
- 전체보기(57)
- bioinformatics(14)
- Data Science(13)
- python(11)
- unix(8)
- C(8)
- system_programming(8)
- machine learning(6)
- Java(6)
- datastructure(6)
- DeepLearning(6)
- Spring(4)
- R(3)
- datascience(3)
- Sort(3)
- algorithm(3)
- Web Scraping(2)
- AI(2)
- Deep Learning(2)
- transformer(1)
- Backend(1)
- reinforcement learning(1)
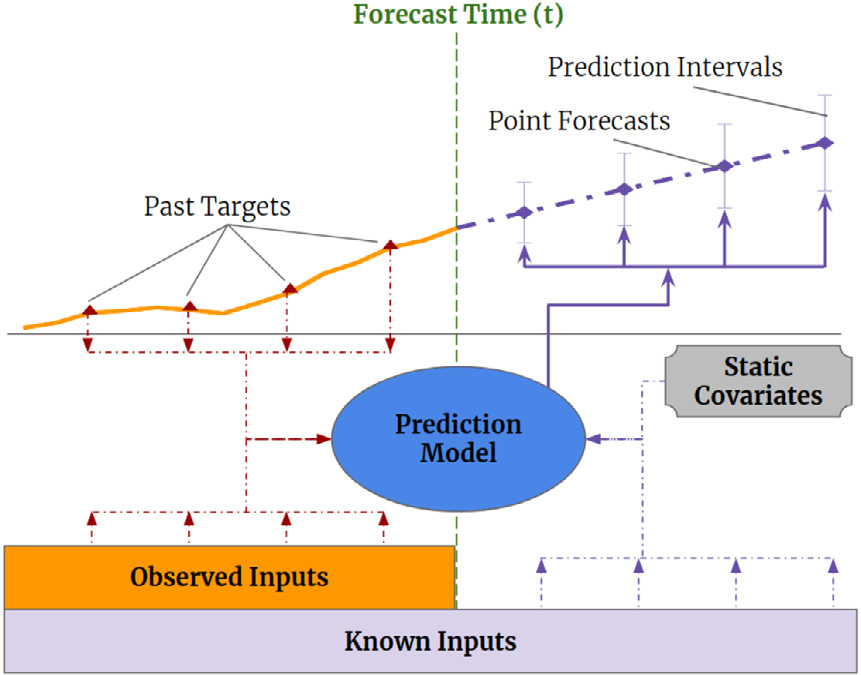
Temporal Fusion Transformers
시계열 예측에서 기존의 LSTM, GRU 기반 모델들은 단일 시점 예측에는 강한 성능을 가지지만, 미래의 여러 시점 (Multi-Horizon)을 동시에 예측하는데에는 한계가 있다. 현재 Forecasting분야의 SOTA(State of the art) 모델인 Tem
Molecular Niche
Molecular Niche란 특정 세포의 생존, 분화, 그리고 기능을 조절하는 국소적인 분자적 환경을 의미한다. 단순히 물리적인 위치를 넘어, 세포가 노출된 화학적 신호, 대사 물질, 물리적 지지체 등의 총체적인 집합이다. Cytokines & Chemokines :
