

RT-1 : Robotics Transformer for Real-World Control at Scale
방대하고 다양하면서 task가 명확하게 정의되지 않은 데이터셋을 통해 지식을 전이함으로서 현대 머신러닝 모델들은 zero shot이나 작은 task 맞춤형 데이터만으로도 하위 작업들을 잘 해결할 수 있다. 이 능력은 CV, NLP 등에서는 충분히 입증되었지만, 로봇 분
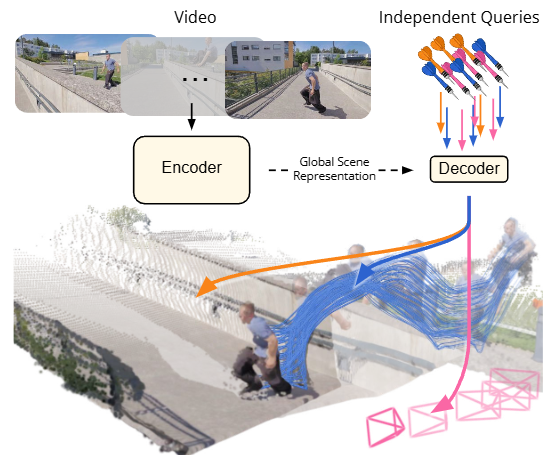
Efficiently Reconstructing Dynamic Scenes One D4RT at a Time
비디오에서 장면의 복잡한 기하학과 모션을 이해하고 재구성하는 것은 컴퓨터 비전 분야에서 여전히 까다로운 과제이다. 본 논문은 이 과제를 해결하기 위해 D4RT 모델을 소개하고, 이 모델은 단일 비디오로부터 depth, 시공간적 대응, 카메라 파라미터를 동시에 추론한다.
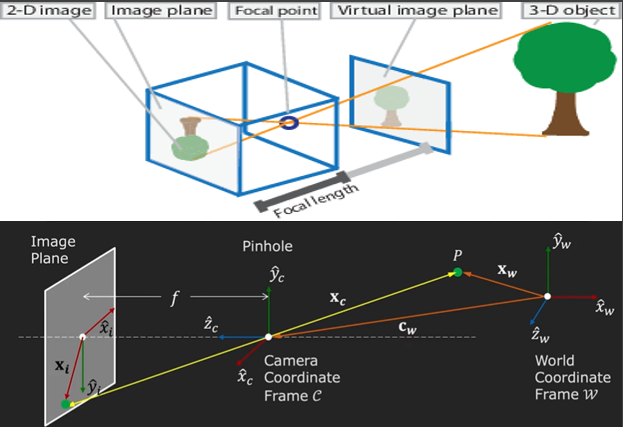
Camera calibration
카메라 캘리브레이션은 카메라의 parameter를 추정하는 과정이다. 이는 실세계의 3D point와 이미지 상의 2D 좌표 간의 정확한 관계를 결정하는데 필요한 카메라의 모든 정보를 의미한다.전체적인 흐름은 아래 그림과 같다.한 물체를 구멍에 관통시키면 이미지 형태로
MedSAM2 : Segment Anything in 3D Medical Images and Videos
