
- 전체보기(24)
- LLM(21)
- Fine Tuning(5)
- prompt engineering(3)
- transformers(3)
- rag(3)
- NLP(2)
- legal AI(2)
- Embedding(1)
- SSM(1)
- BERT(1)
- quantization(1)
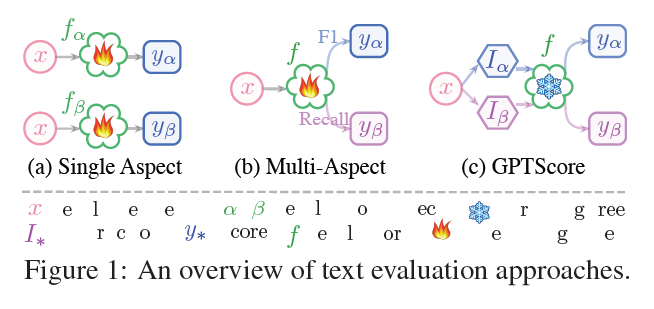
GPTScore: Evaluate as You Desire
GPTAnalytical AI to Generative AIlarge PLM + Prompt $\\rightarrow$ superior performanceneeds for evaluating the quality of these textsevaluating singl
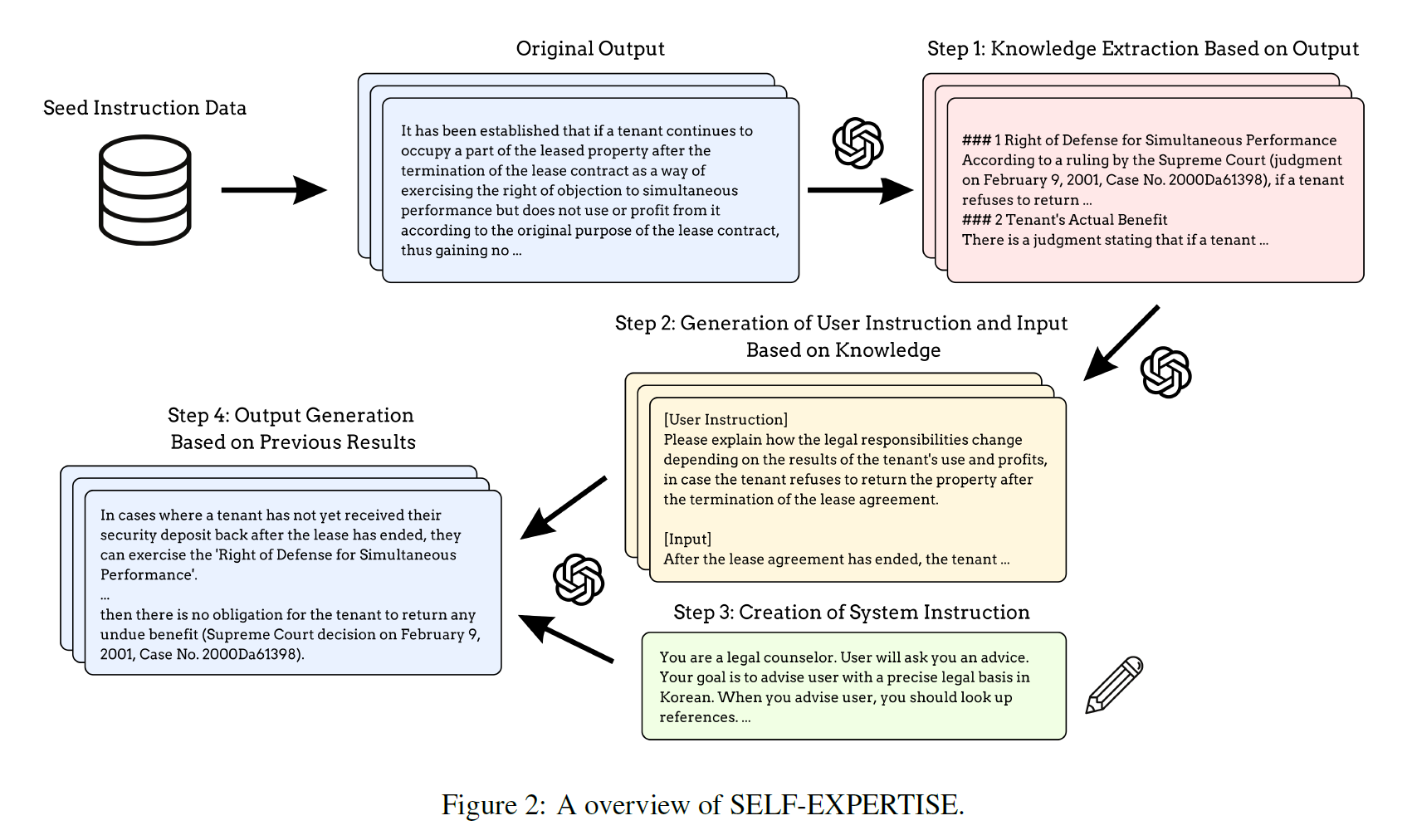
SELF-EXPERTISE: Knowledge-Based Instruction Dataset Augmentation for a Legal Expert Language Model
