
- 전체보기(145)
- 논문리뷰(33)
- VISION(26)
- NLP(20)
- PyTorch(19)
- opencv(14)
- Robotics(9)
- LLM(9)
- DeepLearning(8)
- transformer(8)
- Image Processing(7)
- 영상처리(7)
- VLA(6)
- Object Detection(6)
- ros2(6)
- ROS(5)
- 시계열 분석(4)
- linux(4)
- YOLO(4)
- ViT(4)
- gan(4)
- rclpy(4)
- LSTM(4)
- GRU(3)
- YOLOv8(3)
- 논문 리뷰(3)
- qwen(3)
- NER(2)
- Manifold Learning(2)
- Calibration(2)
- Nvidia(2)
- ARIMA(2)
- Probability(2)
- cursor(2)
- openapi(2)
- BERT(2)
- isaac-sim(2)
- DETR(2)
- Detection Transformer(2)
- 시각화(2)
- image classification(2)
- 병렬처리(1)
- Seq2Seq(1)
- NaverAPI(1)
- SMOTE(1)
- sam(1)
- n8n(1)
- Vision & Language Model(1)
- rospy(1)
- GAZEBO(1)
- LLaMA(1)
- numba(1)
- word2vec(1)
- SSD(1)
- Action Chunking Transformer(1)
- LDA(1)
- rag(1)
- jetson orin(1)
- LLMs(1)
- agent(1)
- MOT(1)
- EfficientNetV2(1)
- LSTM-CRF(1)
- YOLO9000(1)
- diffusion(1)
- 2023목표(1)
- Hough Transform(1)
- AutoEncoder(1)
- BLIP(1)
- llama.cpp(1)
- humble(1)
- Lane Detection(1)
- PCL(1)
- mediapipe(1)
- GPT-3(1)
- OpenPose(1)
- 가상환경(1)
- AI Studio(1)
- 로지스틱 회귀(1)
- mobilenet-ssd(1)
- grok(1)
- spaCy(1)
- moonlight(1)
- UV(1)
- T5(1)
- Optical Flow(1)
- 비동기(1)
- VLM(1)
- Adversarial attack(1)
- multi-head attention(1)
- YOLO-E(1)
- PPO(1)
- 전이학습(1)
- qwen3-next(1)
- Perplexity(1)
- CoT-VLA(1)
- folium(1)
- outlier detection(1)
- LSA(1)
- biLM(1)
- matlab(1)
- ELECTRA(1)
- 2023_회고(1)
- Imitation Learning(1)
- oversampling(1)
- Smoothing(1)
- uvicorn(1)
- 회고록(1)
- MCP(1)
- BART(1)
- Lora(1)
- 프로그래밍(1)
- XLNet(1)
- Attention(1)
- LLM-planner(1)
- lerobot(1)
- buffalo(1)
- semantic segmentation(1)
- dagger(1)
- edge detector(1)
- PyQT(1)
- JIT(1)
- YOLOv2(1)
- SayCan(1)
- Recommender System(1)
- tensorflow(1)
- Face Recognition(1)
- zero-shot object detection(1)
- act(1)
- KOBERT(1)
- machine learning(1)
- task planning(1)
- alpaca(1)
- AlexNet(1)
- manus(1)
- VGGNet(1)
- clustering(1)
- 2024목표(1)
- Behavior Cloning(1)
- vLLM(1)
- roberta(1)
- 논문읽기(1)
- segment anything(1)
- ZED(1)
- segmentation(1)
- Linear Regression(1)
- Stereo Vision(1)
- YOLOv9(1)
- multimodals(1)
- venv(1)
- Resnet(1)
- YOLO NAS(1)
- RNN(1)
- Embedding(1)
- geopandas(1)
- 리눅스(1)
- feature matching(1)
- sift(1)
- CBOW(1)
- reinforcement learning(1)
- Depth Estimation(1)
- Retrieval Augmented Generation(1)
- sbert(1)
- plotly(1)
- gguf(1)
- rtx5090(1)
- FastAPI(1)
- ELMO(1)
- SARIMA(1)
- ADASYN(1)
- GloVe(1)
- Claude(1)
- DeepSeek-R1(1)
- ALS(1)
- KL-Divergence(1)
- DEEPSEEK(1)
- fasttext(1)
- stitching(1)
- Mobilenet(1)
- dimensionality reduction(1)
- LeNet-5(1)
- Object Tracking(1)
- Gemini(1)
- numpy(1)
- Qwen2.5(1)
- GPT(1)
- contours(1)
- VGG16(1)
- PSPNet(1)
- groundingDINO(1)
- rt-1(1)
- Edge Detection(1)
- 2022회고(1)
- DeBERTa(1)
- LiDAR(1)