SAM (Segment Anything Model)과 같이 특정 task에 맞춰진 모델에서 광범위한 task를 수행할 수 있는 foundation 모델 개발로 패러다임이 전환됐다. SAM은 이미지 분할 task에서 놀라운 결과를 보였지만, 의료 도메인은 자연 도메인과

SAM2 : Segment Anything in Images and Videos
Segment Anything Model (SAM)은 이미지에 대해 프롬프트를 기반으로 segmentation을 할 수 있는 foundation model이다.하지만 이미지는 현실 세계의 정적인 snapshot일 뿐이다. AR/VR, 로보틱스, 자율주행, 비디오 편집,
Depth Anything : Unleashing the Power of Large-Scale Unlabeled Data
컴퓨터 비전, 자연어 처리 분야 모두 다양한 downstream tast를 zero / few-shot으로 해결하는데 기여하는 foundation model을 개발하기 위해 많은 연구를 진행하고 있다.본 논문은 어떠한 이미지에 대해서도 depth를 예측할 수 있는 mo
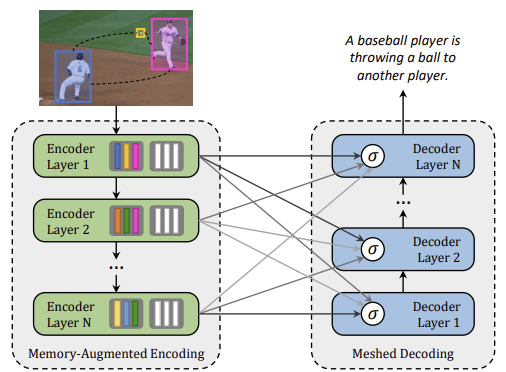
Meshed-Memory Transformer for Image Captioning
Transformer 기반의 구조는 번역과 같은 시퀀스 모델에서 최고의 성능을 보여줬지만, image captiong과 같은 multi-modal task에서는 아직 충분한 연구가 수행되지 않았다.본 논문은 image captioning task를 수행하기 위한 Mes
