
- 전체보기(22)
- NLP(2)
- Computer Vision(1)
- Object Detection(1)
- YOLOv8(1)
- DETR(1)
- 스터디(1)
- colorization(1)
- transformer(1)
- semantic segmentation(1)
- inference strategies(1)
- end-to-end(1)
- Fully Convolutional Networks(1)
- fcn(1)
- UNet(1)
- image segmentation(1)
Colorful Image Colorization(2016)
이 논문에서의 colorization의 목표는 Ground Truth와 같은 색을 에측하는 것보다는 '그럴듯한' 색으로 예측하는 것이다. 이 문제를 해결하기 위해서 Colorization문제를 분류 문제로 제기함으로써 불확실성을 수용하고 색상 다양성을 높였다.CIE L

TabNet : Attentive Interpretable Tabular Learning (2020)
TabNet: Tabular 데이터 학습을 위한 새로운 딥러닝 아키텍처Sequential attention: 각 결정 단계에서 활용할 feature을 선택학습 효율성: 딥러닝 모델이 중요한 특징에 학습 자원을 집중해석 가능성: 모델의 의사결정을 로컬(개별 샘플) 및 글
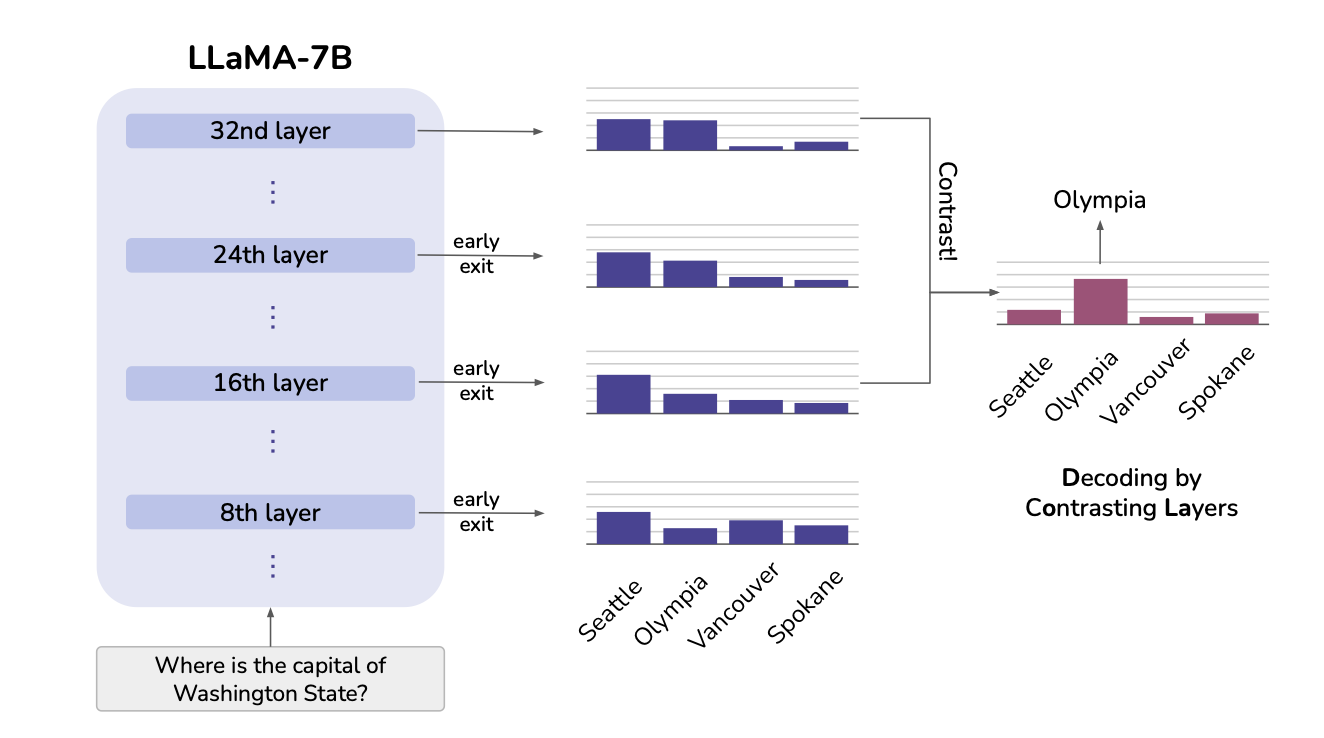
DOLA: DECODING BY CONTRASTING LAYERS IMPROVES FACTUALITY IN LARGE LANGUAGE MODELS
대규모 언어 모델(LLM)은 자연어 처리(NLP) 분야에서 혁신적인 성과를 보여주고 있지만, 환각(hallucination) 문제로 인해 신뢰할 수 없는 결과를 생성하는 경우가 많습니다. 이러한 문제는 특히 의료나 법률과 같은 고위험 분야에서 큰 장애 요인이 됩니다.

