

Style Aligned Image Generation via Shared Attention (CVPR 2024)
AbstractT2I 모델들은 좋은 성능을 보이고 있지만, 일정한 스타일을 유지하도록 보장하는 것은 여전히 도전이다.최소한의 어텐션 공유로 본 논문에서는 스타일이 정렬된 데이터의 모음을 생성하는 것을 가능케 한다.Method본 논문의 목표는 스타일이 text prom
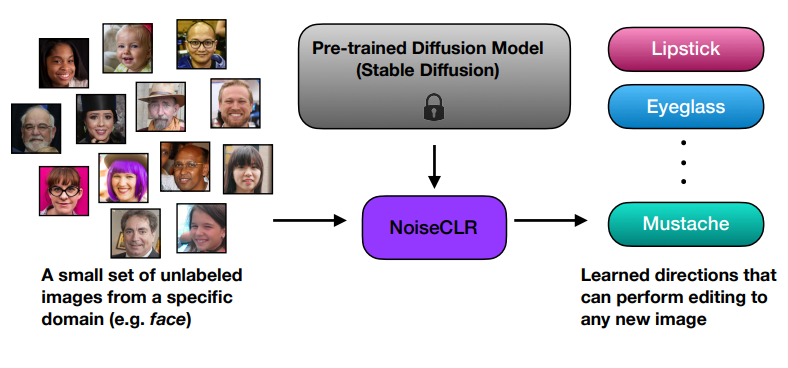
NoiseCLR: A Contrastive Learning Approach for Unsupervised Discovery of Interpretable Directions in Diffusion Models (CVPR 2024)
AbstractGAN 기반 생성 모델들은 latent에서의 disentangle 성능으로 높게 평가되고 있으며, 이것은 이미지 편집에 있어서 핵심 아이디어가 된다.Diffusion도 최근 강력한 생성 능력을 보이고 있지만, latent 공간은 GAN만큼 이해되거나 연구