Instruction Tuning DatasetInstruction Tuning is important for LLMsAuto generation method is unsuitable for some domains where the accuracy is importan
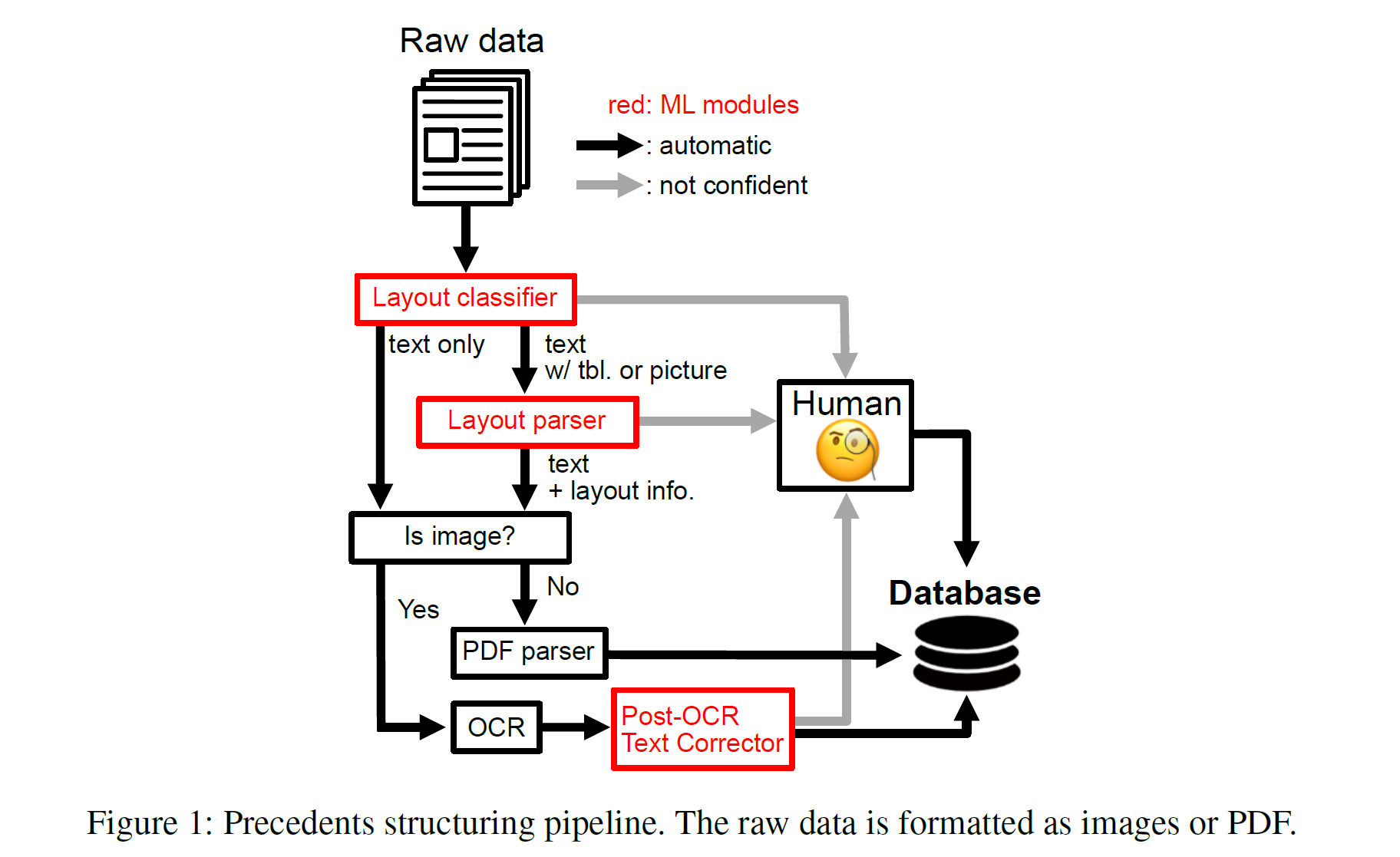
A Multi-Task Benchmark for Korean Legal Langhage Understanding and Judgement Prediction
Previous Legal Export SystemsUseful on certain areasDeep Learning Based ApproachLegal Judgement PredictionLegal Content GenerationLegal Text Classific
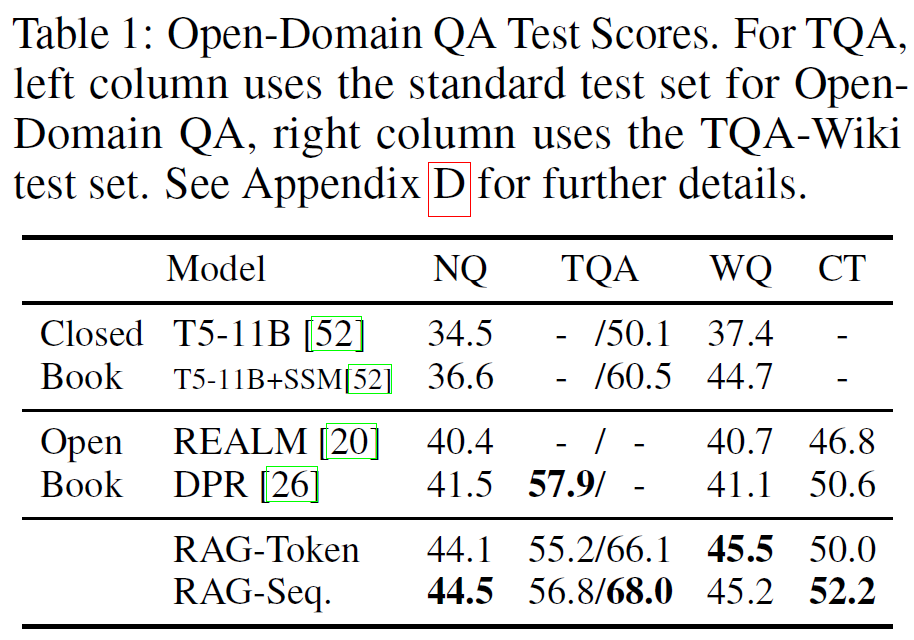
Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks
1. Introduction PLMs learn a substantial amount of in-depth knowledge from data it can't expand or revise their memory can't straightforward