Why are Sensitive Functions Hard for Transformers?(2024)
트랜스포머는 자연어 처리와 기타 다양한 분야에서 뛰어난 성능을 보여주었지만, PARITY와 같은 민감도가 높은 이진 함수를 학습하는 데 어려움을 겪습니다. 이 논문은 트랜스포머의 구조적 한계와 학습 편향을 수학적으로 분석하여, 트랜스포머가 민감도가 높은 함수를 학습하기

GLUE: A Multi-Task Benchmark and Analysis Platform for Natural Language Understanding
0. Abstract 자연어 이해(Natural Language Understanding)기술은 특정 기능,장르,데이터셋에 국한되지 않게 언어를 처리할수 있어야 합니다. 따라서 해당 논문은 다양한 자연어 이해 영역에서의 성능 지표를 위해서 탄생한 일반어 이해평가(G
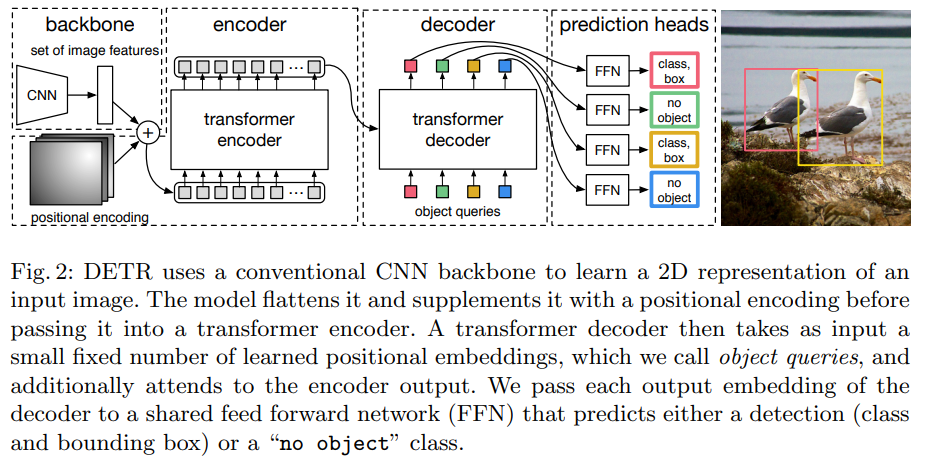
End-to-End Object Detection with Transformers(DETR)
오늘 review해 볼 논문은 2020년도에 나온 DETR입니다!제목 : End-to-End Object Detection with Transformers(DETR)저자 : Nicolas Carion et al.학회 : EECV 2020게제 년도 : 2020년인용수 :

BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
BERT는 unlabeled text 로부터 deep bidirectional representations을 사전 학습후 이를 Downstream Task에 파인튜닝 할수 있게 설계된 모델이라고 설명합니다.

