1)
- machine learning(1)
- GridSearch(1)
- LinearSVC(1)
- Linear Regression(1)
- RNN(1)
- NLTK(1)
- 순환신경망(1)
- EDA(1)
- generative-models(1)
- 논문리뷰(1)
- CV(1)
- 앙상블(1)
- stanford(1)
- 모델 성능 평가(1)
[UoT] Introduction to Deep Learning (2)
Neural Network ArchitectureArchitecture: 신경망 내 뉴런과 연결 구조를 설명하는 개념Multi-Layer Perceptron (MLP):Feed-Forward 및 Fully-ConnectedLinear Layers + Nonlinear
[UoT] Introduction to Deep Learning (1)
Deep Learning Mid term test 요약 및 예상 문제 Week1 What is AI? AI is the intelligence of machines and the branch of computer science that aims to create i
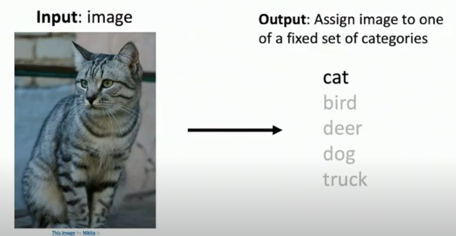
[cs231n+michigan DL for CV] lecture 2: Image Classification (1)
이미지 분류는 컴퓨터 비전의 중요한 핵심이다. 예를 들어, 이미지를 입력으로 사용하고 출력으로 레이블 중 하나를 이미지에 할당하는 작업이다.인간에게는 간단한 이미지 분류 작업이 컴퓨터에게는 어려운데, 그 이유는 semantic gap 때문이다. 인간은 이미지를 이미지

[cs226] Lecture 1: Introduction
생성 모델은 주어진 학습 데이터를 학습하여 학습 데이터의 분포를 따르는 새로운 데이터를 생성하는 모델이다. 학습 데이터와 유사한 데이터를 생성해야 하기 때문에 학습 데이터와 유사한 샘플을 뽑아야 한다. 따라서, 생성 모델에는 학습 데이터의 분포를 어느 정도 안 상태에서
Transformer in Pytorch
Hyperparameter of Transformer $d{model}$(hiddensize): 트랜스포머 모델에서 각 토큰의 임베딩 벡터 차원을 나타낸다. 즉, 입력과 출력의 벡터 크기이다. 트랜스포머의 encoder와 decoder에서 정해진 입력과 출력의 크기로
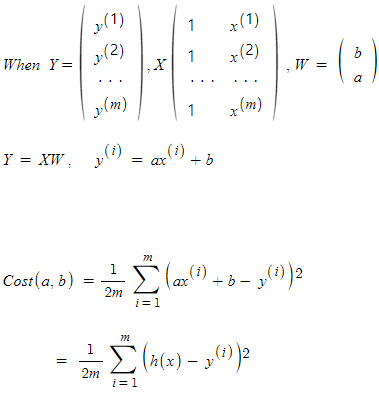
[선형대수학] Normal equation
정규 방정식(normal equation)은 최소제곱 문제(Least Squares Problem)에서 사용되는 방법으로, 선형 회귀에서 모델 파라미터를 추정하는데 사용되는 주요한 방법입니다. \-> 주어진 데이터 포인트들과 모델의 예측 값 사이의 오차를 최소화하여 모
[Chapter.1] Introduction and Optimization Problems
constraint -> enough to put in a knapsack: 도둑이 가장 값 비싼 물건을 훔쳐야 하는 optimization problem0/1 knapsack problem : 현재의 결정이 다음 결정에 영향을 끼침Continuous or fracti

[AI web service project] MBTIgram: 모델링-LinearSVC
이번 포스팅은 최종 모델로 선정된 LinearSVC 모델링 과정을 설명해보려고 합니다. 미해결 과제로 남았던 '클래스 불균형'을 SMOTE를 통한 리샘플링으로 해결하였고, TF-IDF Vectorizer과 GridSearchCV, LinearSVC를 이용하여 모델링을

[AI web service project] MBTIgram: 모델링-RNN
지난 포스팅에서는 XGBoost 모델링 과정을 설명했습니다:) 이번에는 시계열 데이터나 텍스트와 같은 도메인에서 강력한 성능을 발휘하는 RNN(Recurrent Neural Network) 모델링 과정에 대해서 다뤄보겠습니다. > # 모델링: RNN (Recurrent