KNN Algorithm
K-Nearest Neighbor Algorithm(KNN) 는 Supervised Learning 알고리즘 중 하나로 , 분류(Classification)이나 회귀(Regression)문제에 모두 사용될 수 있는 직관적이고 간단한 모델이다.핵심 아이디어로 데이터는 다
Annotated Data
1. Anndata Anndata(Annotated Data) 는 유전자 발현량과 같은 행렬 데이터와 그에 대한 주석(Annotation)을 하나로 묶어 관리하기 위해 설계된 데이터 구조이다. 아래에서 설명될 내용이지만, 만약 obs에서 특정 조건에 의해 필터링하면,
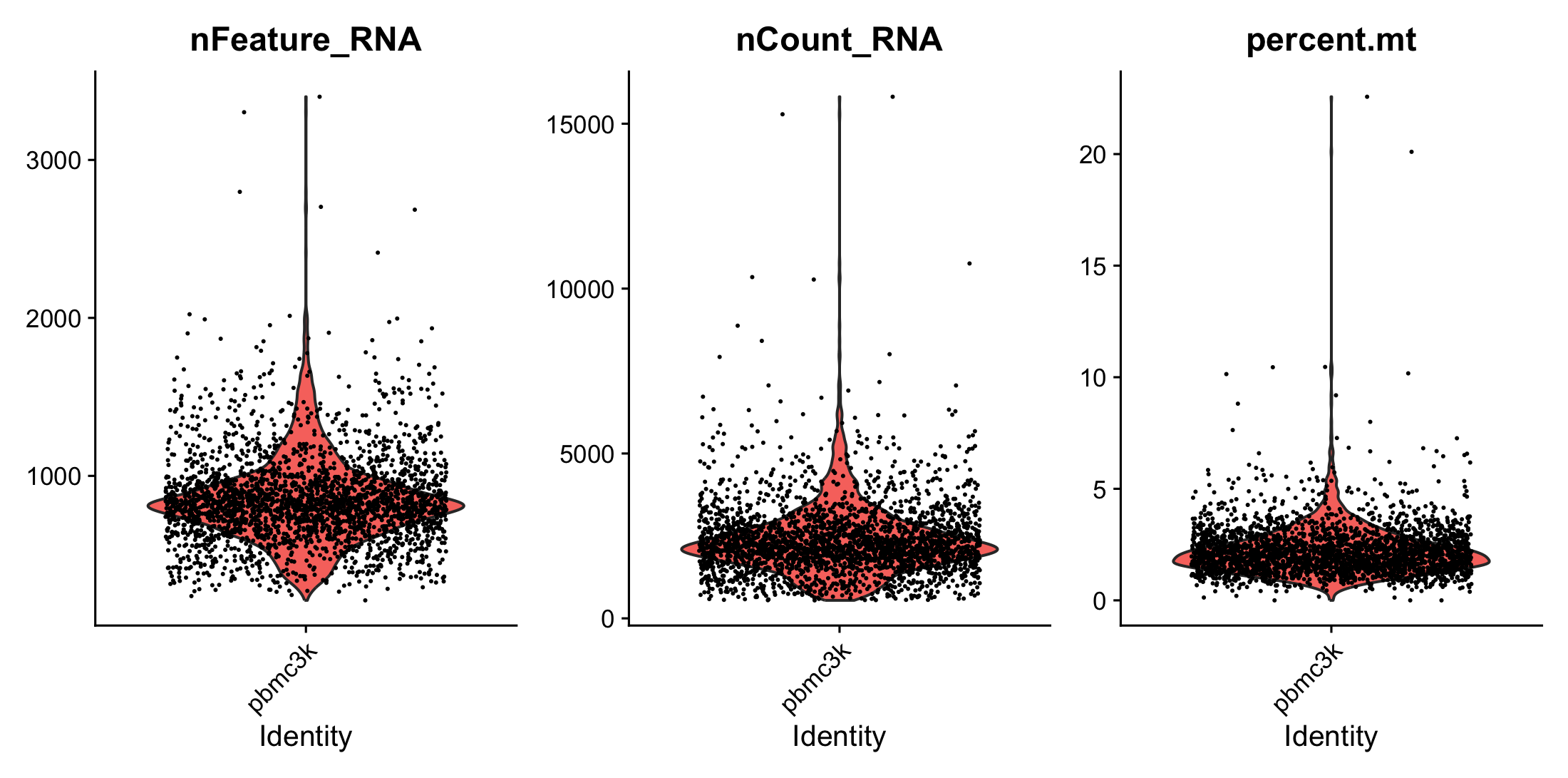
Seurat tutorial - Single Cell RNA-seq
그동안 우리는 효모 유전정보를 활용하여 정렬하고 DEG를 해보았는데, 이는 bulk RNA-seq로 조직 전체 또는 수백만개의 세포의 평균을 분석하는 방법이다.이제 더 나아가서 개별 세포 하나하나를 분석하는 Single-Cell RNA-seq(scRNA-seq) 를 해
DEG Analysis 실습
1. 데이터 준비 우리는 전 게시글에서 ERR458493 의 Saccharomyces cerevisiae 샘플을 정렬하였다. 정렬의 결과물 중 _ReadsPerGene.out.tab 파일은 각 유전자에 몇 개의 시퀀싱 Read가 Mapping 되었는지 그 Count
