
- 전체보기(81)
- 딥러닝(27)
- 인공지능(26)
- 파이썬(24)
- 넘파이(21)
- 머신러닝(18)
- 판다스(12)
- 배열(12)
- 리스트(11)
- pandas(11)
- 인공신경망(9)
- 객체(7)
- 글쓰기(7)
- 데이터(6)
- 생각(6)
- 수학(6)
- 쓰기(6)
- python(5)
- 기하(5)
- 인생(5)
- 작문(5)
- dataframe(5)
- 미적분(5)
- 경사하강법(5)
- 편미분(5)
- 행렬(5)
- AI(4)
- 클래스(4)
- 데이터프레임(4)
- 함수(4)
- 독서(3)
- 빅데이터(3)
- ML(3)
- 신경망학습(3)
- 손실함수(2)
- 선형회귀(2)
- 퍼셉트론(2)
- 인덱스(1)
- 역사(1)
- 비지도학습(1)
- 모듈(1)
- 파라미터(1)
- axis(1)
- 방향미분(1)
- 그룹화(1)
- 공부(1)
- 사이킷런(1)
- 경제(1)
- xlxs(1)
- 행동변화(1)
- 학습(1)
- 지도학습(1)
- 선형대수(1)
- 강화학습(1)
- sqld책(1)
- gradient(1)
- 디지털(1)
- 시리즈(1)
- 2차원 배열(1)
- 미분(1)
- sqld독학(1)
- 관성끊기(1)
- SQLD(1)
- series(1)
- csv(1)
- 컬럼(1)
- SQLD수험서(1)
- 계획(1)
2026 하계 모각코 - 5회차 (결과)
정보시스템 구축 관리 과목에서는 소프트웨어 개발 방법론 활용, IT 프로젝트 정보 시스템 구축 관리, 소프트웨어 개발 보안 구축, 시스템 보안 구축에 관한 내용을 학습하였다. 소프트웨어를 개발하고 운영하는 과정에서 필요한 관리 절차와 보안 기술을 단순히 암기하는 것이
2026 하계 모각코 - 5회차 (계획)
정보시스템 구축 관리 과목에서 소프트웨어 개발 방법론, IT 프로젝트 관리, 소프트웨어 개발 보안 및 시스템 보안에 대한 학습 진행소프트웨어 개발 방법론 활용소프트웨어 생명주기의 단계와 폭포수·프로토타이핑·나선형·애자일 방법론의 특징을 비교하고, 프로젝트의 규모와
2026 하계 모각코 - 4회차 (결과)
1. 정보처리기사 취득 준비 프로그래밍 언어 활용 과목에서는 서버 프로그램 구현, 프로그래밍 언어 활용, 응용 소프트웨어 기초 기술 활용에 관한 내용을 학습하였다. 단순히 프로그래밍 문법을 암기하는 것에 그치지 않고, 프로그램이 서버와 운영체제에서 실행되고 데이터를
2026 하계 모각코 - 4회차 (계획)
프로그래밍 언어 활용 과목에서 아래 주제들에 대한 학습 진행서버 프로그램 구현사용자의 요청을 받아 데이터를 처리하고 결과를 반환하는 서버 프로그램의 기본 동작 과정 학습공통 모듈 구현여러 기능에서 반복적으로 사용하는 코드를 모듈로 분리하여 재사용성과 유지보수성 향상서버
2026 하계 모각코 - 3회차 (결과)
소프트웨어 개발 방법론 활용에서는 소프트웨어를 체계적으로 개발하기 위해 적용하는 개발 절차와 방법론을 학습하였다. 구조적 방법론, 정보공학 방법론, 객체지향 방법론, 애자일 방법론 등 다양한 개발 방법론의 특징을 살펴보고, 프로젝트의 목적과 환경에 따라 적절한 방법론을
2026 하계 모각코 - 3회차 (계획)
정보시스템 구축 관리 과목에서 아래 주제들에 대한 학습 진행1장 소프트웨어 개발 방법론 활용2장 IT 프로젝트 정보 시스템 구축 관리3장 소프트웨어 개발 보안 구축4장 시스템 보안 구축코딩테스트 문제 풀이를 진행 <Queue·Stack> 유형기본 스택후입선출 구조

2026 하계 모각코 - 2회차 (결과)
정보처리기사 취득 준비제품 소프트웨어 패키징에서는 개발이 완료된 소프트웨어를 사용자가 설치하고 사용할 수 있도록 구성하는 과정을 학습하였다. 특히 배포 파일 구성, 설치 절차, 패키징 시 고려해야 할 보안 및 호환성 요소를 이해하였다.제품 소프트웨어 매뉴얼 작성에서는
2026 하계 모각코 - 2회차 (계획)
소프트웨어 설계 과목에서 아래 주제들에 대한 학습 진행Section 01 제품 소프트웨어 패키징Section 02 제품 소프트웨어 매뉴얼 작성Section 03 제품 소프트웨어 버전 관리Section 01 애플리케이션 테스트 케이스 설계Section 02 애플리케이션