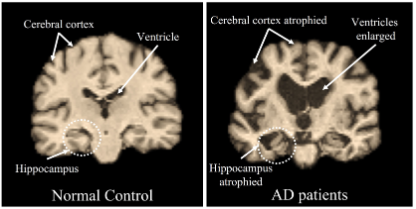
M3T : three-dimensional Medical image classifier using Multi-plane and Multi-slice Transformer
본 논문은 2D CNN (Convolutional Neural Network), 3D CNN, Transformer를 조합하여, 3D MRI 이미지를 통해 알츠하이머 증상 (Alzheimer Disease, AD)를 분류해내는 모델을 제안한다.제안된 모델은 이전 3D

CLIP : Learning Transferable Visual Models From Natural Language Supervision
CLIP 이전에 제안된 computer vision 기술들은 사전에 정의된 클래스만 예측할 수 있도록 훈련을 진행한다. 이러한 제한된 형식은 추가 레이블에 대해서는 추론이 불가능하므로 유용성이 떨어진다고 볼 수 있다.하지만 만약 이미지를 나타내는 텍스트를 통해 모델을
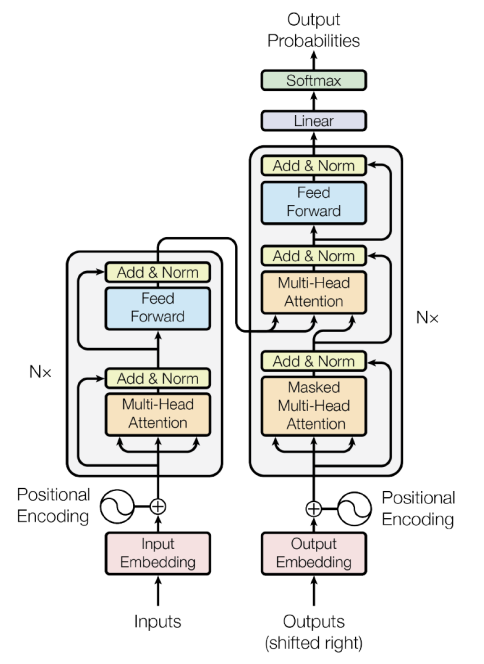
RNN ~ Transformer - (3) Transformer
Transformer 논문의 제목은 'Attention is all you need'이다. 제목에서 알 수 있듯, Transformer는 RNN의 고질적인 문제(기울기 소실, 정보 손실)를 지적하며 기존의 Seq2Seq의 인코더-디코더 구조와 Attention 이론을