STAR 실습해보기
우리는 효모(Saccharomyces cerevisiae)의 유전자 정보들을 STAR를 이용해 정렬하기 위해 다음과 같은 파일이 필요하다.참조 유전체 파일 (.fasta) : 효모의 전체 DNA 구성이 적힌 파일으로서 STAR는 해당 파일을 기준으로 정렬해나간다.Sac
NGS - STAR 정렬
STAR는 Spliced Transcripts Alignment to a Reference의 약자로스플라이싱이 일어난 RNA 리드를 유전체에 정렬하는 빠른 프로그램이다.STAR는 인덱싱을 하여 접미사 배열(Suffix Array)을 만든후, 시드 탐색을 통해 최대 매핑

Q-Learning
1. Q-Learning 이란? Q-Learing은 Reinforcement의 대표적인 가치 기반(Value-based) 알고리즘이다. 핵심 : "어떤 상태(state)에서 어떤 행동(Action)을 하는 것이 얼마나 좋은가?" 를 Q값으로 학습하는 것이다. 목표 :
NGS - Alignment (정렬)
1. Alignment란 ? Alignment(정렬) 란, NGS 장비가 읽어낸 수억 개의 짧은 DNA 염기서열 조각(Read)를 참조 유전체(Reference Genome) 와 대조하여 Read가 유전체의 어디에 위치하는지 찾아내는 과정이다. 앞서 Qulity Con