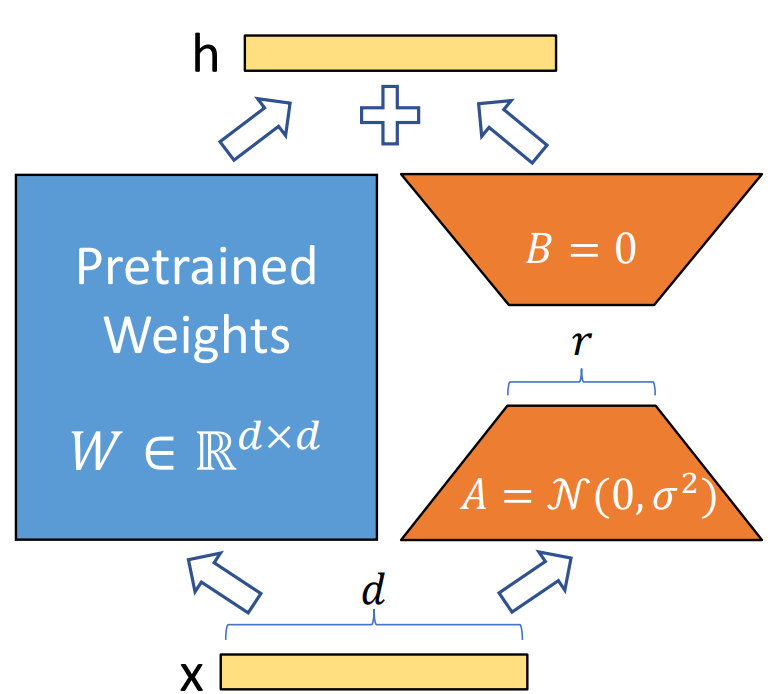
LORA: Low-Rank Adaptation of Large Language Models (ICLR, 2022)
Abstract & IntroductionGPT-3 (1750억 개의 파라미터)와 같은 거대한 모델의 전체 파인튜닝은 높은 계산 및 메모리 비용으로 비현실적임.사전 학습된 모델의 가중치를 고정하고, 트랜스포머 레이어에 학습 가능한 저랭크 행렬을 삽입함.이를 통해 학습해
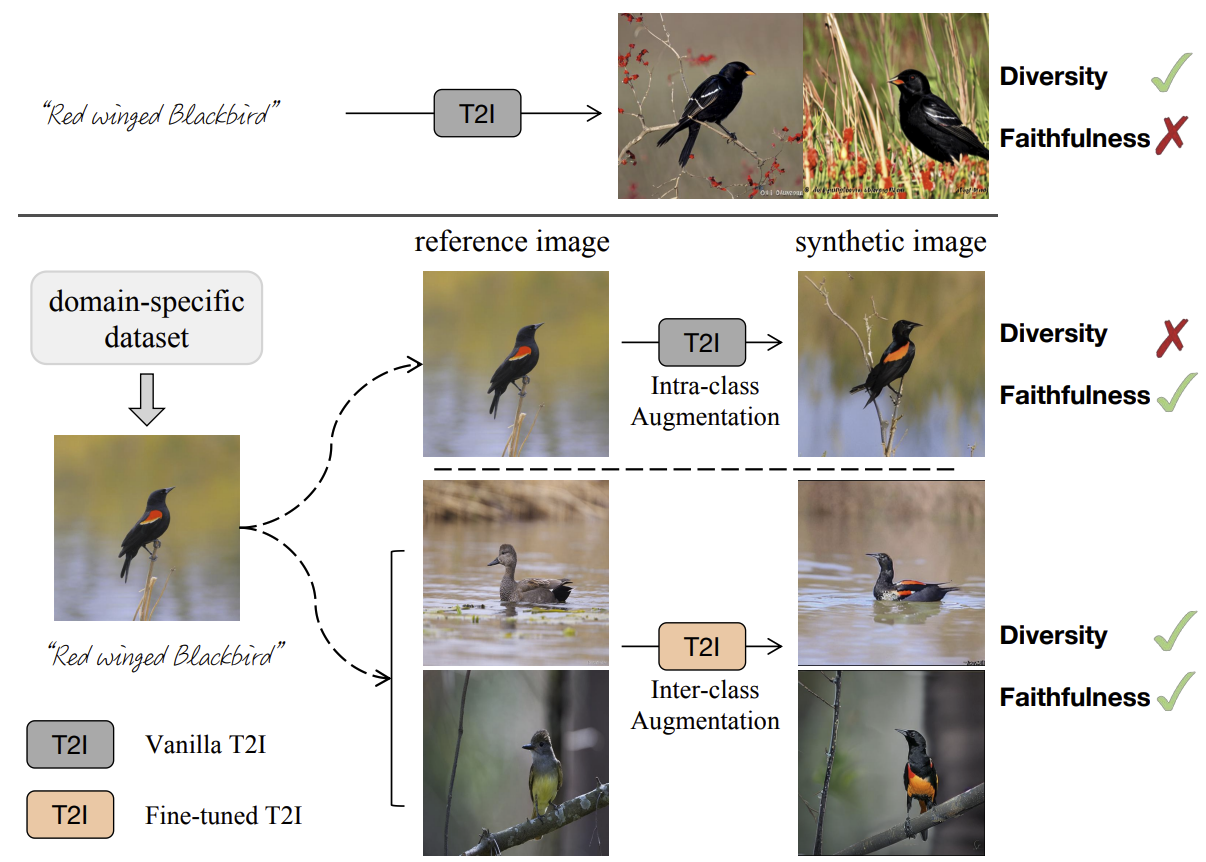
Enhance Image Classification via Inter-Class Image Mixup with Diffusion Model (CVPR 2024)
AbstractT2I 모델들은 최근 강력한 성능을 보여왔지만, 이러한 모델들을 classification과 결합했을 때 좋은 성능이 나올까에 대한 의문은 여전히 남아있다.데이터 증강에서의 생성형 방식과 전통적인 방식 둘 다 일정하면서 다양성이 높은 이미지를 만들기에는