[AI web service project] MBTIgram: 모델링-XGBoost
지난번 포스팅에서 전처리 및 EDA를 수행한 내용을 바탕으로 모델링을 진행했습니다.3가지 모델을 후보로 실험 및 검증을 진행했습니다. 전처리 및 EDA 과정은 이전 글을 참고 바랍니다.XGBoostRNNLinearSVC세 가지로 후보를 둔 이유는 다음과 같습니다.XGB

[AI web service project] MBTIgram: 데이터셋 전처리 및 EDA
💻 개발환경: Google Colab ✅ 사용 데이터셋 (MBTI) Myers-Briggs Personality Type Dataset [Link] https://www.kaggle.com/datasets/datasnaek/mbti-type mbti_1.csvMB
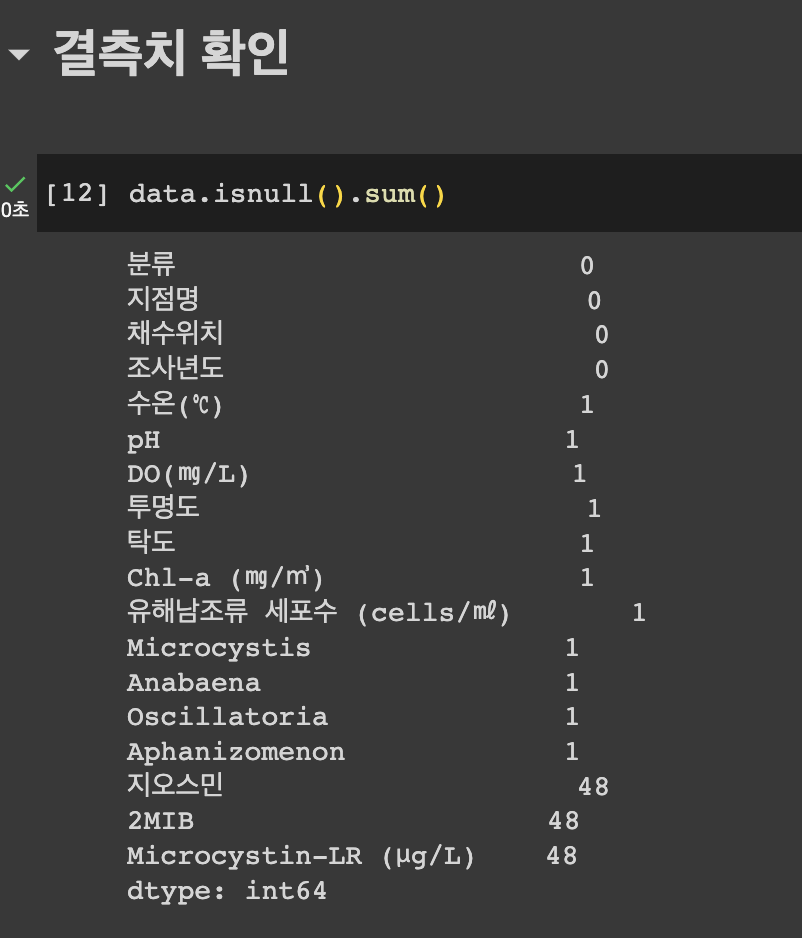
[ML] 데이터 결측치 처리 방법
정형 데이터를 다루다 보면 null 값을 가진 컬럼들이 존재하는 경우가 많다. 결측치를 처리하는 방법에는 7가지가 있다.Data Imputation1\. 평균값으로 대체(Mean Imputation)\-> 결측치가 존재하는 변수에서 결측치를 제외한 나머지 값들의 평균으

[Data Science] 녹조 발생지역 예측 분석 Project
녹조(algal bloom)란? 강이나 호수에 남조류가 과도하게 성장하여 물의 색깔이 짙은 녹색으로 변하는 현상을 말한다. 이와같이, 남조류 과잉 발생이 녹조의 주된 원인이기 때문에 머신러닝과 딥러닝을 통해 유해 남조류 발생 예측을 한다면 녹조 발생지역 예측 분석이