
- 전체보기(96)
- opencv(47)
- 백준(20)
- 딥러닝(11)
- capstonedesign(5)
- python(5)
- tensorflow(4)
- docker(4)
- 백트래킹(3)
- contour(3)
- 그리디알고리즘(3)
- WebCrawling(3)
- hsv(3)
- fasterrcnn(3)
- 필터링(2)
- KNN(2)
- segmentation(2)
- 객체검출(2)
- 브루트포스(2)
- 가우시안필터(2)
- trackbar(2)
- MachineLearning(2)
- instagram(2)
- 동적계획법(2)
- 블러링(2)
- 머신러닝(2)
- 트랙바(2)
- tensorflowobjectdetectionapi(2)
- 평균값필터(2)
- C(2)
- 정렬(2)
- labeling(2)
- MaskRCNN(2)
- N과M(2)
- 색모델(1)
- 트랜스포머(1)
- Pair(1)
- 필기체숫자인식(1)
- Convolution(1)
- duolingo(1)
- 양방향필터(1)
- outputarray(1)
- ObjectDetection(1)
- qr코드검출(1)
- merge(1)
- 히스토그램(1)
- 레이블맵(1)
- ubuntu(1)
- 밝기조절(1)
- QRCodedetector(1)
- optimization(1)
- volume(1)
- PyTorch(1)
- rgb(1)
- AutoEncoder(1)
- rect(1)
- inferencegraph(1)
- selenium(1)
- 기울기폭주(1)
- 명암비조절(1)
- 소벨마스크(1)
- stable_sort(1)
- 컨볼루션(1)
- 유사도(1)
- 적응형이진화(1)
- 외곽선검출(1)
- 외곽선그리기(1)
- 에지검출(1)
- 피보나치수열(1)
- 색공간(1)
- canny(1)
- mat(1)
- DataAugmentation(1)
- inputarray(1)