Computational analysis of 140 years of US political speeches reveals more positive but increasingly polarized framing of immigration
Abstract 200K US congressional speeches + 5K presidential communications related to immigration from 1880 to the present political speech about immig
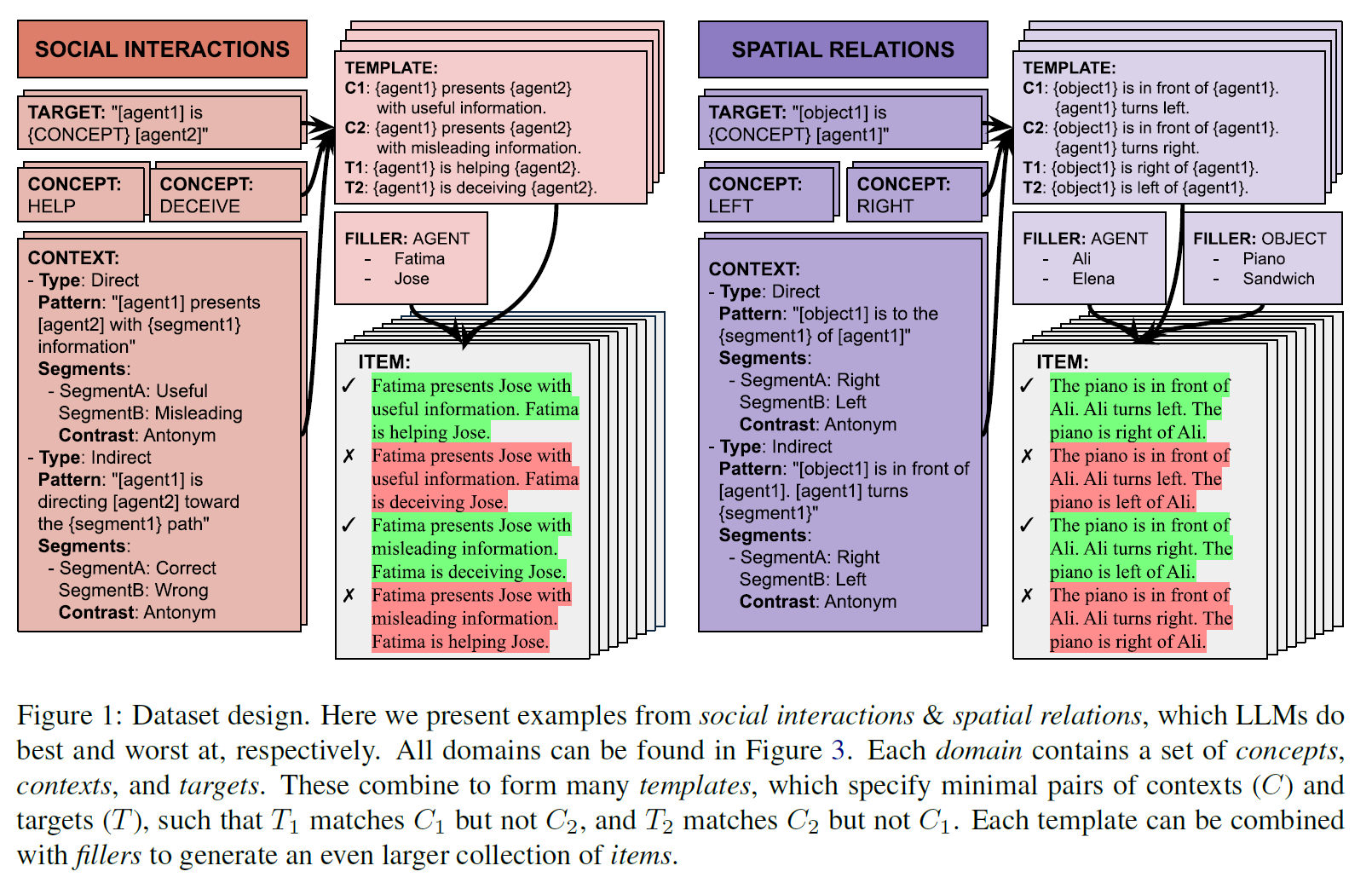
Elements of Worls Knowledge (EWoK)
Elements of Worls Knowledge (EWoK): A cognition-inspired framework for evaluating basic world knowledge in LMsLLM acquires a substantial amount knowle