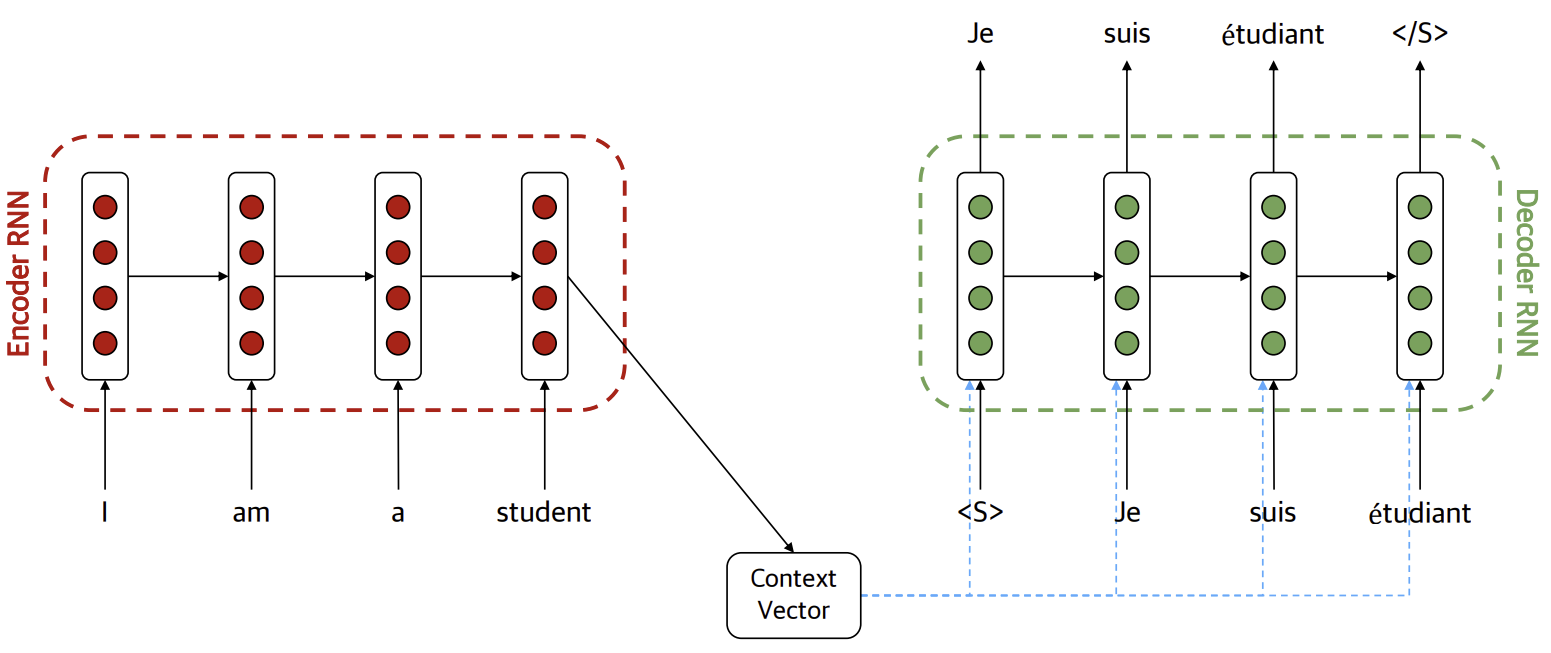

RNN ~ Transformer - (1) RNN
이번 글은 Recurrent Neural Network (RNN)부터 Sequence 2 Sequence (Seq2Seq), Attention, Transformer까지의 전반적인 이론과 각 모델의 등장배경을 다뤄볼 예정이다.최근에 멀티모달 관련 task를 맡아서 수행
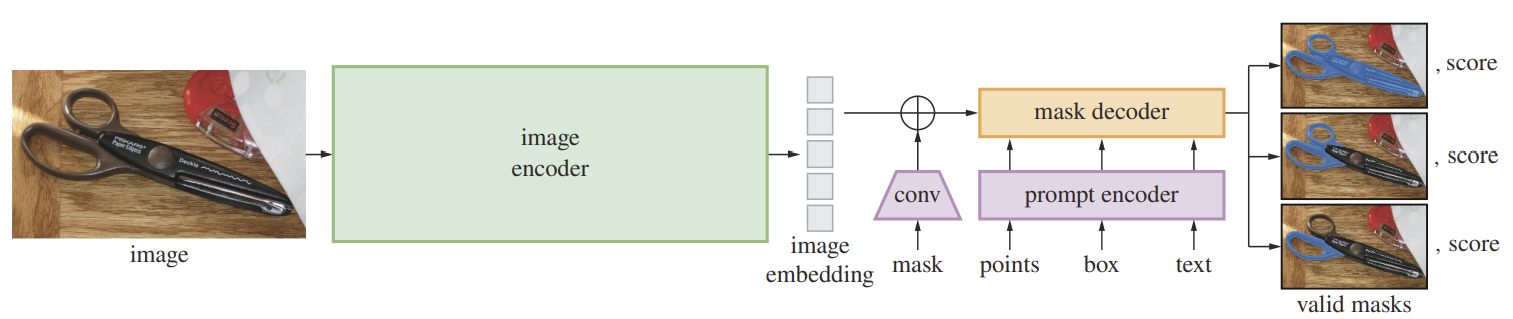
Segment Anything
입력 이미지는 encoder를 통해 $256$차원의 vector로 mapping한다. Encoder는 'Masked Autoencoders Are Scalable Vision Learners'에서 소개한 MAE pre-trained ViT를 사용한다.Encoder를 통
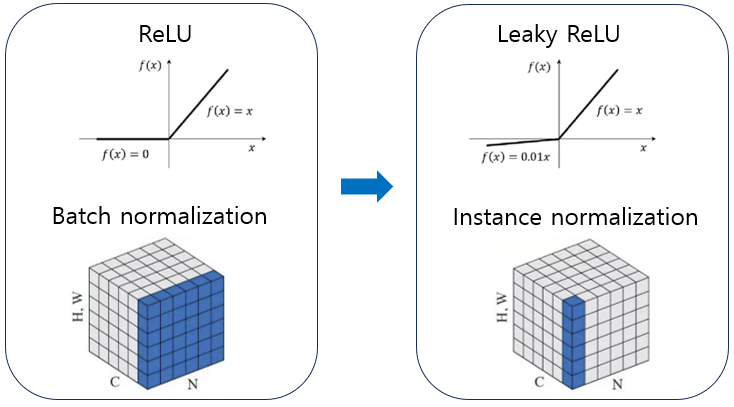
nnU-Net : Self-adapting Framework for U-Net-Based Medical Image Segmentation
CNN 기반의 segmentation 기법은 좋은 성능을 내기 위한 특수한 네트워크 구조 및 다양한 훈련 기법을 요구한다. 하지만 이러한 요소 없이 다른 종류의 다양한 데이터셋에 대해 일반적인 결과를 산출할 수 있는 알고리즘이 필요하다. U-Net은 네트워크 구조를 조