- windows(1)
- 그레이스케일(1)
- 샤르마스크(1)
- dropout(1)
- knn알고리즘(1)
- utility(1)
- 활성화함수(1)
- 전단변환(1)
- anaconda(1)
- scalar(1)
- setto(1)
- rotatedrect(1)
- Nginx(1)
- 미디언필터(1)
- 원검출(1)
- N-Queen(1)
- 레이블링(1)
- String(1)
- 템플릿매칭(1)
- 그래디언트(1)
- 재귀함수(1)
- Classification(1)
- 손실함수(1)
- 크기변환(1)
- point(1)
- mask(1)
- 외곽선(1)
- Sort(1)
- GradientVanishing(1)
- Torchvision(1)
- 기울기소실(1)
- Size(1)
- FAST코너검출(1)
- bgr(1)
- 해리스코너검출(1)
- 컬러영상(1)
- 미분(1)
- 캐니에지검출기(1)
- 직선검출(1)
- 다이나믹프로그래밍(1)
- 어파인변환(1)
- 엠보싱필터링(1)
- split()(1)
- 샤프닝(1)
- 모폴로지연산(1)
- KNearest(1)
- 투시변환(1)
- 이진화(1)
- 임계값(1)
- 포화연산(1)
- monologue(1)
- RNN(1)
- 언샤프마스크필터(1)
- binary(1)
- Perspective Transform(1)
- 잡음추가(1)
- CNN(1)
- 하루영어기사(1)
- 모폴로지(1)
- KnowledgeTracing(1)
- detector(1)
- 이동변환(1)
- qr코드(1)
- 허프변환(1)
- 필기체숫자(1)
- vec(1)
- 레이블(1)
- algorithm(1)
- 대칭변환(1)
- 코너검출(1)
- GradientExploding(1)
- chromedriver(1)
- range(1)
- gan(1)
- 어텐션(1)
- Least Square Method(1)
- Keras(1)