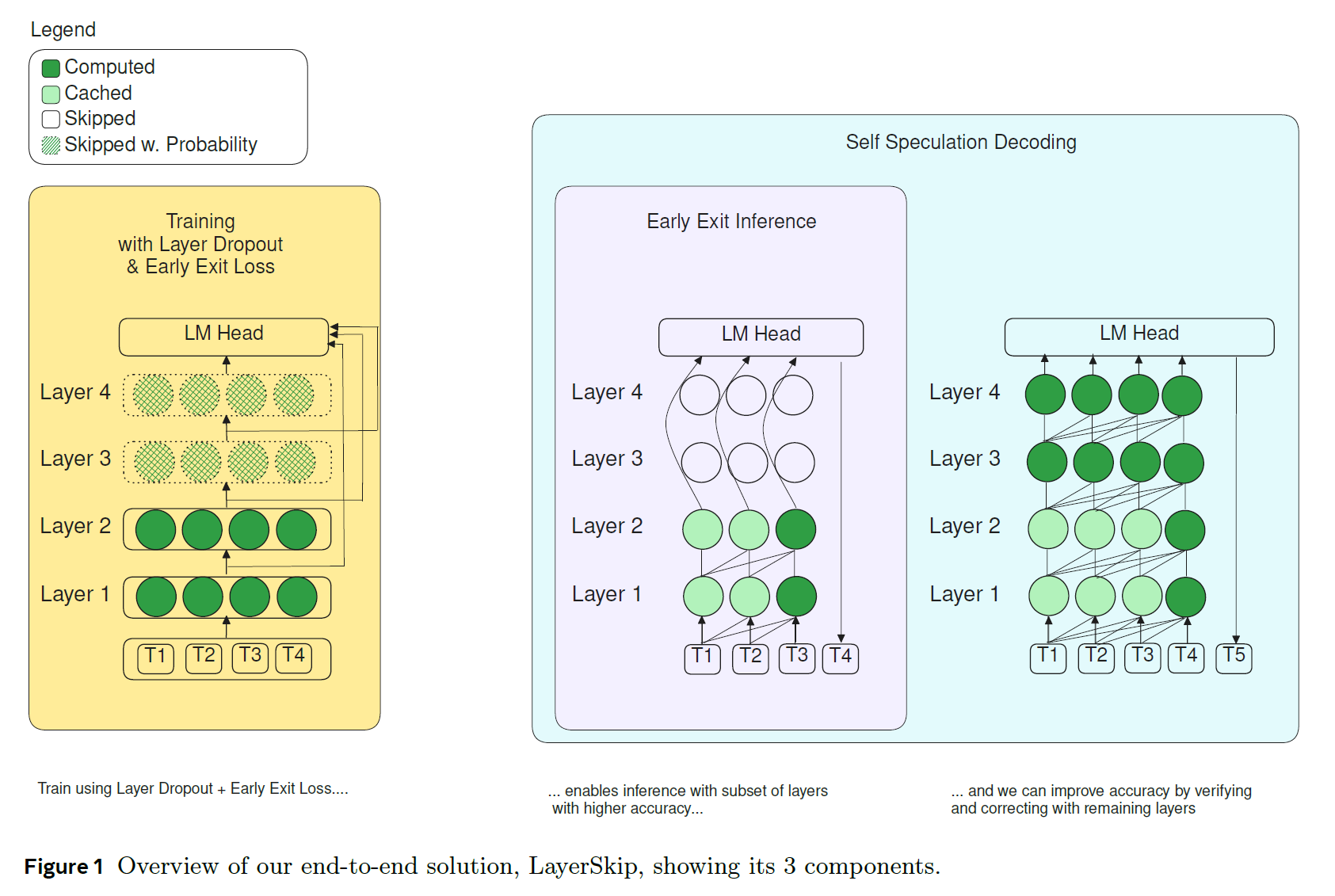
LayerSkip : Enabling Early Exit Inference and Self-Speculative Decoding
LLM Accelerationsparsityquantizationhead pruningReducing the number of layers for each token by exiting early during inferenceSpeculative decodingmain
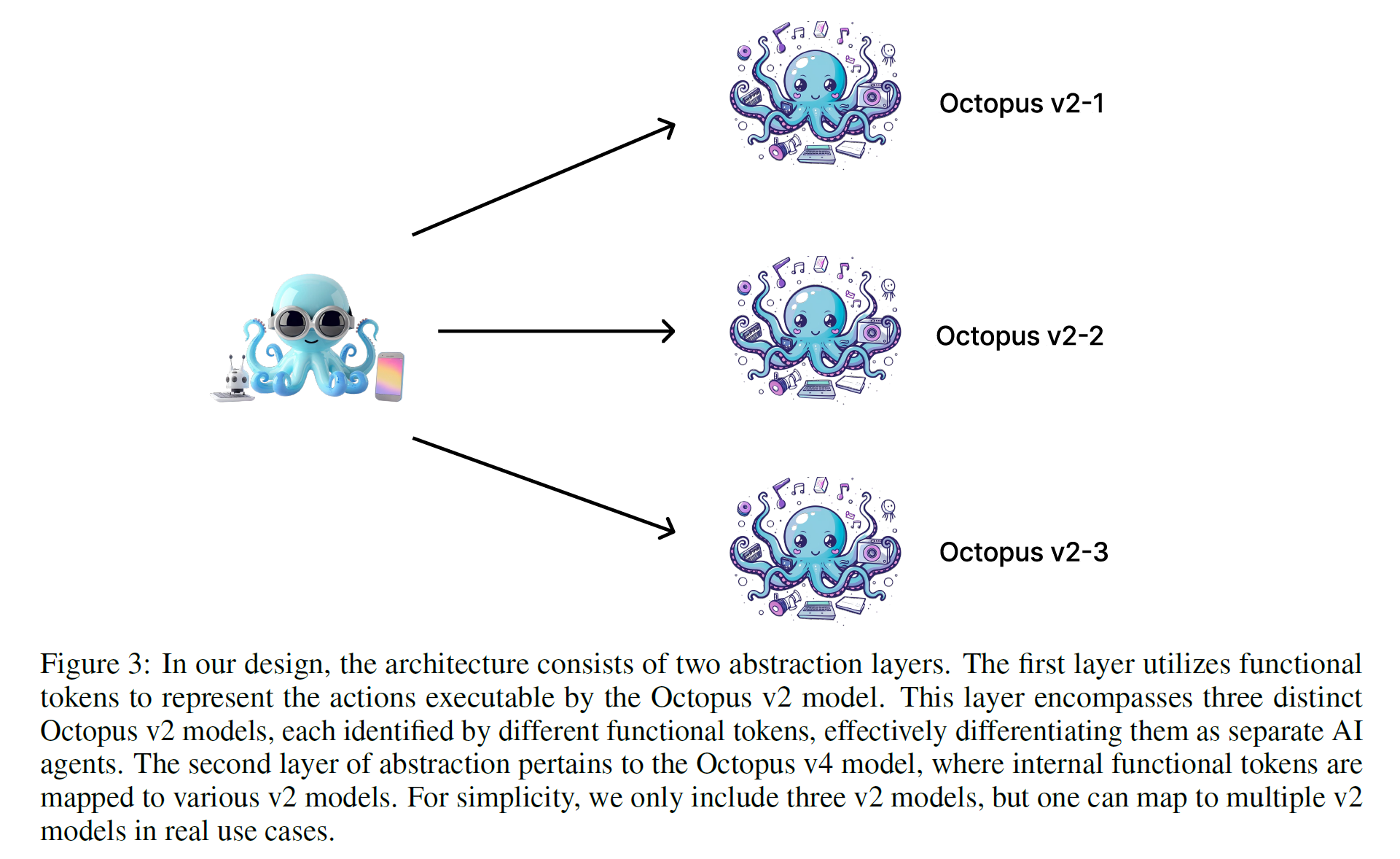
Octopus v4: Graph of Language Models
1. Introduction LLMs became very powerful and used in lots of fields Due to Llama 2 and 3, the open-source LLMs has seen significant growth use
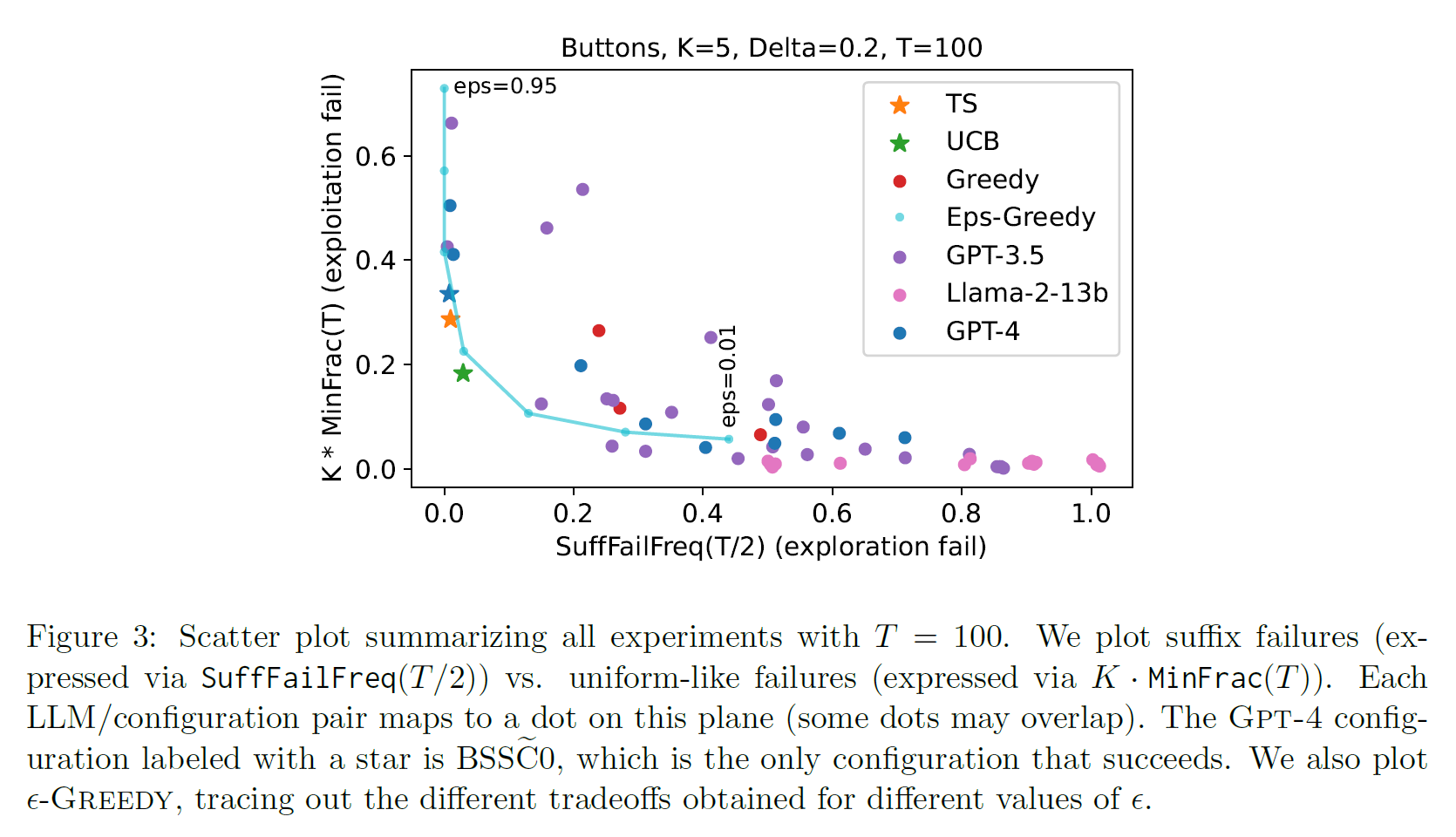
Can large language models explore in-context?