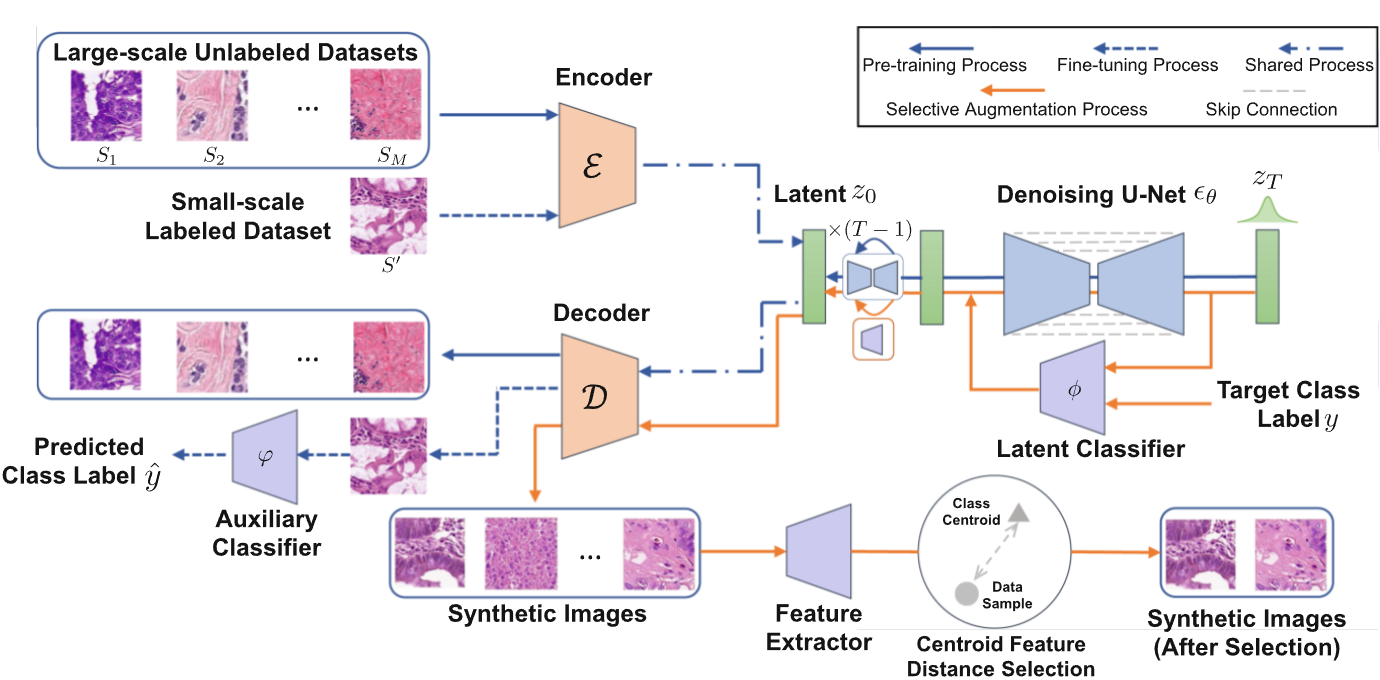
Medical Diffusion Paper Research
Synthetic Augmentation with Large-Scale Unconditional Pre-training이러한 방식들의 효과는 생성 모델의 성능에 엄청나게 의존을 하는데, 충분한 라벨링된 데이터 없이는 생성 모델의 성능을 보장할 수 없다.라벨링된 데이터에
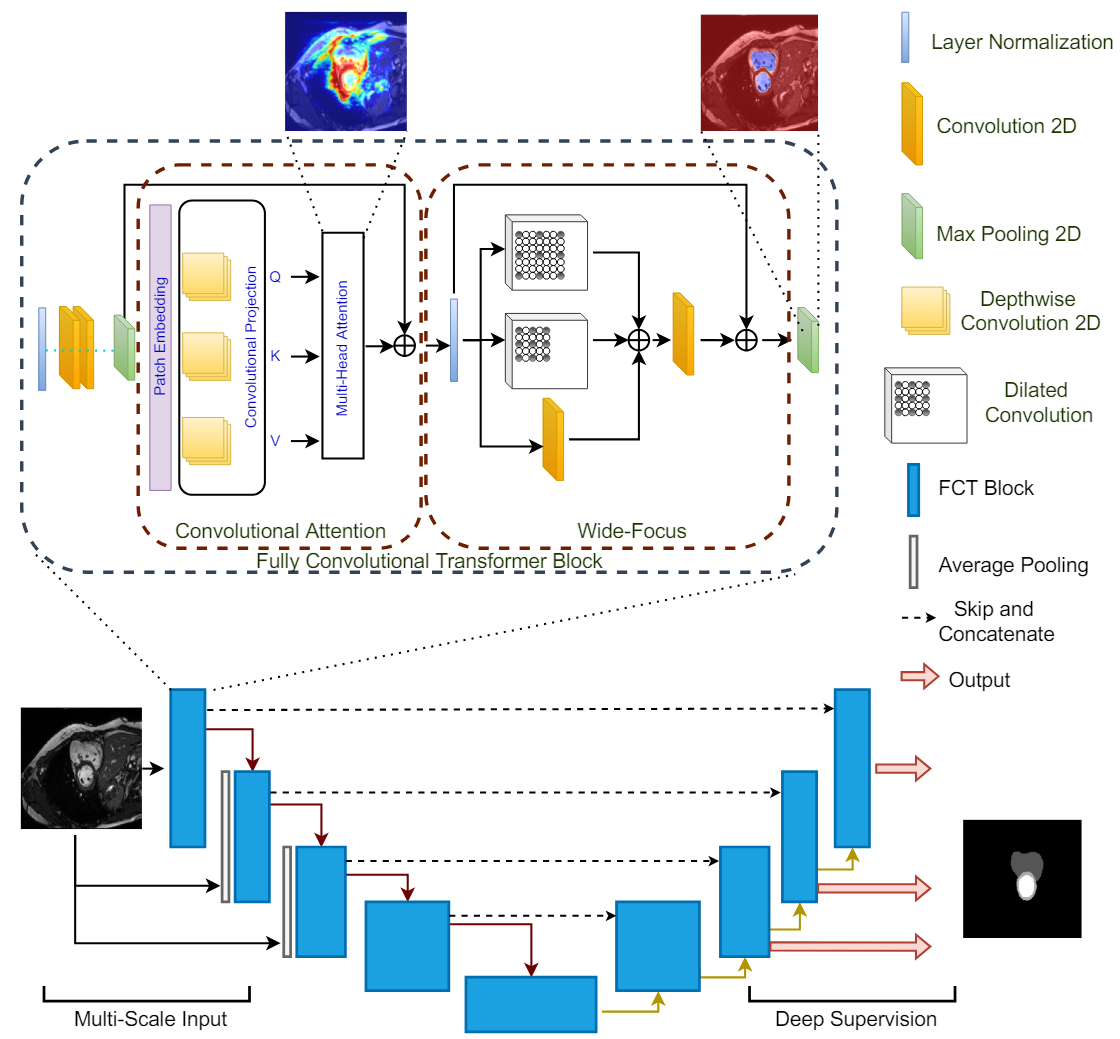
The Fully Convolutional Transformer for Medical Image Segmentation(WACV, 2023)
저자들은 의료 데이터에 대한 다양한 모달리티를 segmentation하는데 능한 transformer인 FCT를 제시하고 있습니다.Fully Convolutional Transformer(FCT)는 잘 알려진 CNN으로 이미지의 표현을 배우고, Transformer로