2026 하계 모각코 - 1회차 (결과)
요구사항 개발에서는 사용자의 요구사항을 수집, 분석, 명세, 확인하는 절차를 학습하였다. 특히 기능 요구사항과 비기능 요구사항의 차이를 이해하고, 요구사항이 명확하게 정의되어야 이후 설계와 구현 과정에서 오류를 줄일 수 있다는 점을 배웠다.UML에서는 시스템의 구조와
2026 하계 모각코 - 1회차 (계획)
정보처리기사 취득소프트웨어 설계 과목에서 아래 주제들에 대한 학습 진행요구사항 개발UMLUI 환경 분석UI 표준 및 지침

2026 하계 모각코 - 전체 목표
2026 하계 모각코 목표는 다음과 같다.일부 전산직 및 금융공기업에서 코딩테스트를 필요로 하는 경우가 있다. 코딩테스트 학습을 진행할 것이다.방학 기간을 활용하여 정보처리기사를 취득하고, 전공 공부 내용을 정리할 예정이다.

2026 동계 모각코 - 6회차 (결과)
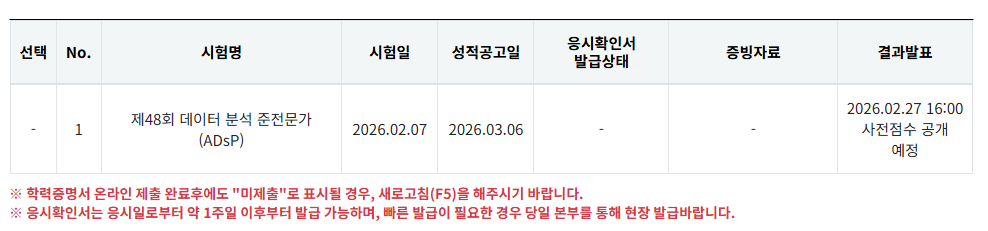
부제 : 2026 동계 모각코를 마무리하며ADsP 자격증 취득모각코 활동 지원비로 교재를 구매할 수 있다고 하여, 자격증 취득을 위한 이론서를 구매했다. 학습을 위한 지원금이 제공되어 좋았다.시험은 지난주 토요일, 2/7일날 응시했다. 채점은 2월 말까지 마무리 된다고
2026 동계 모각코 - 6회차 (계획)
모각코의 마지막 회차 계획은 우선 아래 활동들에 대한 매듭을 짓겠다. 또 6주동안의 모각코 활동을 되돌아 보며 그동안 내가 공부했던 것들에 대해 정리해볼 것이다. ADsP 자격증 취득 (2/7 시험을 응시했다) CS224 Machine Learning with Gra

[도서리뷰] 2026 이기적 SQLD 이론 + 기출문제 구매 후기
최근 영진닷컴 이기적 교재로 ADsP를 공부하며, SQLD 자격증도 취득해볼까 생각을 했고 마찬가지로 영진닷컴 교재로 선택했다. 여러 이유가 있겠지만, ADsP 교재를 구매했던 기준과 같이 적절한 분량과 충분한 연습문제를 풀 수 있다는 점이 마음에 들었다.학습하기에 너

[서평] 관성끊기 (빌 오한론)
빌 오한론, 『관성 끊기 - 반복된 문제를 부수는 최소한의 행동 설계법』우리는 살아가면서 수많은 문제를 마주친다. 물론 그리 중요하지 않거나 쉽게 해결되는 문제도 있지만, 일부 문제는 지속적으로 삶에 등장하여 우리를 괴롭게 만들기도 한다.그런 문제는 보통, 우리의 행동