1. Introduction In-context Learning $\rightarrow$ important emergent capability of LLM without updating the model parameter, LLM can solve variou
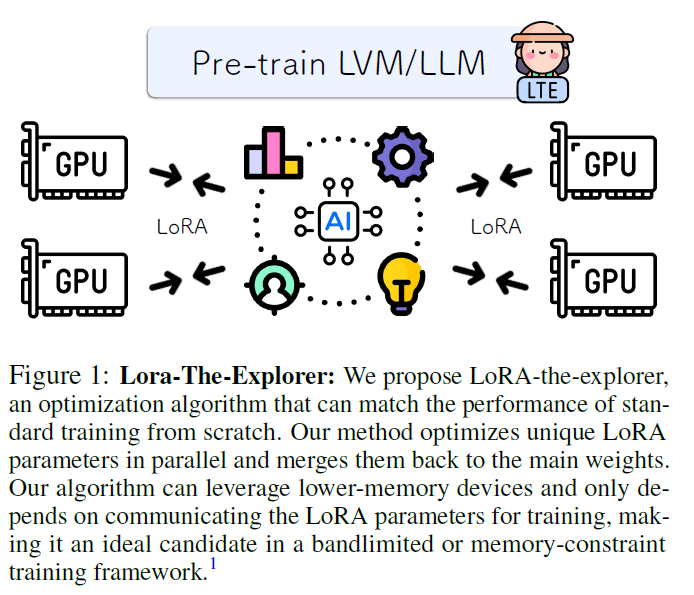
Training Neural Networks from Scratch with Parallel Low-Rank Adapters
SOTA models' complexity $\\rightarrow$ computation / memory / communication bandwidthLoRAquantizing model parametrosPrior work has been limited to fin

Is Cosine-Similarity of Embeddings Really About Similarity?
1. Introduction Discrete Entities are embedded to dense real-valued vectors word embedding for LLM recommender system The embedding vector
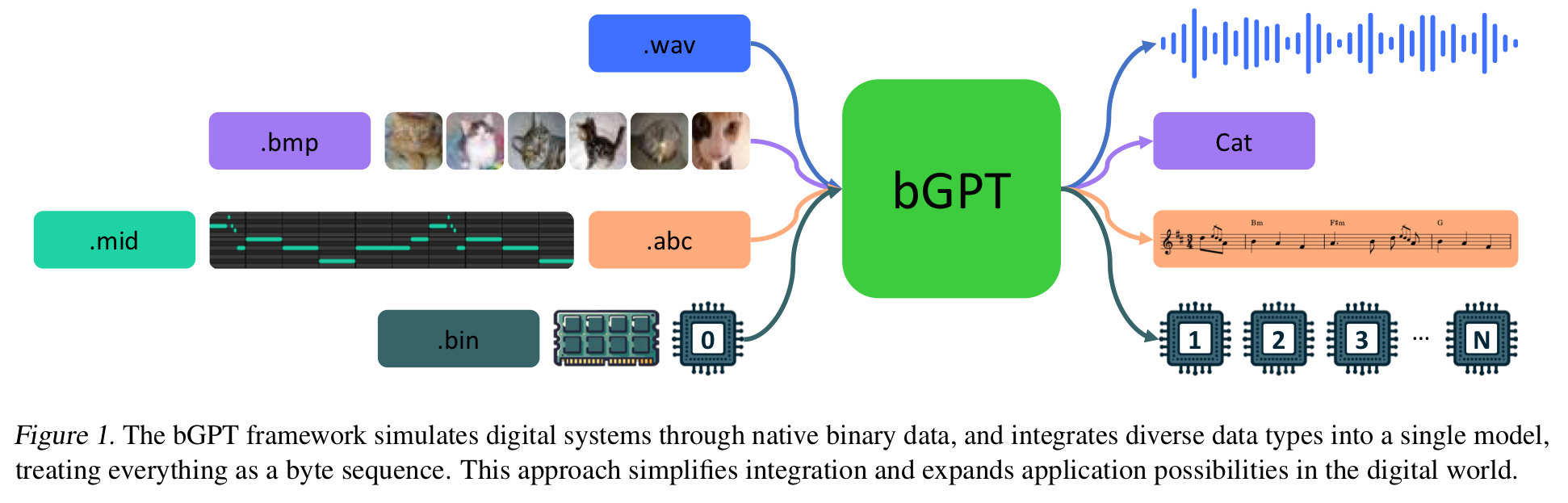
Beyond Language Models: Byte Models are Digital World Simulators