SkipNet(2017): Learning Dynamic Routing in Convolutional Networks
오늘 리뷰할 논문은 skipnet이다. layer를 건너뛰어서 연산량을 줄이는 아니디어를 사용했다는 점이 마음에 들었다.논문의 저자는 resnet의 아이디어를 차용해서 skipnet을 만들었다고 한다.residual block 앞에 skip-gate를 두어 해당 블럭을
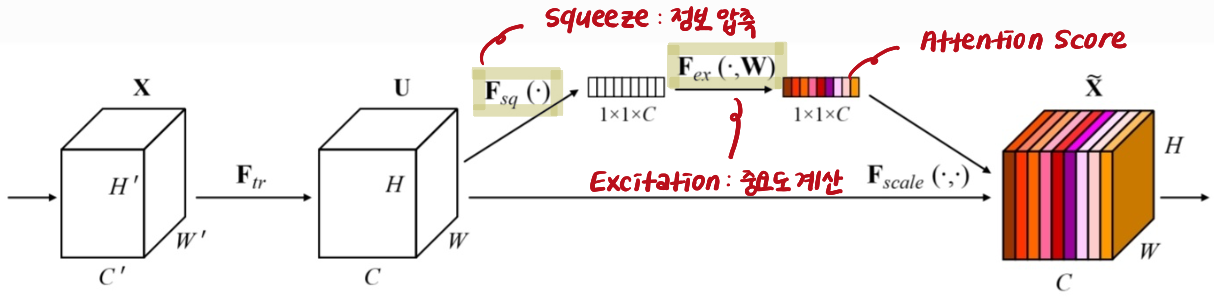
SENet(2018), Squeeze-and-Excitation Networks
SENet이 해결하고자 했던 기존 CNN 방식의 문제점에 대해 살펴보겠다.여기서 기존 방법이란 Convolution, Activation, Pooling, 그리고 Fully Connected Layer로 구성된 전통적인 CNN 구조를 의미한다. 이러한 CNN을 사용하여
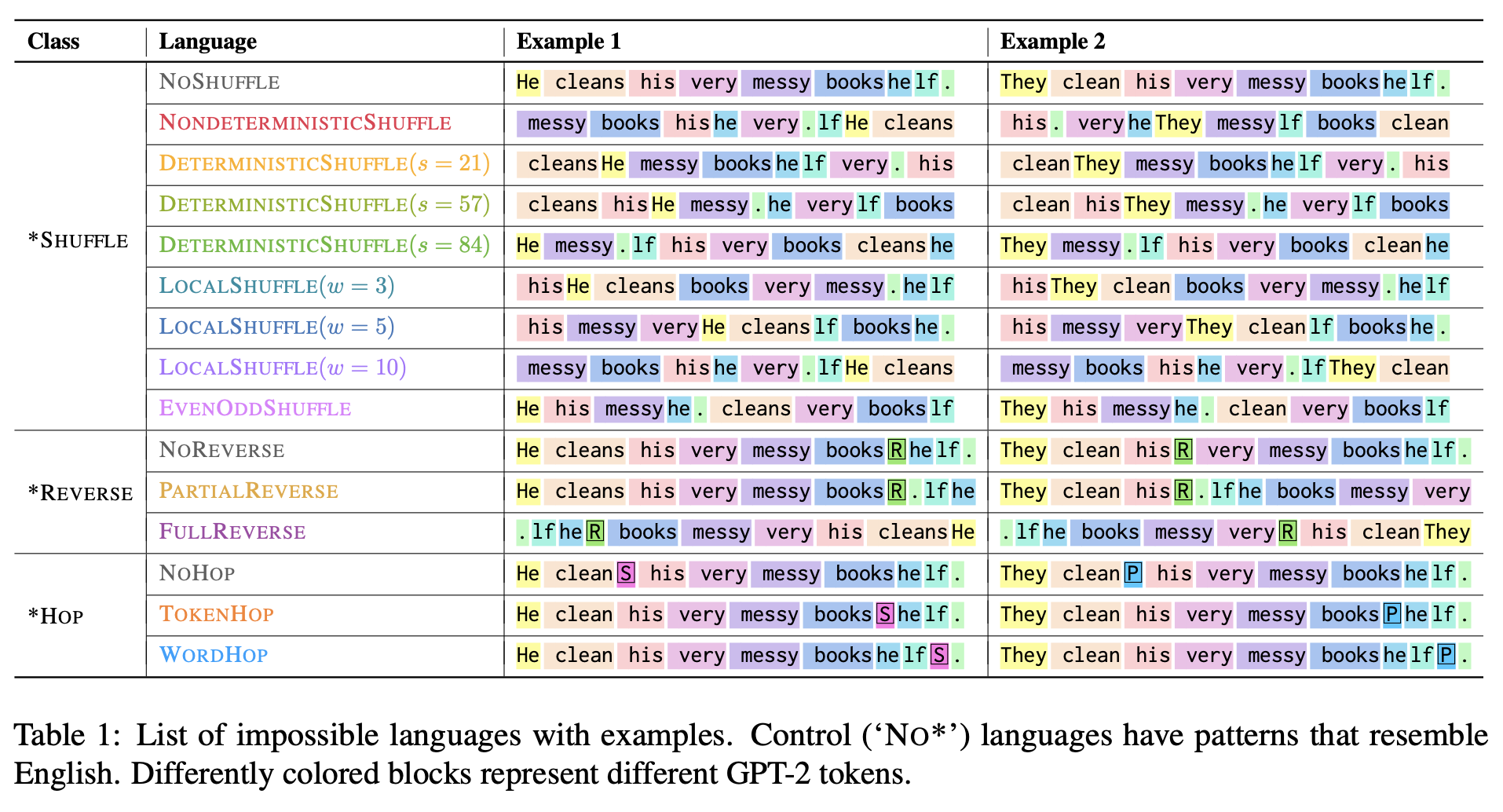
Mission: Impossible Language Models
Chomsky를 포함한 여러 이론가들은 대형 언어 모델(LLMs)이 가능한 인간 언어와 불가능한 언어를 동일하게 학습할 수 있다고 주장하였음. 이 주장은 언어 모델이 언어학 연구에서 유효한 도구가 되지 못한다는 결론을 뒷받침하는데, 본 논문에서는 이러한 주장의 타당성을
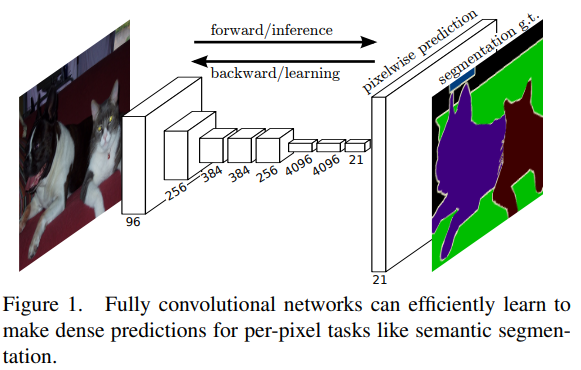
FCN : Fully Convolutional Networks for Semantic Segmentation
오늘 review해 볼 논문은 2015년도에 나온 Fully Convolutional Networks for Semantic Segmentation입니다!논문 제목 : Fuuly Convolutional Netwokrs for Semanctic Segmentation저