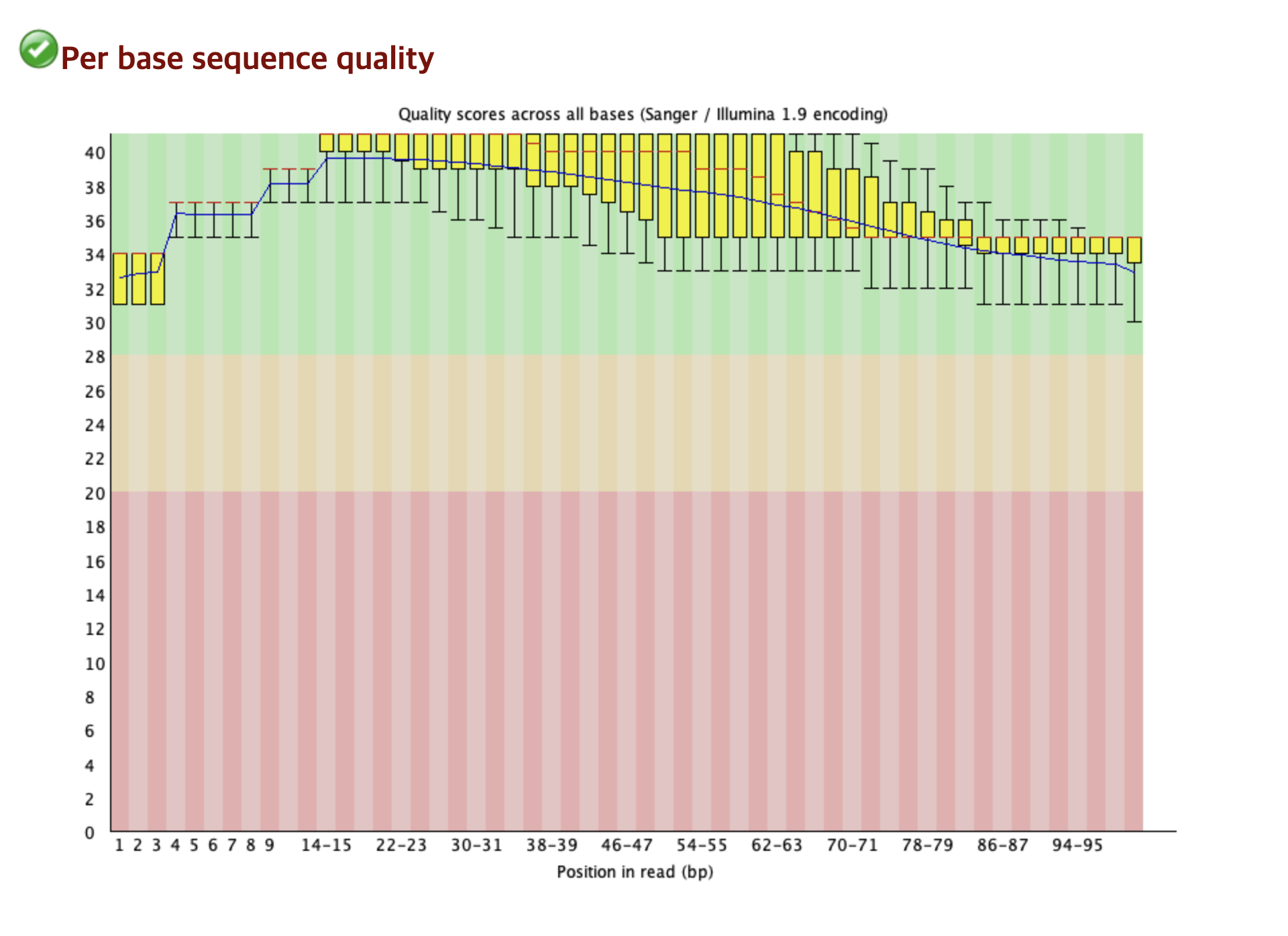
Quality Control
1. FASTQ format 차세대 염기 서열 분석 (Next-Generation Sequencing, NGS) 기술의 발전으로 방대한 양의 유전체 데이터를 얻게 되었는데, 이 데이터를 저장하는 방식이 FASTQ이다. Phred 품질 점수 FASTQ 파일의 네 번째
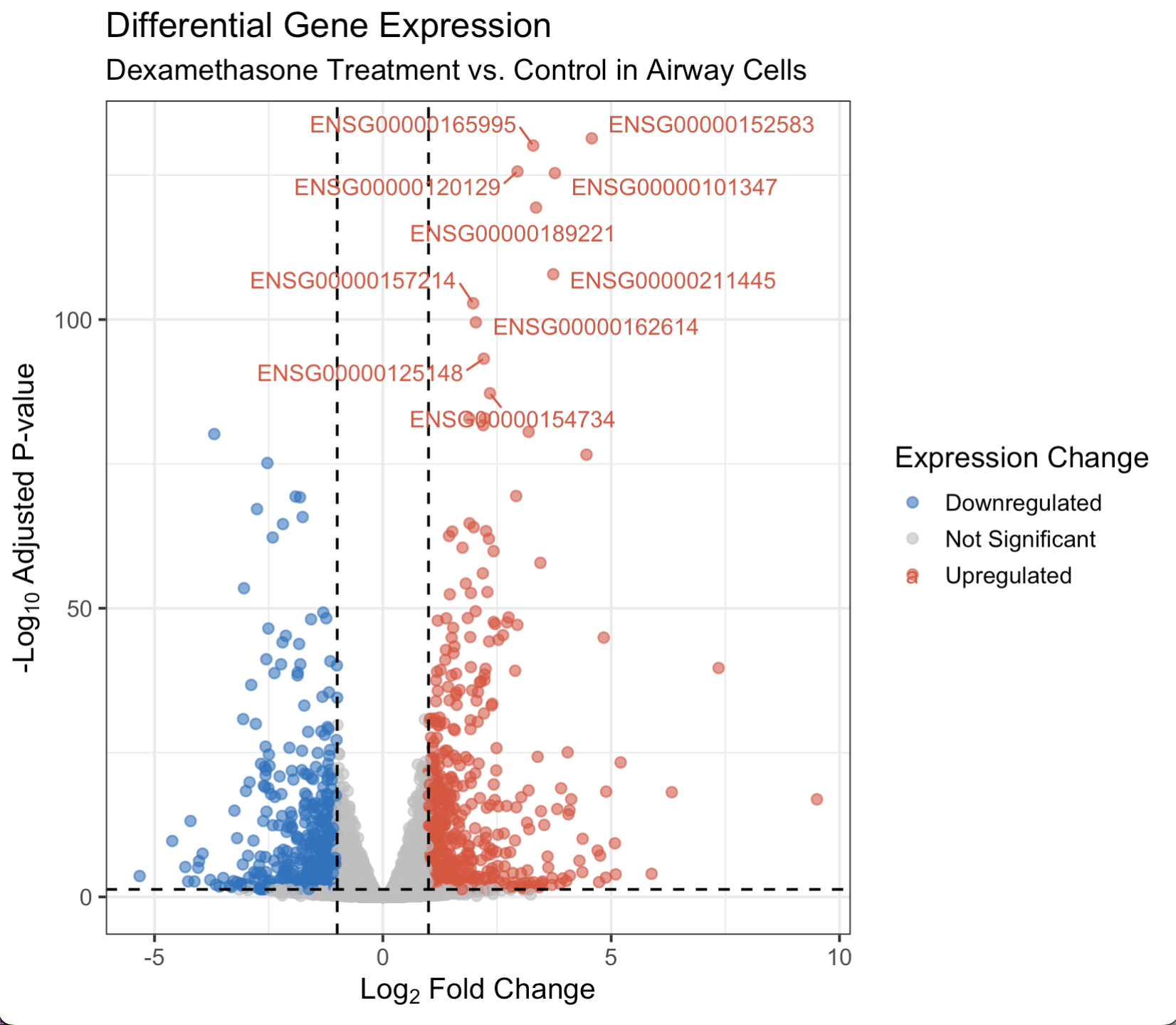
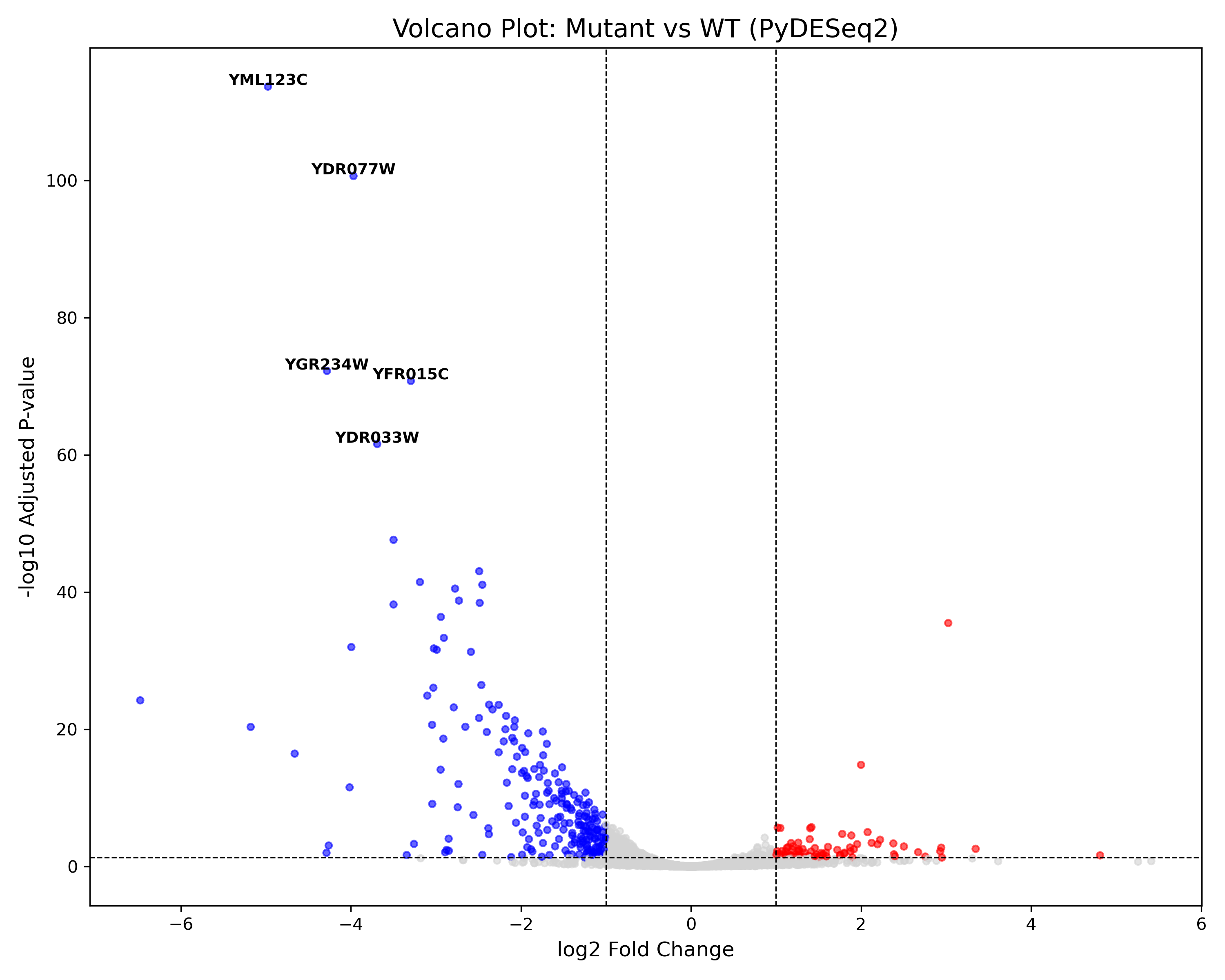
Volcano Plot 시각화
Volcano Plot이란 수많은 변수들 중 통계적으로 유의미한 변화를 보이는 데이터를 직관적으로 식별하기 위해 사용하는 산점도(Scatter plot)의 일종이다. 이름처럼 화산이 폭발하는 듯한 모양을 띄고있다.주로 두 그룹(ex. 실험군 vs 대조군)간의 유전자 발
DEG Analysis (Differentially Expressed Genes Analysis)
1. DEG Analysis DEG(Differentially Expressed Genes) 란 차등 발현 유전자라고 하며 서로 다른 조건의 샘플 그룹 간에 발현량이 통계적으로 유의미한 차이를 보이는 유전자를 의미한다. 예를 들어, 암세포와 정상 세포 간에 유전자 발현 차이를 비교하여 암세포에서 높은 수준으로 발현되는 유전자들을 찾는 경우가 있다. DEG...