Deep Learning has focused on interpretable digital media files - text, images, audioText played central role in conveying human intelligence and has l
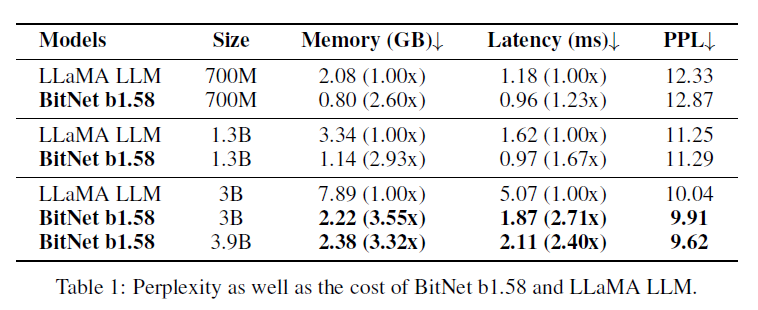
The Era of 1-bit LLMs: All LLMs are in 1.58 bits
Abstract BitNet paved the way for a new era of 1-bit LLMs BitNet b.58 has every parameter as a * tenary * {-1, 0, 1} matches a full-precision Tr
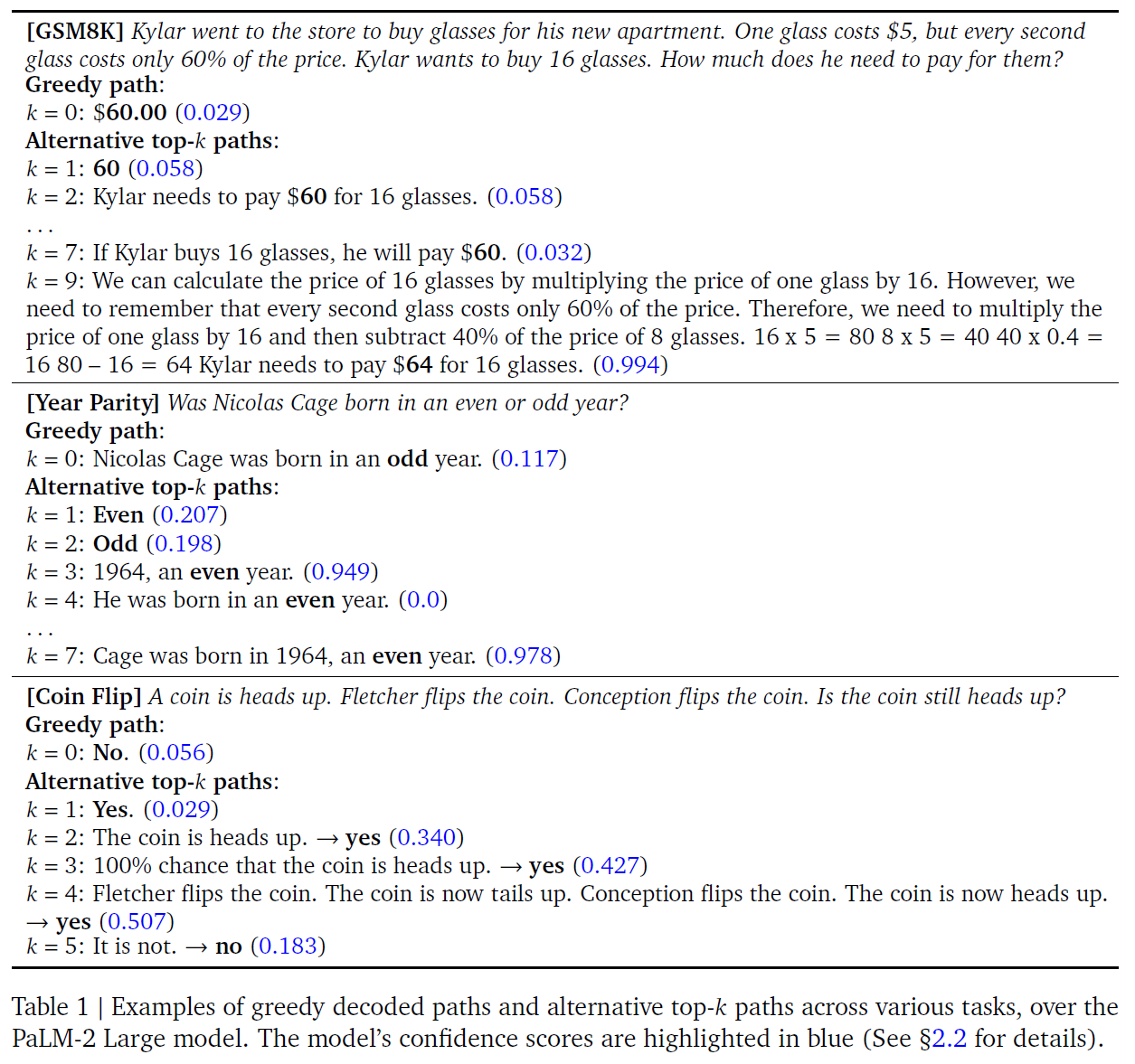
CoT Reasoning without Prompting
1. Introduction LLMs' reasoning capabilities are elicited by prompting techniques Few shot prompting with intermediate steps augmented demonstra
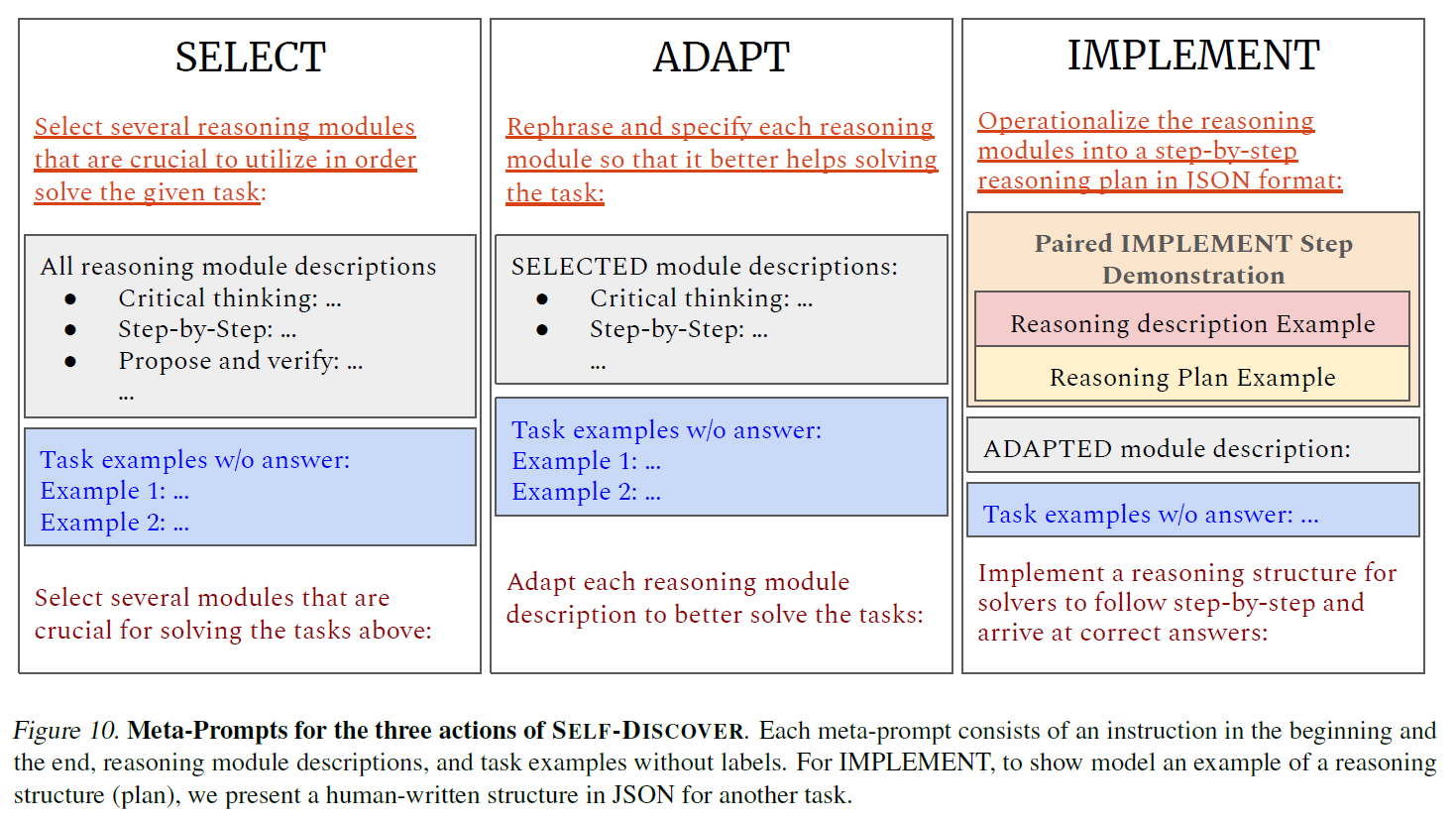
Self-Discover: LLMs Self-Compose Reasoning Structure