- 회전변환(1)
- detectron2(1)
- 최적화(1)
- copyto(1)
- binarization(1)
- connectedComponents(1)
- 추론그래프(1)
- contours(1)
- 오토인코더(1)
- 잡음제거필터링(1)
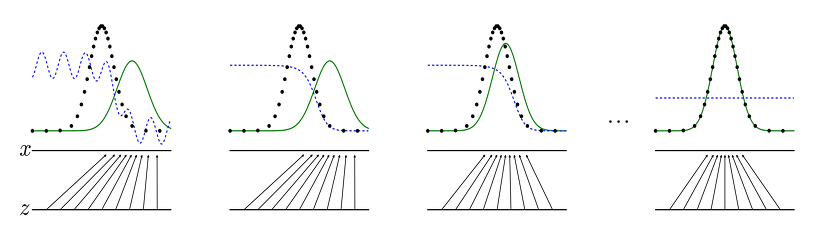
[딥러닝 모델] GAN (Generative Adversarial Network)
GAN은 일반적인 머신러닝에서 예측값을 생성해내는 것과 달리, 데이터의 형태를 만들고자 하는 목적을 가지고 있다. 여기서 데이터의 형태는 분포 혹은 분산을 나타내고, 단순히 결과값을 도출하는 함수가 아닌 실제적인 형태를 갖춘 데이터를 만들어 내는 것이다.위 그림은 GA
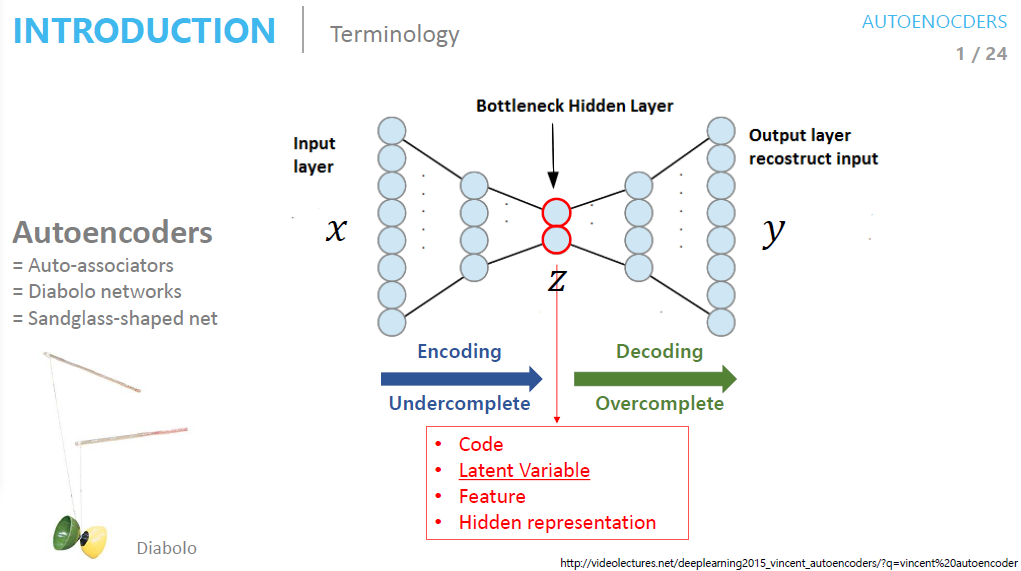
[딥러닝 모델] AutoEncoder
https://deepinsight.tistory.com/126오토인코더(Autoencoder)는 단순히 입력을 출력으로 복사하는 신경망이다. 이 때 hidden layter의 뉴런수를 input layer보다 작게 해서 데이터를 압축하거나 노이즈를 추가해 원
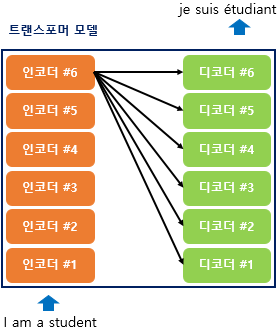
[딥러닝 모델] 트랜스포머 (Transformer)
https://wikidocs.net/31379트랜스포머는 RNN을 사용하지 않지만, 기존 seq2seq 처럼 인코더에서 입력시퀀스를 입력받고, 디코더에서 출력시퀀스를 출력하는 인코더-디코더구조를 가진다. 이전에는 하나의 RNN인 t개의 시점을 가지는 구조였는
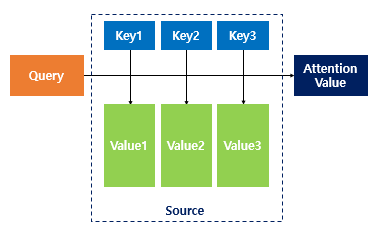
[딥러닝 모델] 어텐션(Attention)
https://wikidocs.net/22893RNN을 기반으로한 언어 모델에서 크게 두가지 문제가 발생했는데, 먼저 하나의 고정된 크기 벡터에 모든 정보를 압축하려고 하니 정보손실이 발생한다는 점과, 기울기 소실(Vanishing Gradient)문제가 발생