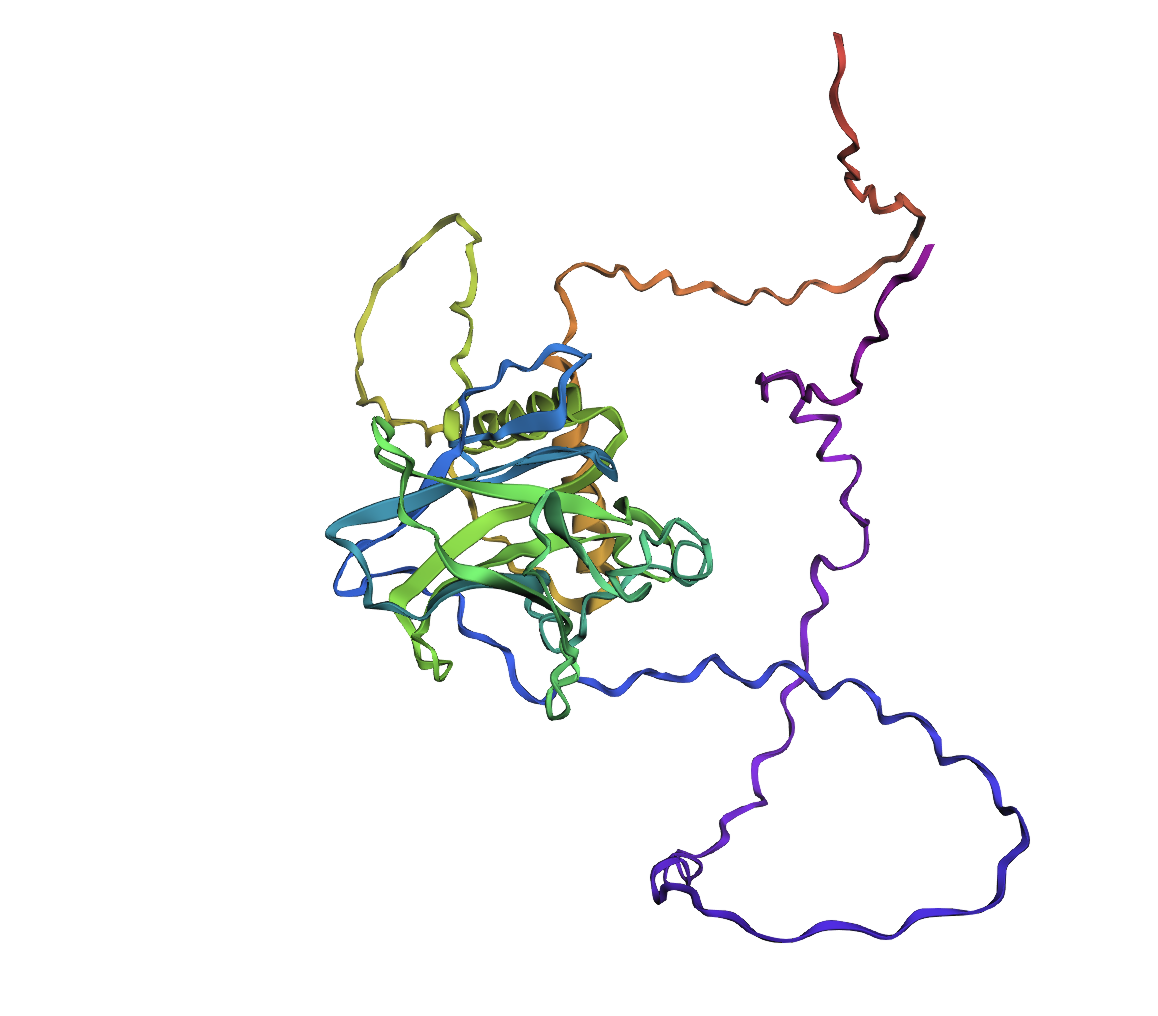
p53 단백질 3D 모델링
단백질 3D 구조(Protein 3D Structure) 란 아미노산 서열이 3차원 공간상에서 접혀서(folding) 만들어내는 고유한 입체구조를 의미한다. 단백질은 이. 입체 구조를 형성해야 비로소 생명 활동에 필요한 기능을 수행할 수 있으므로, 그 구조를 이해하는
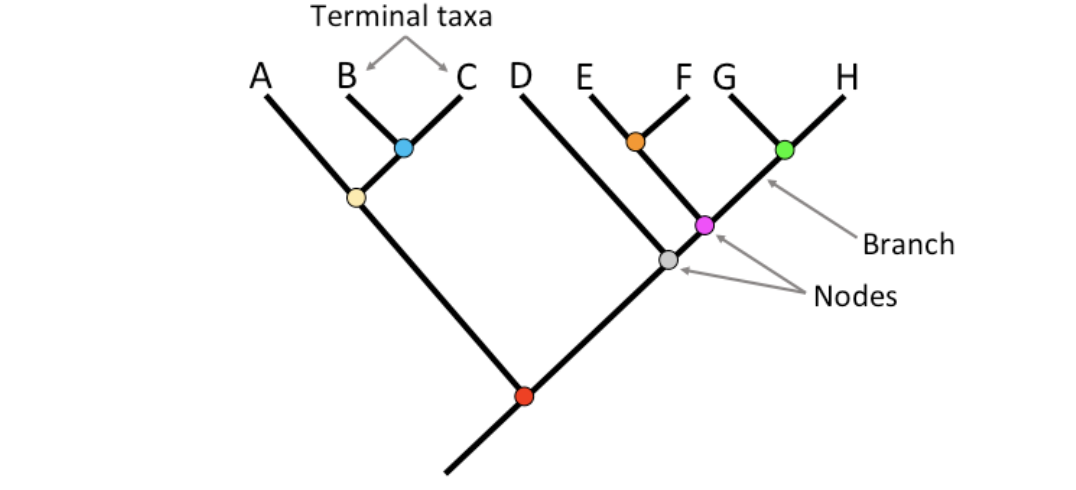
계통수(Phylogenetic Tree) 그리기
계통수(Phylogenetic Tree) 란 생물학에서 여러 종(또는 개체군, 유전자 등)들이 진화 과정에서 어떻게 갈라져 나왔는지, 그들 사이의 진화적 관계와 유연관계를 Tree 형태로 나타낸 그림이다.Branch : 선으로 표현되며, 각 종이나 그룹 간의 진화적 경