Real-Time Flying Object Detection with YOLOv8(2023)
공식논문이 없는 YOLOv8을 공부해보기 위해서 Real-Time Flying Object Dtection with YOLOv8논문을 공부해봤다
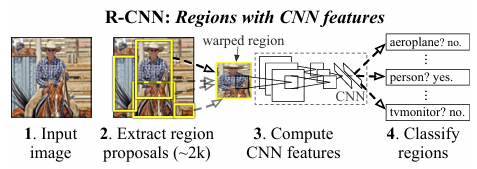
Rich feature hierarchies for accurate object detection and semantic segmentation 2014 (R-CNN)
Object Detection 모델은 객채의 위치를 찾고(Localization), class를 분류(Classification) 하는 작업을 진행합니다. R-CNN 모델은 이를 순차적으로 진행하는 대표적인 2 stage detector로, 딥러닝을 적용한 최초의 O

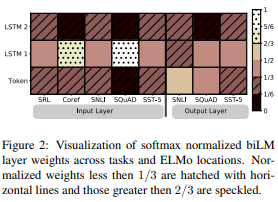
ELMo(2018): Deep Contextualized Word Representation
새로운 형태의 깊은 문맥화된(deep contextual-ized) 단어 표현을 소개하며, 이 표현이 두 가지 주요 문제를 해결한다고 설명한다:단어 사용의 복잡한 특성 모델링: 여기에는 구문적(syntax) 및 의미적(semantics) 특성이 포함된다. ELMo 단어