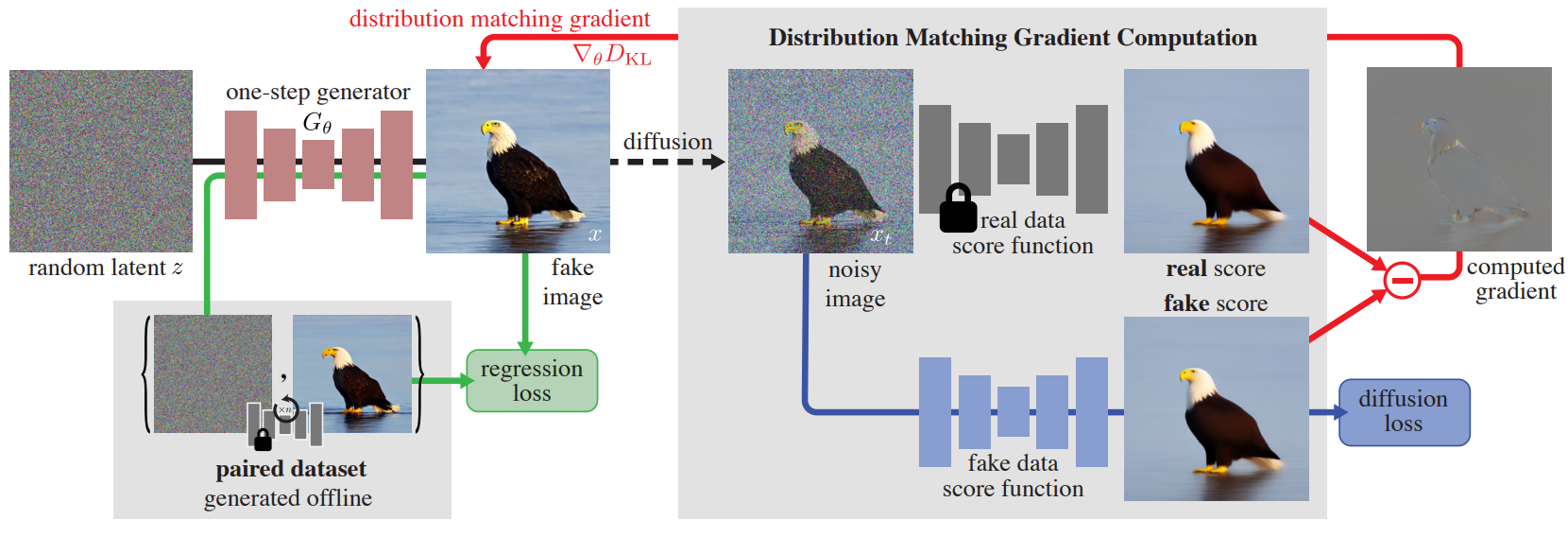
One-step Diffusion with Distribution Matching Distillation (CVPR, 2024)
Diffusion Models (DMs)는 고퀄리티의 이미지를 생성하지만, 수십/수백번의 forward pass를 거쳐야 한다는 단점이 존재한다.본 논문에서는 이미지 품질에 영향을 거의 주지 않으며, 단 한번의 step으로도 이미지 생성을 가능케하는 one-step d
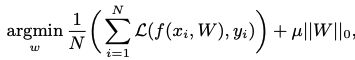
AutoPrune: Automatic Network Pruning by Regularizing Auxiliary Parameters
Abstract본 논문에서는 AutoPrune이라는 방법을 제시하며, 이 방법은 원래의 가중치들을 대신하여 학습이 가능한 보조 파라미터들의 최적화를 통해 네트워크를 pruning하는 방법이다.이러한 방식의 장점은 학습 단계에서 발생하거나 개입할 수 있는 노이즈나 불안정