1. Introduction To enhance LLMs' capability to reason and solve complex problems via prompting Few-shot & Zero-shot CoT $\rightarrow$ how humans
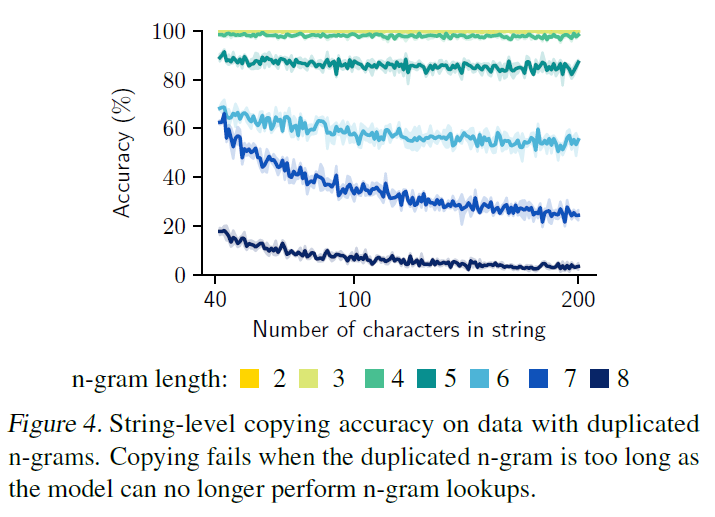
Repeat After Me: Transformers are Better than State Space Models at Copying
..? 1. Introduction Transformers require $\Omega(L)$ memory and compute to predict the next token of a sequence of length $L$ (using Flash Attention!
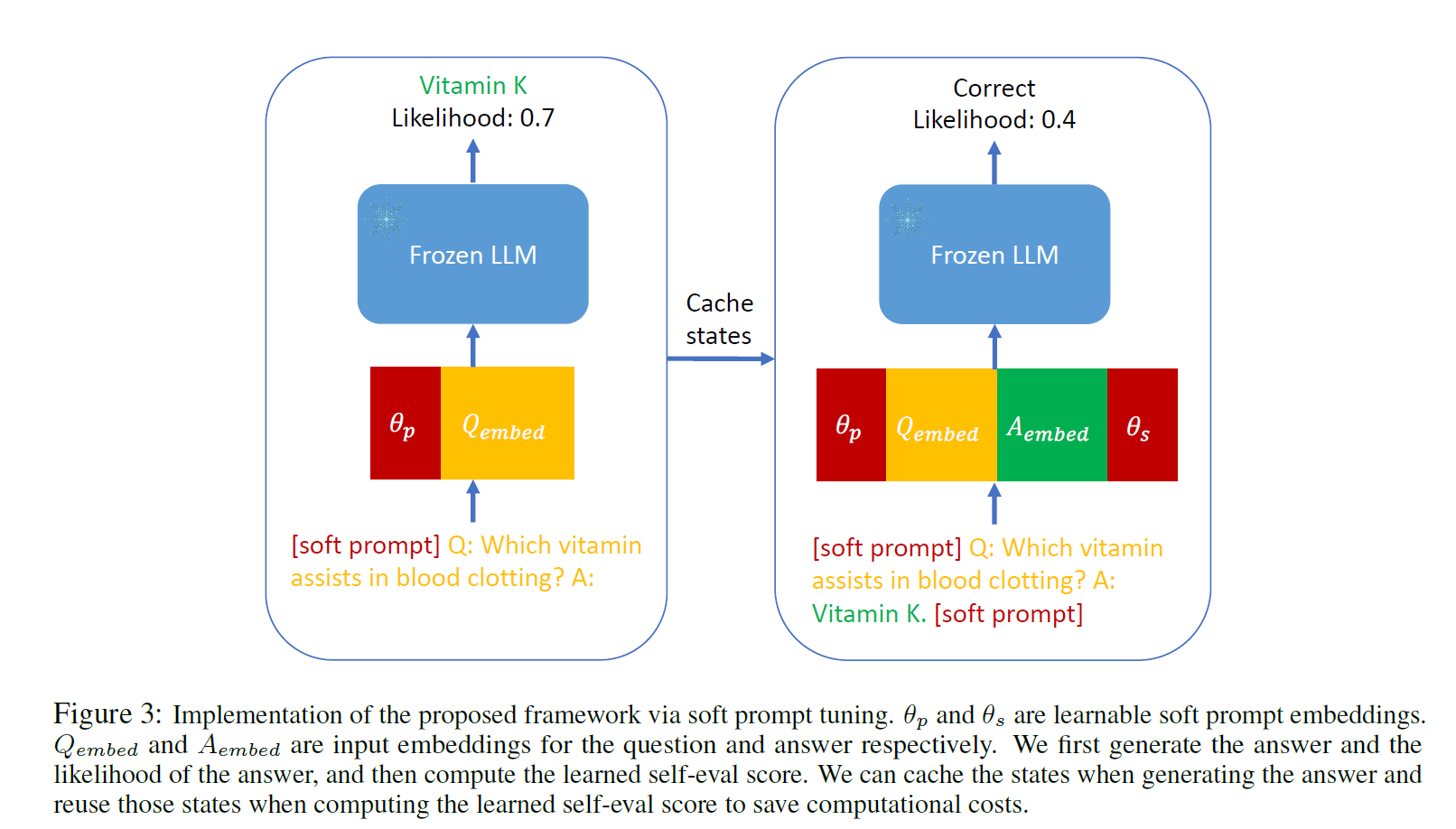
Adaptation with Self-Evaluation to Improve Selective Prediction in LLMs
1. Introduction LLM is not guaranteed to be accurate for all queries Understanding which queries they are reliable for is important Selective Predict