Depth Map Prediction from a Single Image using a Multi-Scale Deep Network
스테레오 이미지의 경우 지역적인 정보만으로 깊이 추정이 가능하지만 Monocular와 같은 경우 더 다양한 단서로부터 전역, 지역적인 정보를 통합해야 하므로 더 어렵다. 따라서 이 논문에서는 두개의 deep network를 사용하여 이러한 문제를 해결하였고, 스케일
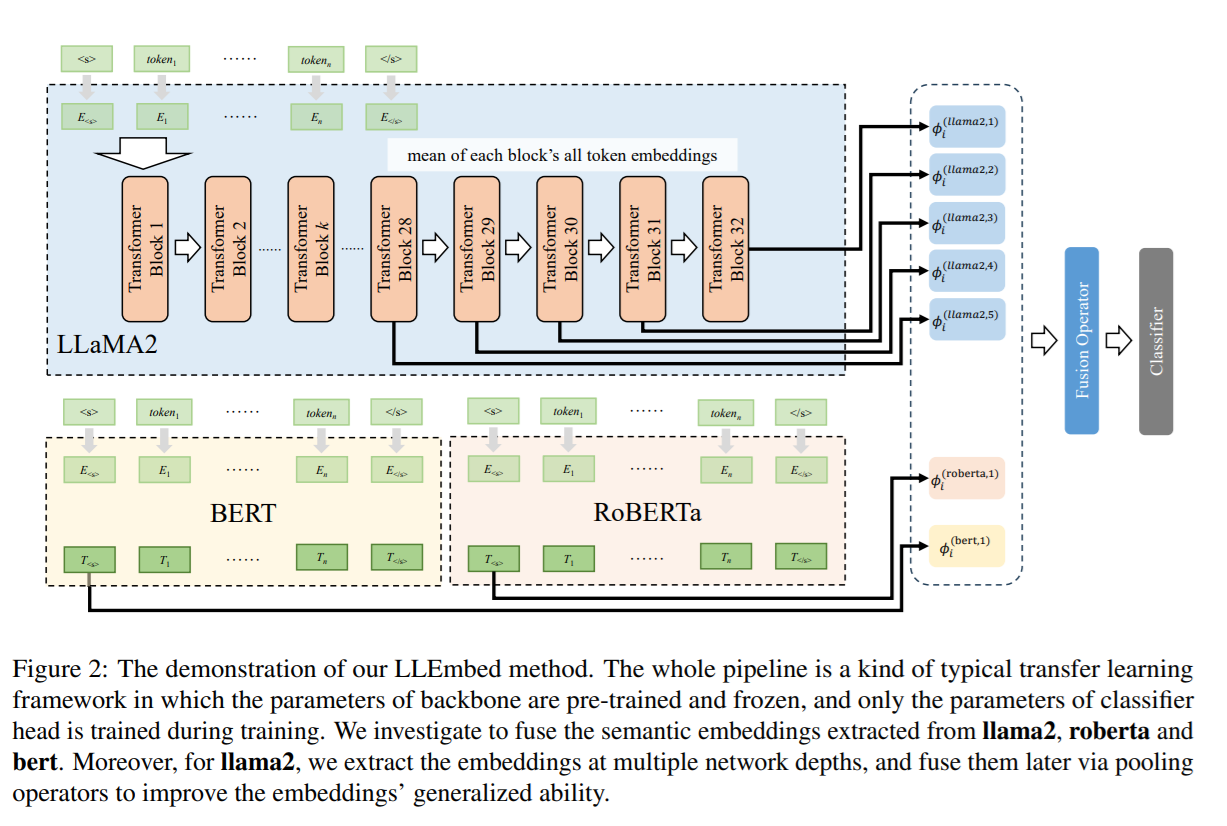
LLMEmbed: Rethinking Lightweight LLM’s Genuine Function in Text Classification (ACL 2024)
LLMEmbed: Rethinking Lightweight LLM’s Genuine Functionin Text Classification모델 크기의 증가로 인한 inference 지연 → LLM은 성능이 뛰어나지만, 파라미터 수가 늘어나면서 추론 시간이 길어짐.

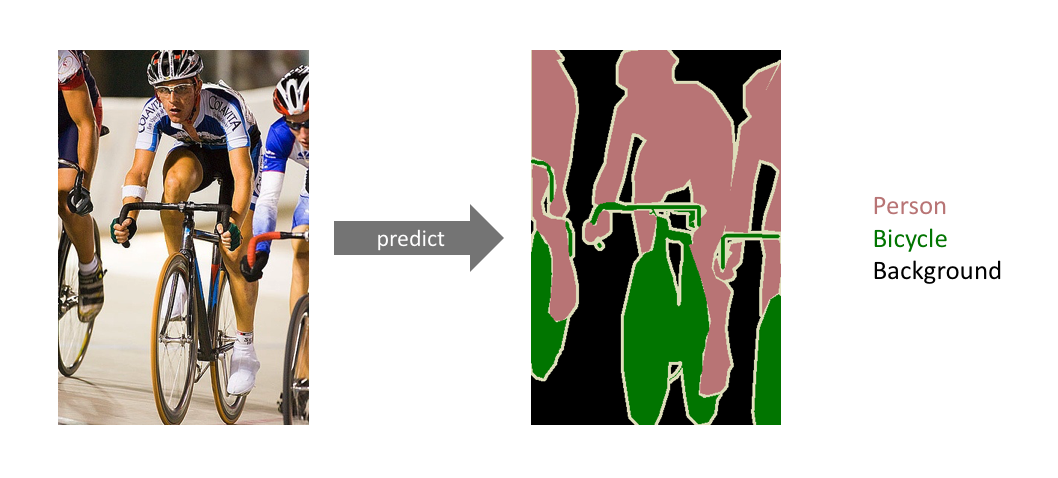
U-Net : Convolutional Networks for Biomedical Image Segmentation(2015)
오늘 review해 볼 논문은 2015년도에 나온 U-Net입니다!제목 : U-Net : Convolutional Networks for Biomedical Image Segmentation저자 : Olaf Renneberger et al.학회 : Medical Ima

Transformer(2017): Attention Is All You Need
전통적인 방식의 RNN 또는 LSTM과 같은 신경 망을 사용한 seq2seq 는 순차적 데이터를 처리할 수 있기 때문에 번역 또는 언어 모델링과 같은 작업에 사용되어 왔으나 이러한 모델은 입력 시퀀스가 길어질수록 Long-Term Dependency 와 Vanishin