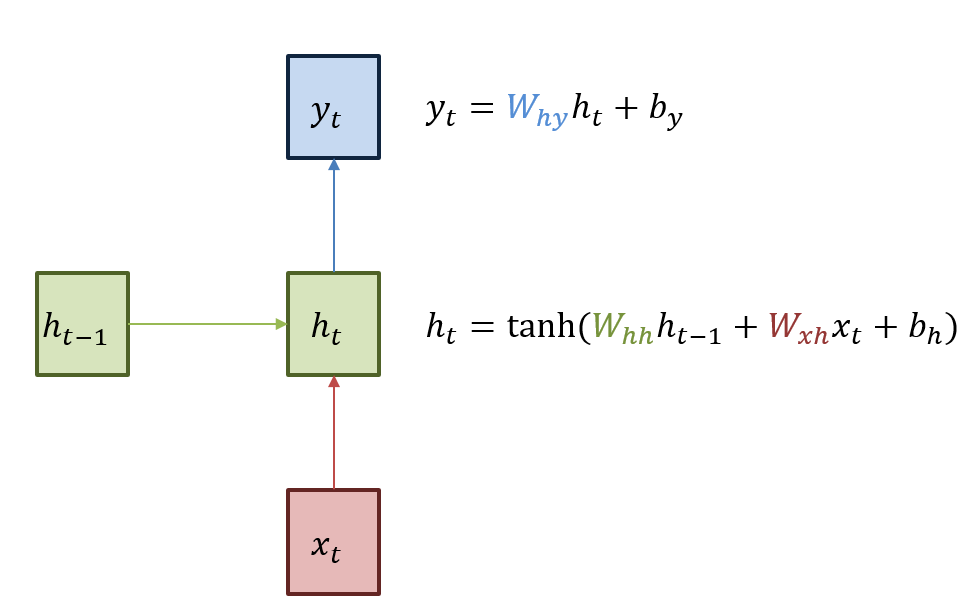
[딥러닝 모델] RNN 과 LSTM
https://wikidocs.net/22886https://ratsgo.github.io/natural%20language%20processing/2017/03/09/rnnlstm/RNN은 입력과 출력을 시퀀스 단위로 처리하는 시퀀스 모델이다. 예를
맞춤형 취약품사 보완 추천 서비스(Duolingo SLAM Data)를 위한 모델 개발 | Knowledge Tracing | Ch.1 데이터 수집 및 전처리
수집된 데이터는 http://sharedtask.duolingo.com/2018.html 2018 Duolingo Shared Task on Second Language Acquisition Modeling (SLAM) 를 위해 제공된 데이터셋을 활용하였습니다. 그 중

[딥러닝 모델] CNN(Convolutional Neural Network)
CNN 쉼게 이해하기 참고 블로그 일반 DNN은 기본적으로 1차원 형태의 데이터를 사용한다. 따라서 이미지가 입력될 경우, 이것을 flatten 시켜서 한줄의 데이터로 만들게 된다. 이 과정에서 이미지의 공간적 정보가 손실되어, 특징 추출과 학습이 비효율적이고 정확도의
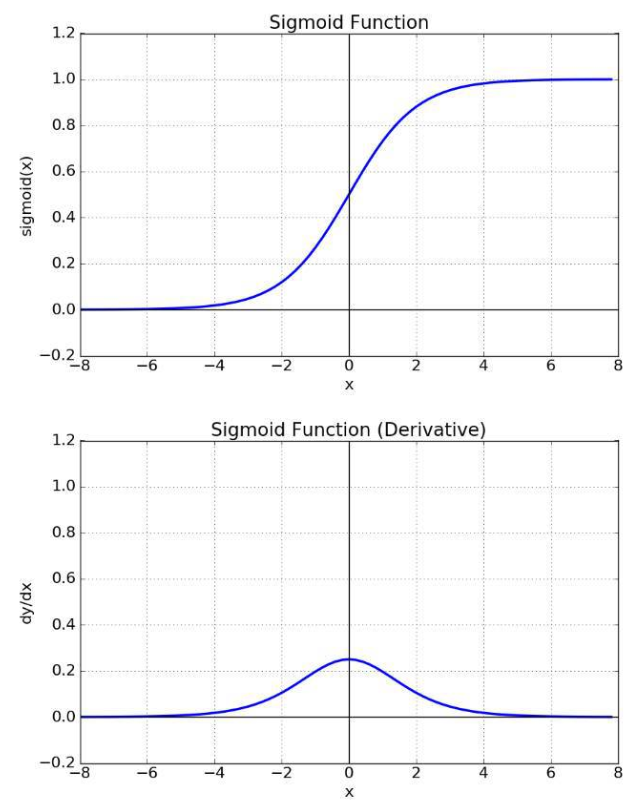
[딥러닝 기초개념] 기울기 소실과 폭주 (Gradient Vanishing / Exploding)
https://wikidocs.net/61375역전파 과정에서 입력층으로 갈수록, 기울기가 점차적으로 작아지는 현상이 발생할 수 있다. 이러한 현상으로 입력층에 가까운 층들에서 가중치들이 업데이트가 제대로 되지 않으면 결국 최적의 모델을 찾을 수 없게 되고,

[딥러닝 기초개념] Dropout