다중 서열 정렬(MSA)로 p53 단백질 서열 비교하기
다중 서열 정렬(MSA) 는 셋 이상의 DNA 또는 단백질 서열을 가져와, 진화적으로 동일한 위치(상동 부위)를 찾아 나라히 정렬하는 분석 기법이다.다중 서열 정렬의 주요 목적진화적 관계 추정 : 여러 종에 걸쳐 보존된 서열 영역을 분석하여 계통 발생 관계(Phylog
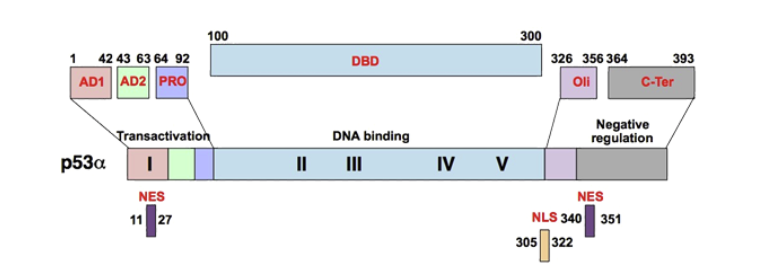
TP53 유전자를 이용한 BLAST 실습
TP53 유전자는 DNA 손상을 복구하거나, 복구가 불가능할 경우 세포 사멸을 유도하여 암을 억제하는 '게놈의 수호자'라고 불리는 중요한 유전자 이다. 