U-Net : Convolutional Networks for Biomedical Image Segmentation
최근에 아산병원에서 MRI 이미지를 이용하여 간암을 분할하는 task를 수행하게 되어 segmentation 논문들을 읽고있다. 오늘은 그 중 한 획을 그엇던 U-Net에 대해 리뷰해볼까 한다.U-Net은 이전에 제안됐던 FCN (Fully Convolutional N
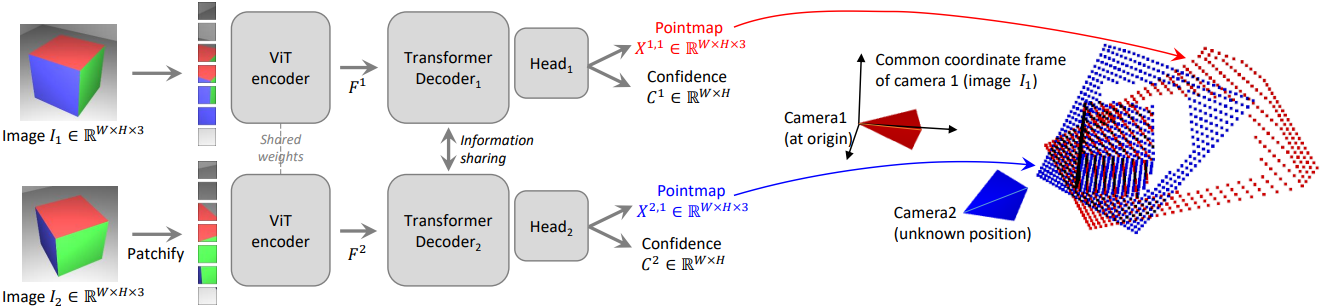
DUSt3R : Geometric 3D Vision Made Easy (진행 중)
Multi-View Stereo (MVS)는 이미지 간의 대응점을 통한 3차원 재구성을 위해 카메라 내부 파라미터와 외부 파라미터를 요구하지만, 이 파라미터를 구하는 과정은 상당히 번거롭다. DUSt3R은 Dense and Unconstrained Stereo 3D R
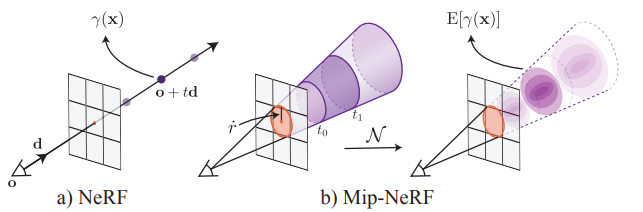
Mip-NeRF : A Multiscale Representation for Anti-Aliasing Neural Radiance Fields
NeRF는 3D object 또는 scene을 촬영한 이미지들로 향하는 ray 위의 점을 샘플링해서 학습한 모델을 이용하여 새로운 시점에 대한 이미지를 렌더링하는 기술이다. 이 기법은 일정한 거리에서 촬영한 이미지들에 대해 좋은 렌더링 결과를 보여줬지만, 가까이에서 바