PPO: Proximal Policy Optimization Algorithms (2017)
PPO (Proximal Policy Optimization) paper review

DAgger : A Reduction of Imitation Learning and Structured Prediction to No-Regret Online Learning (2011)
A Reduction of Imitation Learning and Structured Prediction to No-Regret Online Learning (DAgger) paper review
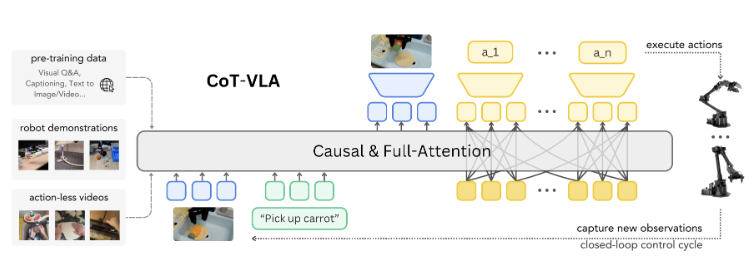
CoT-VLA: Visual Chain-of-Thought Reasoning for Vision-Language-Action Models (2025)
CoT-VLA: Visual Chain-of-Thought Reasoning for Vision-Language-Action Models (CVPR 2025)의 논문 내용 정리
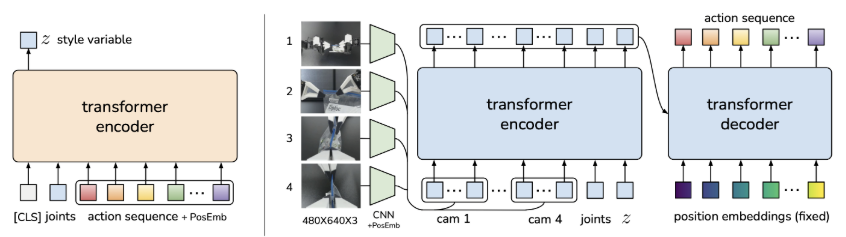
ACT : Learning Fine-Grained Bimanual Manipulation with Low-Cost Hardware (2023)
ACT : Learning Fine-Grained Bimanual Manipulation with Low-Cost Hardware (RSS 2023) 논문 읽기
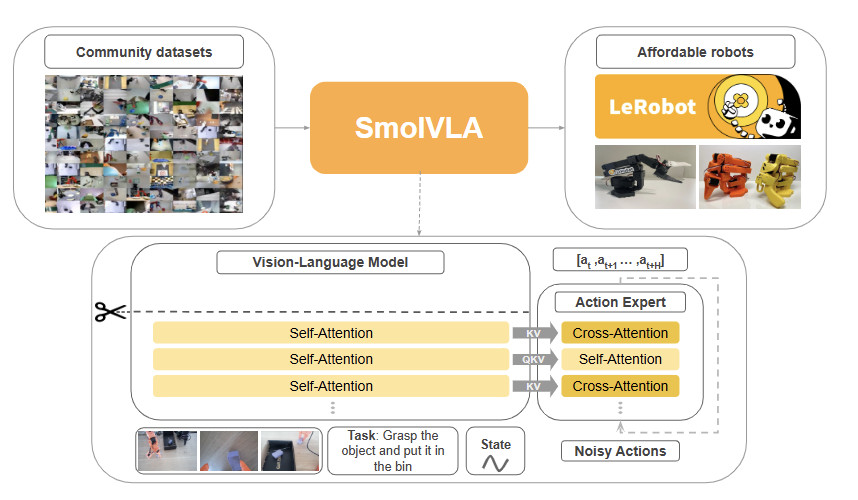
SmolVLA: A Vision-Language-Action Model for Affordable and Efficient Robotics
SmolVLA: A Vision-Language-Action Model for Affordable and Efficient Robotics (2025) 논문 내용 정리
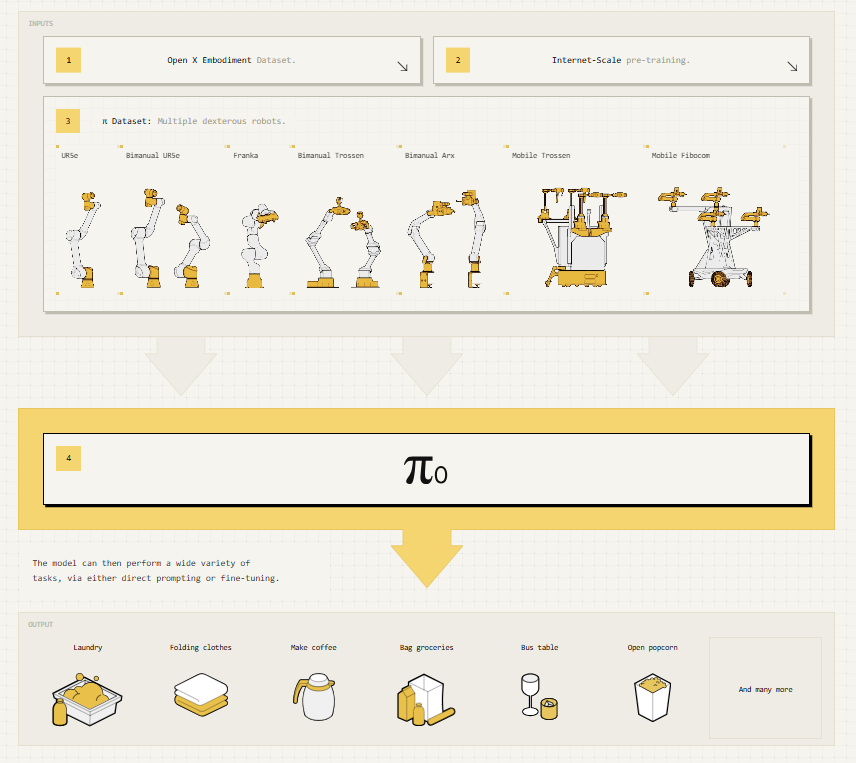
π0 : A Vision-Language-Action Flow Model for General Robot Control
π_0 : A Vision-Language-Action Flow Model for General Robot Control (2024) 읽어보기