이 유전자에 돌연변이가 발생하면 DNA 손상을 입은 세포가 계속 증식하여 다양한 종류의 암 이 발생할 수 있으며 ,
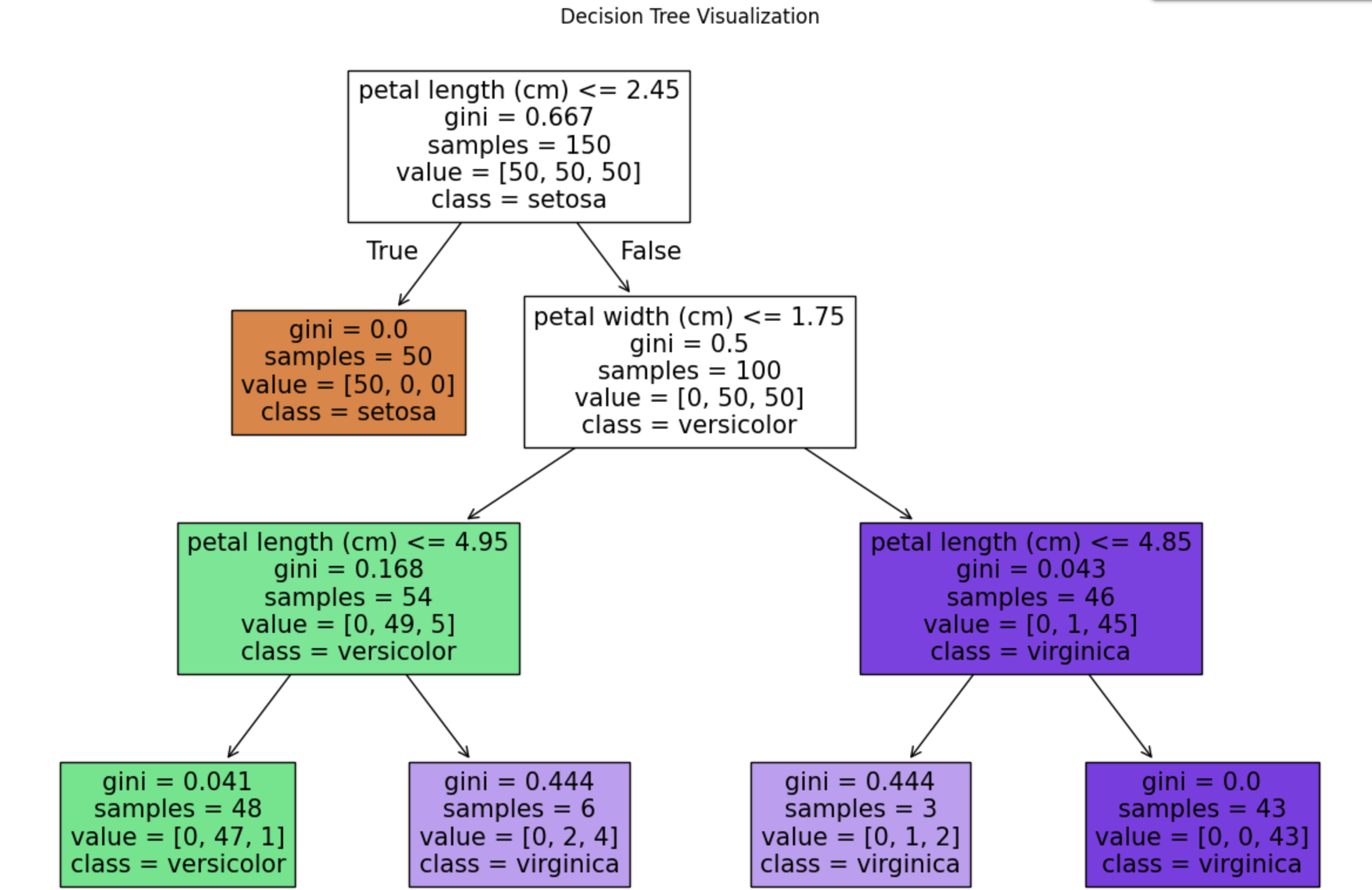
결정 트리(Decision Tree) 와 랜덤 포레스트 (Random Forest)
결정 트리(Decision Tree) 는 '의사결정 규칙'을 'Tree' 자료구조로 표현 한 모델이다. 모델은 데이터에 대해 연속적인 질문을 던져가며 가중치를 보정하고, 끝내 데이터가 어떤 그룹에 속하는지 분류 하거나 어떤 값인지(회귀) 에 대한 결론에 도달한다.위에
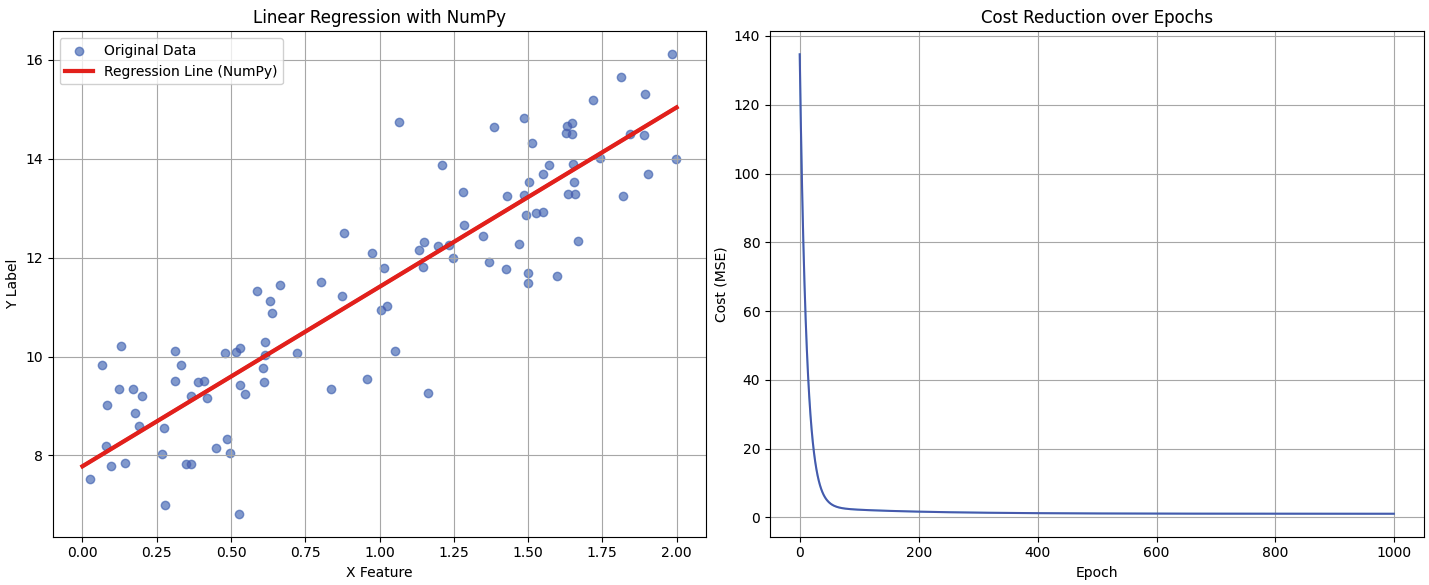
경사 하강법(Gradient Descent)