2026 동계 모각코 - 4회차 (계획)
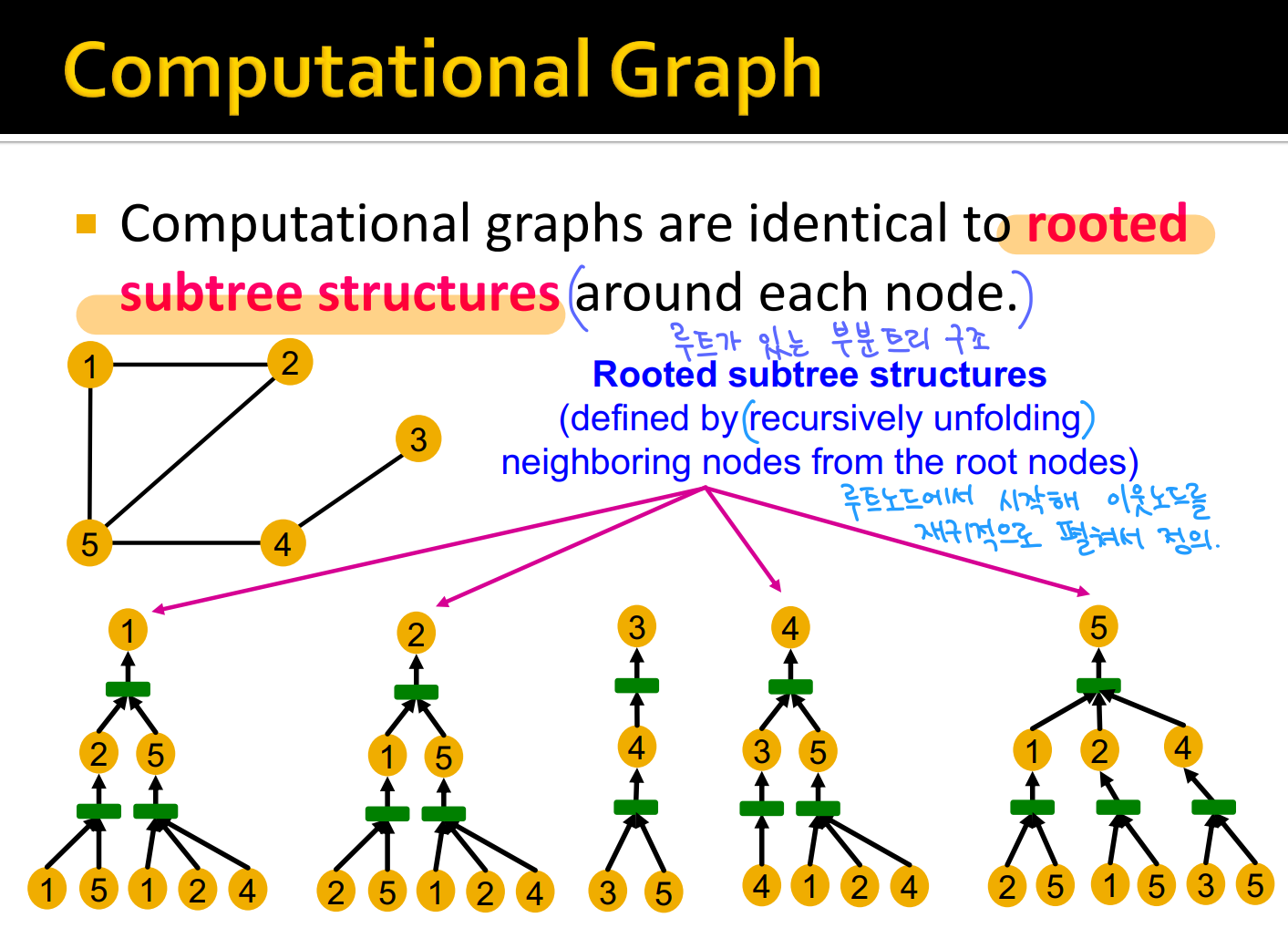
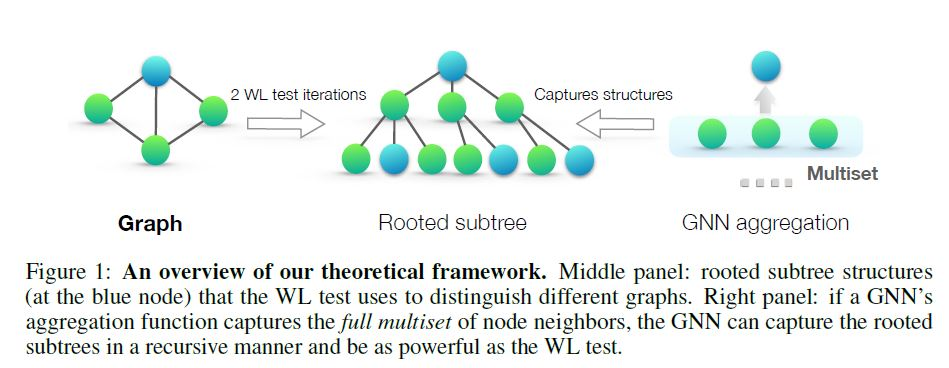
Stanford CS224W 강의 수강 GNN을 위한 증강 기법, 학습 기법 등에 대해서 공부해볼 계획이다. 세부 학습 소주제는 다음과 같이 계획하였다. GNN Augumentation and Training Prediction with GNNs Virtual n

2026 동계 모각코 - 3회차 (결과)
아래 주제들에 대한 학습을 진행하였습니다. ![](https://velog.velcdn.com/images/jhdai_ly/post/26827783-5c42-4b28-aaaa-0299c