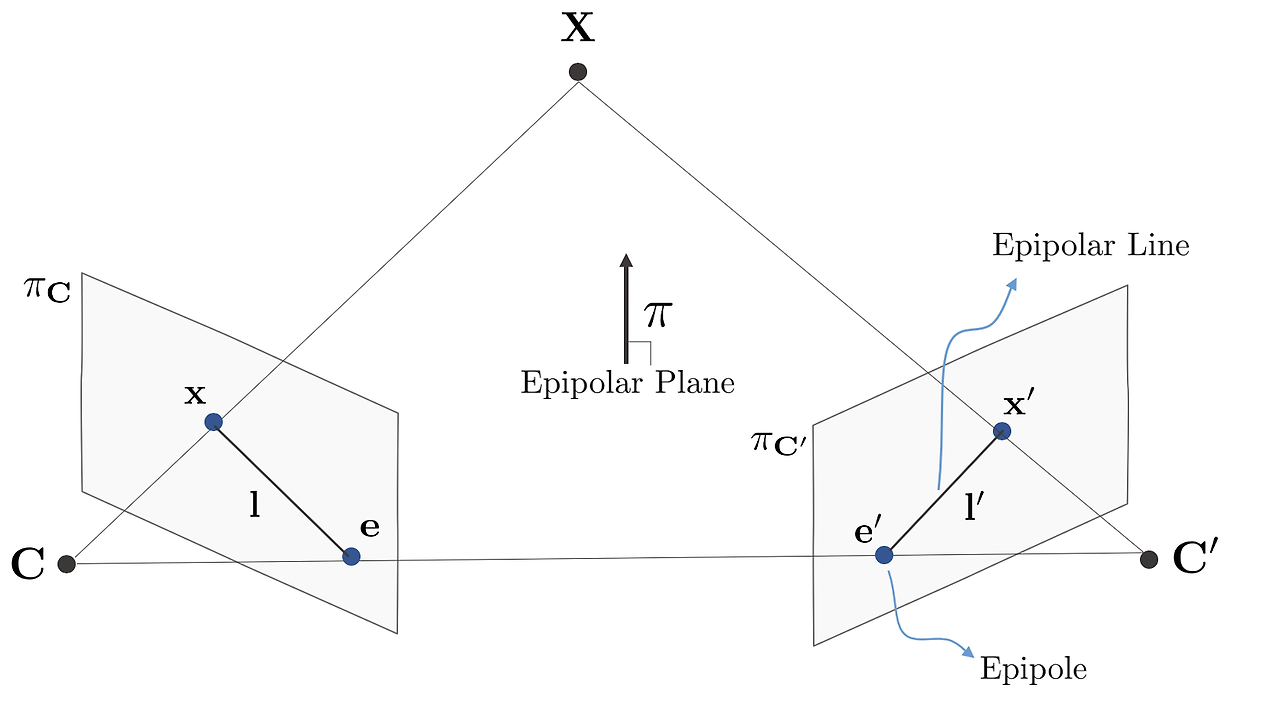
Structure from Motion - Epipolar geometry
3차원 scene과 이 scene을 보고 있는 두 개의 카메라가 있을 때, 우리는 3D 좌표와 각 카메라의 이미지 평면에 투영된 2D 좌표를 이용하여 두 카메라 사이의 기하학적 관계를 설명할 수 있다. 이 두 카메라 사이의 기하학적 관계를 찾는 것을 epipolar g
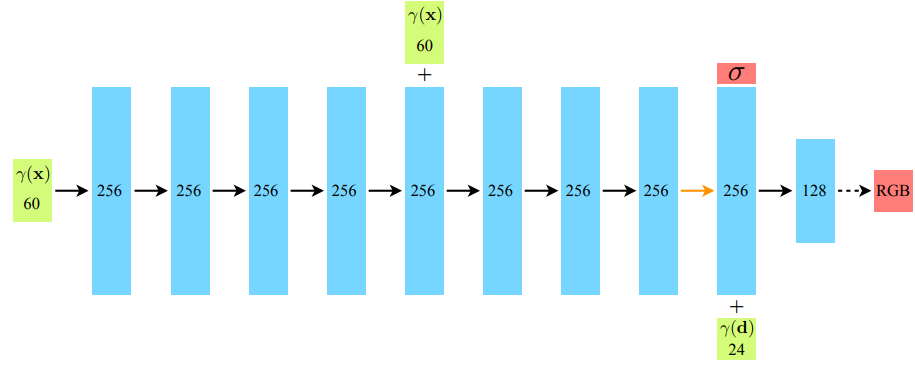
NeRF : Representing Scenes as Neural Radiance Fields for View Synthesis
NeRF (Neural Radiance Field)는 복잡한 scene에 대한 새로운 시점에서의 이미지를 렌더링하는 task (novel view synthesis)를 수행한다. 모델에 5차원의 좌표 정보 (ray의 방향 정보 ($\\theta , \\phi$) 와 r
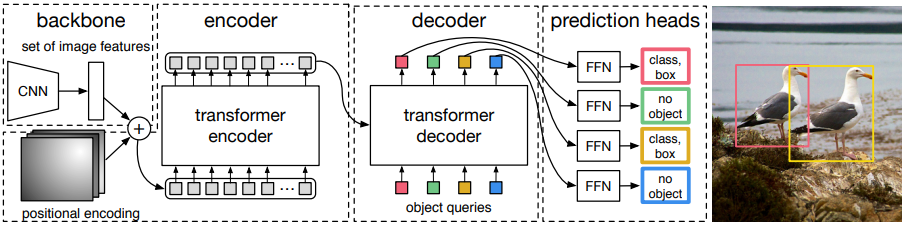
End-to-End Object Detection with Transformers (DETR)
이전까지 제안된 방식들은 객체 인식 task를 해결하기 위해 non-maximal suppression (NMS) 나 spatial anchors 와 같은 사전 지식을 모델에 인코딩해야 했다. 본 논문은 이러한 사전 지식이나 특별한 라이브러리 없이 Transformer