경사 하강법의 목표는 비용 함수(Cost Function)의 값을 최소로 만드는 파라미터를 찾는 것이다.먼저 최적화 할 대상인 직선의 방정식을 정의하겠다.$$H(x) = Wx +b$$그리고, 비용 함수는 MSE를 사용하여 정의하겠다 .$$J(W,b) = \\frac{1
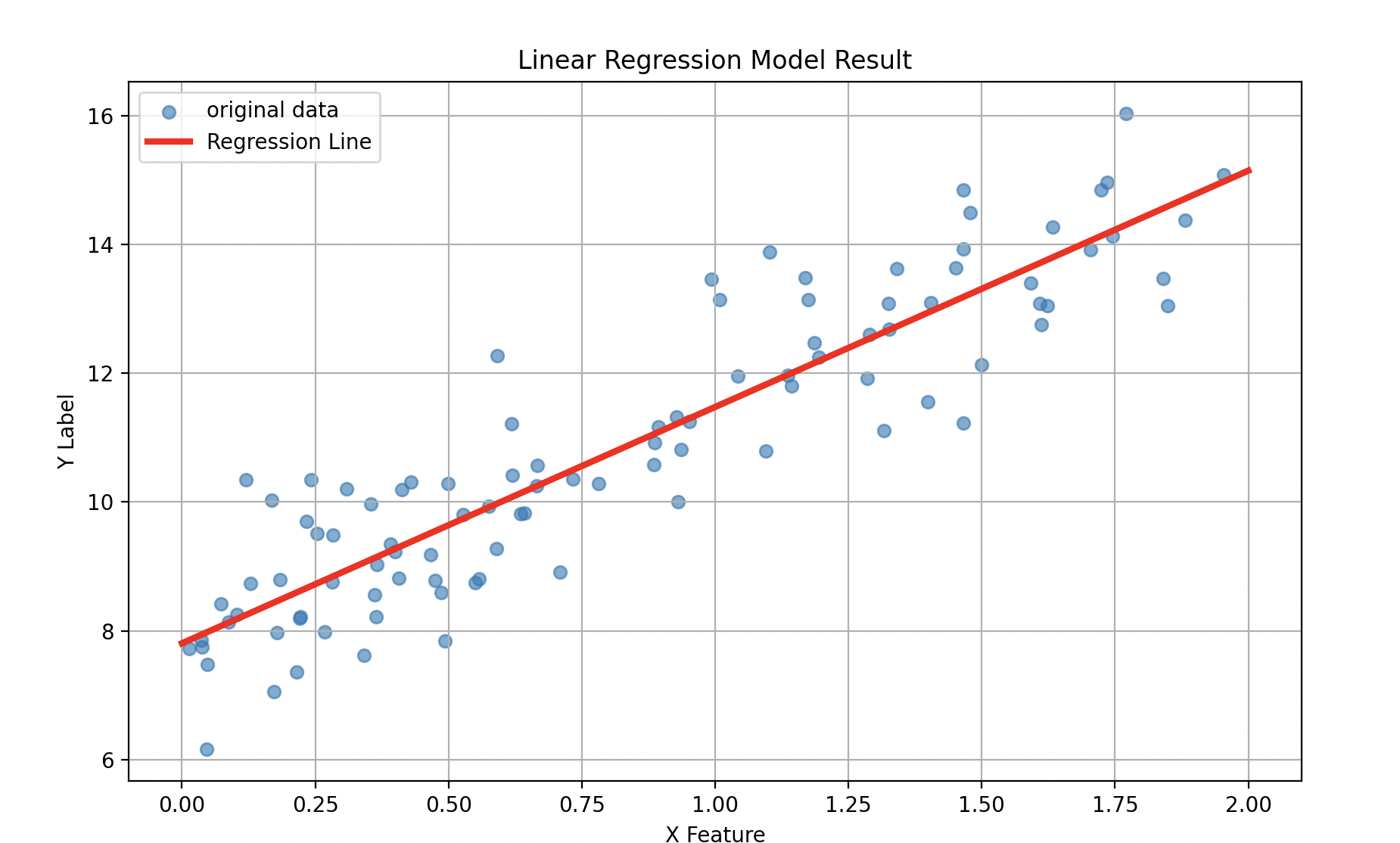
선형 회귀(Linear Regression)
선형 회귀(Linear Regression)이란 머신러닝 중 연속적인 숫자 값을 예측하고 싶을 때 사용하며 주어진 데이터를 가장 잘 설명하는 직선 하나를 찾는 것 이다.독립 변수 (X) : 원인이 되는 데이터 ( ex. 공부 시간 )종속 변수 (Y) : 결과가 되는 데