네트워크의 유닛의 일부만 동작하도록하고, 일부는 동작하지 않도록 하는 방법이다.dropout은 1. 오버피팅을 방지하기 위한 방법 중 하나이며, hidden layer의 일부 유닛을 동작하지 않게 하는 것이다.hidden layer에 드롭아웃을 확률 p로 적용할 때,

[딥러닝 기초개념] 최적화 (Optimization)
loss 함수의 최소값을 찾아가는 것경사하강법이란, 네트워크의 파라미터들을 θ(W,b)라 했을 때, Loss function J(θ)의 optima(최소화)를 찾기위해 파라미터의 기울기(gradient)를 이용하는 방법이다.알파는 learning rate에 해당하며,

[딥러닝 기초개념] 손실함수
타켓의 실제값과 도출한 예측값의 차이를 수치화해주는 함수이다. 오차가 클수록 손실함수의 값이 크고, 오차가 작을수록 손실함수의 값이 작아진다. 그래서 모델성능의 '나쁨'의 정도를 나타낼 수 있다.손실함수의 값(loss)을 최소화하는 W(가중치), b를 찾아가는 것이 학
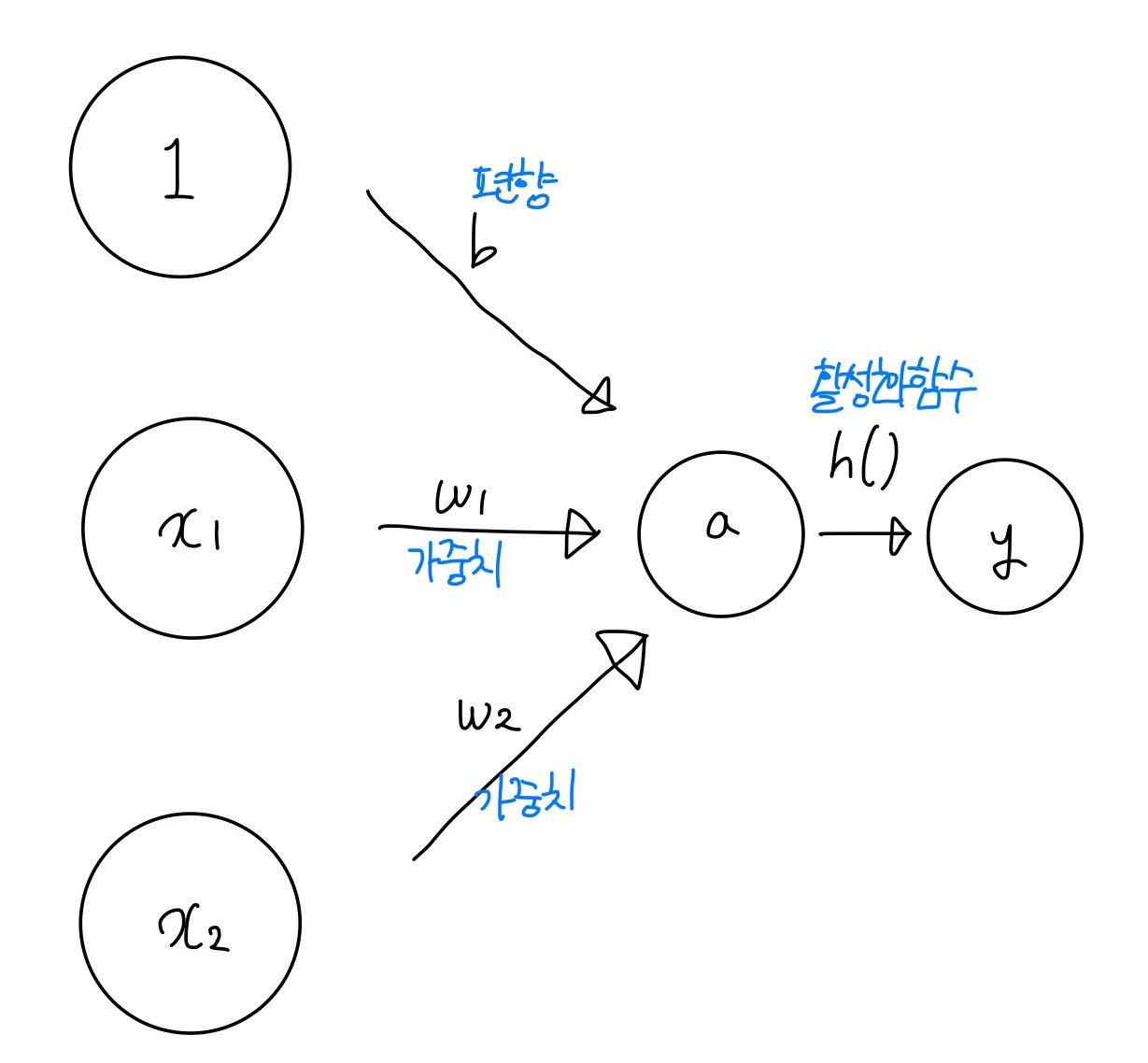
[딥러닝 기초개념] 활성화 함수
우선 퍼셉트론에서, x1와 x2를 입력받아 y를 출력하게 된다. 이때 b라는 편향을 통해 퍼셉트론이 얼마나 쉽게 활성화 되는지에 대한 정도를 결정한다. 편향이 -1000이라면, 입력값이 1000이 넘어야 활성화 될 것이고, 편향이 -10이라면, 입력값이 10만 넘어도

종이 시험지 자동 채점 프로그램 | Tensorflow Object Detection API | Faster R-CNN | Ch4. 항목 감지 모델 학습하고 추론하기
이제 앞에서 문제감지모델을 이용해 문제별로 잘라낸 이미지를 사용할 시간입니다. 사용자가 선택한 답의 번호를 확인하기 위해 문제 속 선택한 항목과 선택하지 않은 항목을 구분하는 것이 필요합니다. 따라서 먼저 앞에서 저장된 이미지들을 라벨링하였습니다.