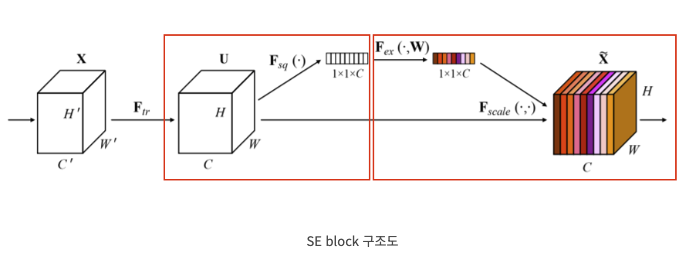
SENet: Squeeze-and-Excitation Networks
Abstract최근 CNN이 더욱 발전하면서, 각 layer의 공간적인 정보와 필터로 생성된 채널간의 정보를 결합하여 많은 정보를 쌓는 것이 가능해졌다.특징들의 계층성을 이용하여 공간 정보를 인코딩하는 CNN의 능력을 강화시킬 수 있었다.해당 논문에서는 channel의
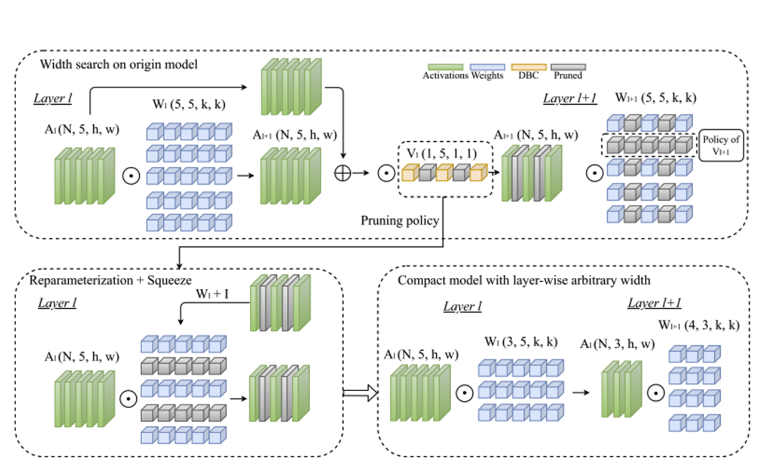
Pruning-as-Search: Efficient Neural Architecture Search via Channel Pruning and Structural Reparameterization
Abstract & Introduction NAS는 depth와 width를 자동으로 찾지만, searching overhead가 있어서 모델을 찾는데 엄청난 cost가 소모된다.