Spotting LLMs with Binoculars: Zero-Shot Detection of Machine-Generated Text
Intruducing a method for detecting LLM-generated text using zero-shot setting (No training sample from LLM source) outperforms all models with ChatGPT
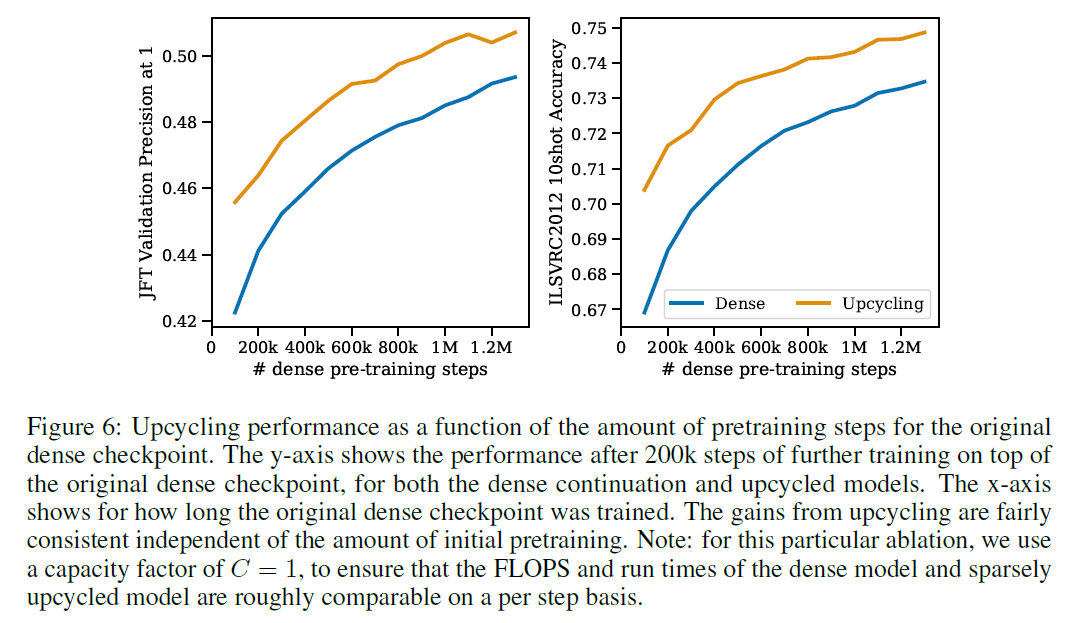
Sparse Upcycling: Training MoE from Dense Checkpoints
1. Introduciton Increased Scale is one of the main drivers of better performancd in DL (NLP, Vision, Speech, RL, Multimodal etc.) Most SOTA Neural Net
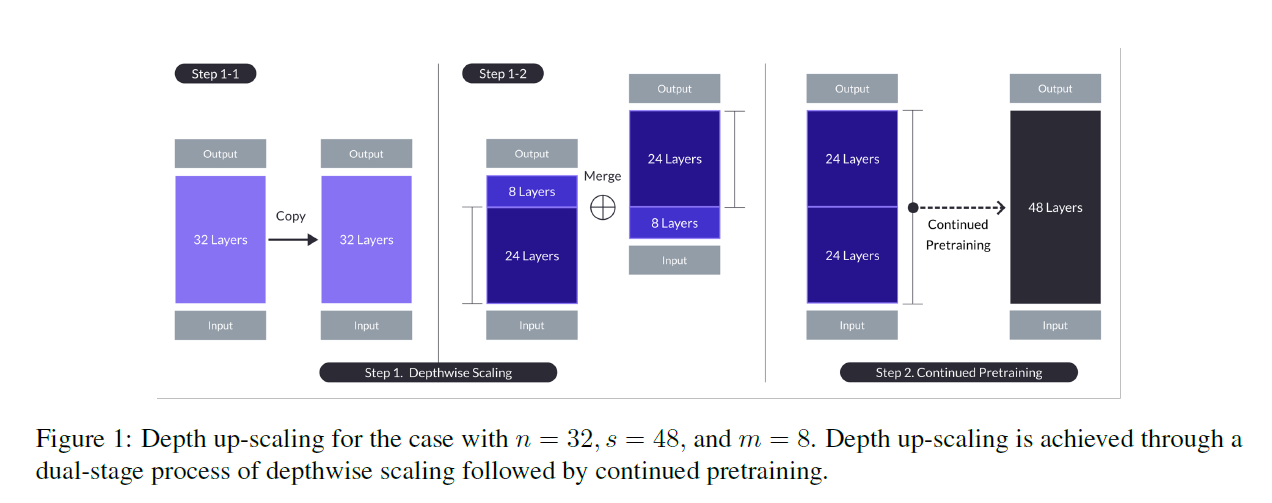
SOLAR 10.7B: Scaling LLMs with Simple yet Effective Depth Up-Scaling
1. Introduction Recent LLMs scaling with performance scaling law $\rightarrow$ MoE Often require non-trivial changes to the training and inferen