종이 시험지 자동 채점 프로그램 | Tensorflow Object Detection API | Ch3.5. 모델 학습 후 frozen_inference_graph.pb 로 inference 하기 & 모델 테스트
모델 테스트를 위해서는 다음과 같은 과정이 필요합니다.추론 그래프 추출추론 그래프를 사용하여 객체 검출추론그래프를 추출하기 위해서는 Tensorflow object Detection API에서 제공되는 export_inference_graph.py을 사용하면 됩니다.바
종이 시험지 자동 채점 프로그램 | Tensorflow Object Detection API | Faster RCNN | Ch3. 문제 분류 모델 학습하기
학습을 위한 라벨링 (Labeling) 먼저 이번 챕터에서 진행하는 학습은 촬영된 시험지에 몇개의 문제가 있는지, 그 위치를 파악하기 위한 것입니다. 따라서 앞서 만들어낸 데이터에서 문제 위치를 직접 라벨링해야 했고, 처음에는 CVAT라는 라벨링 툴을 활용하여 라벨
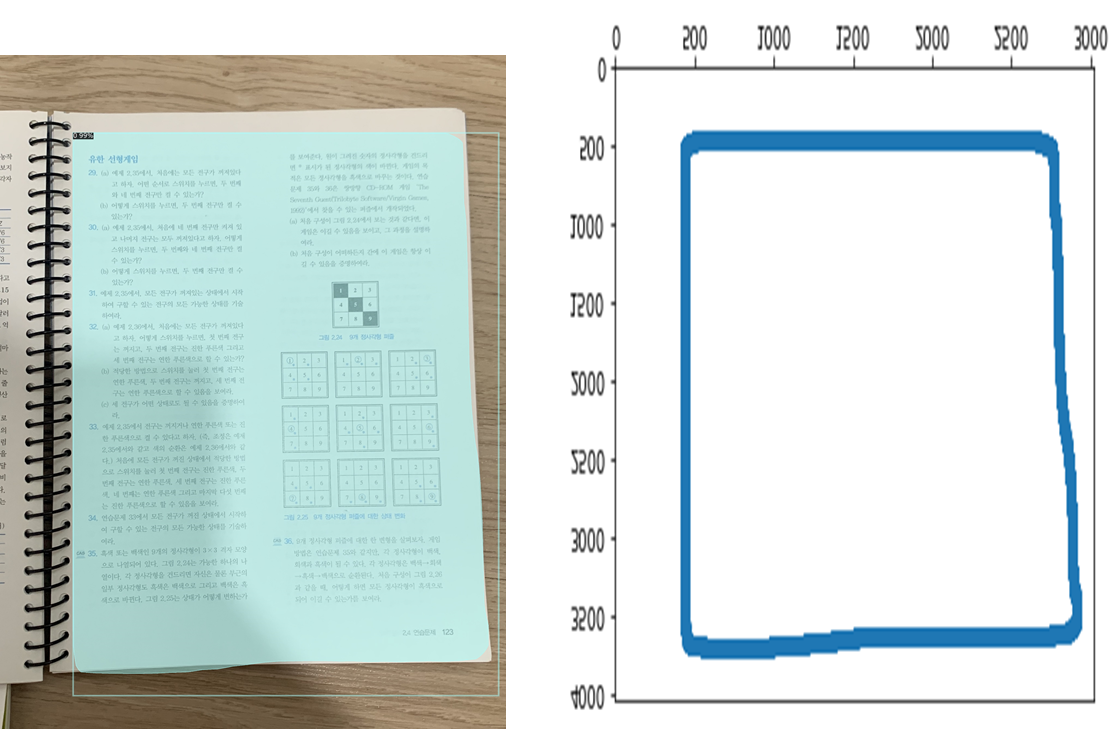
종이 시험지 자동 채점 프로그램 | Least Square Method | Perspective Transform | Ch2.5. 시험지를 평면이미지로 변환하기
먼저 위의 이미지에서 왼쪽 이미지는 segmentation 결과 나타나는 출력 이미지 입니다. 여기서 마스크 행렬을 얻을 수 있고 마스크 범위안은 True, 범위 밖 즉 배경으로 인식한 부분은 False 값으로 저장되어 있습니다. 여기서 마스크 범위 가장자리의 종이의

Faster R-CNN 정리