Leisaac ( LeRobot + Gr00t + IsaacSim)으로 입문하는 VLA Finetuning
Lerobot이 VLA 입문하게 해줘서 고구마 구웠어요 ~

OpenVLA : An Open-Source Vision-Language-Action Model 논문 리뷰
OpenVLA : An Open-Source Vision-Language-Action Model (2024) 논문 읽기

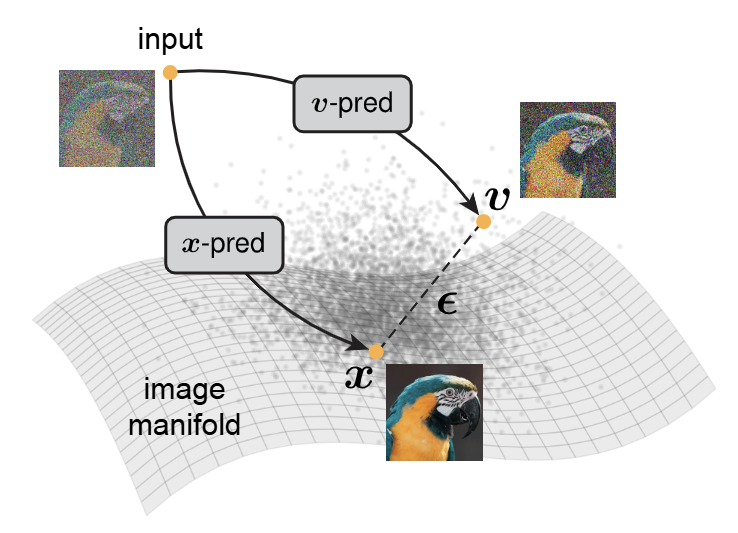
JiT (Just Image Transformers) 논문 리뷰
Back to Basics: Let Denoising Generative Models Denoise (2025), JiT 논문 읽기

The Big LLM Architecture Comparison (Sebastian Rashka)
(읽어보기/번역 및 정리) The Big LLM Architecture Comparison by Sebastian Rashka

[day-6 논문 핥기] LORA: Low-Rank Adaptation of Large Language Models
(DAY 6) LoRA: Low-Rank Adaptation of Large Language Models paper review

[day-5 논문 핥기] Retrieval-Augmented Generation (RAG) for Knowledge-Intensive NLP Tasks
(DAY 5) RAG(Retrieval Augmented Generation) paper review

Qwen3-Next: Towards Ultimate Training & Inference Efficiency
Qwen3-Next post review



[day-2 논문 핥기] Segment Anything (SAM) paper
(DAY 2) Segment Anything (SAM) paper review