이번 캡스톤 디자인 프로젝트에서 오브젝트 디텍션을 위해 사용할 모델인 Faster R-CNN을 사용하기 전, 관련내용에 대해 간단히 정리해보기로 했다.참고 영상Faster R-CNN: Towards Real-Time ObjectDetection with Region

종이 시험지 자동 채점 프로그램 | Image Segmentation | Mask R-CNN | Ch2. 이미지에서 배경 자르기
# 2. Mask R-CNN 학습 / 예측 ## 2-1. 라이브러리 설치 저는 Detectron2 라이브러리를 사용하기 위해 먼저 Torchvision을 설치했습니다. ```py # torchvision 설치 !pip install -U torch torchvis
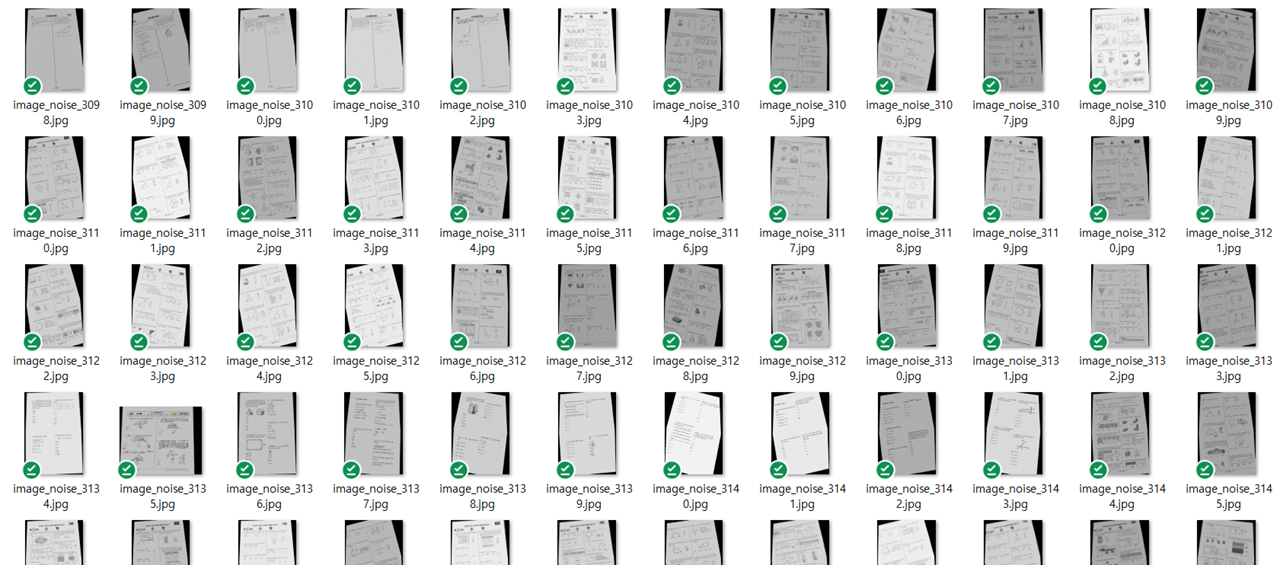
종이 시험지 자동 채점 프로그램 | Data Augmentation | OpenCV | Ch1. 데이터 수집 및 증강
1. 데이터 수집 데이터는 모두 수학시험을 대상으로 수집하기로 했습니다. 모두 객관식으로 이루어진 시험지를 수집했으며, 수집한 데이터는 다음과 같습니다. > 경찰 대학 시험 (수학) 2014~ 9급 공무원 시험 (수학) 2013~ 수능 시험 (수학) 2014~ 모의

Segmentation과 RCNN 모델을 통한 종이 시험지 자동 채점 프로그램 | Tensorflow Object Detection API | Ch0. 계획
현재 저는 중학생 과외를 진행하고 있으며, 교육과 시험에 관심이 자연스럽게 많아지며 교육분야에서 부족한 부분이 무엇인지 생각해보았습니다. 온라인 교육을 통해 모바일로 문제를 묻고 답하는 플랫폼이 있는가 하면, 태블릿 pc 등을 통해 문제를 풀고 쉽게 채점하도록 하는 공