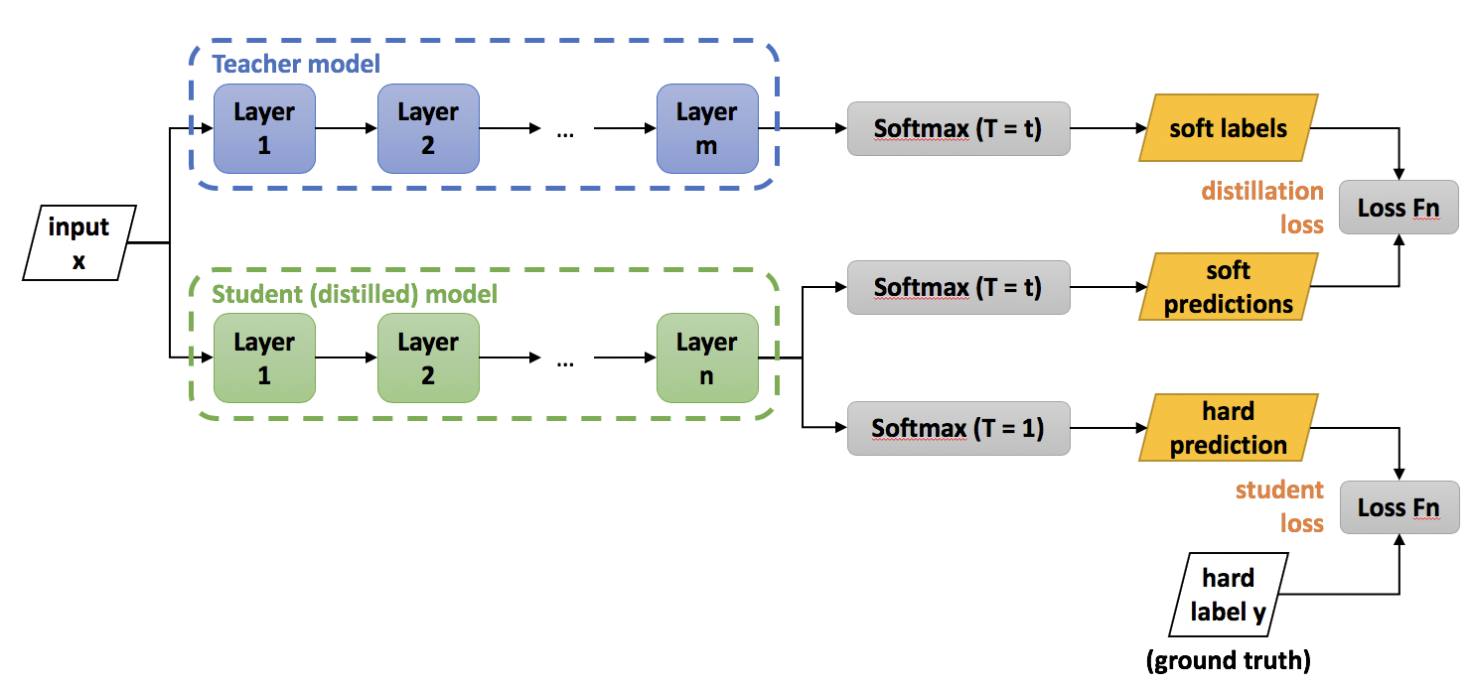
Distilling the Knowledge in a Neural Network (NIPS 2014)
Abstract & Introduction좋은 성능을 내기 위해서는 모델 앙상블과 방법을 사용할 수 있지만, 연산량이 많고 시간이 오래 걸린다.정답에 대한 레이블 뿐만이 아니라, 이외에 레이블에 대한 작은 확률 정보까지도 성능에 도움이 된다는 생각에서 지식 증류는 시작
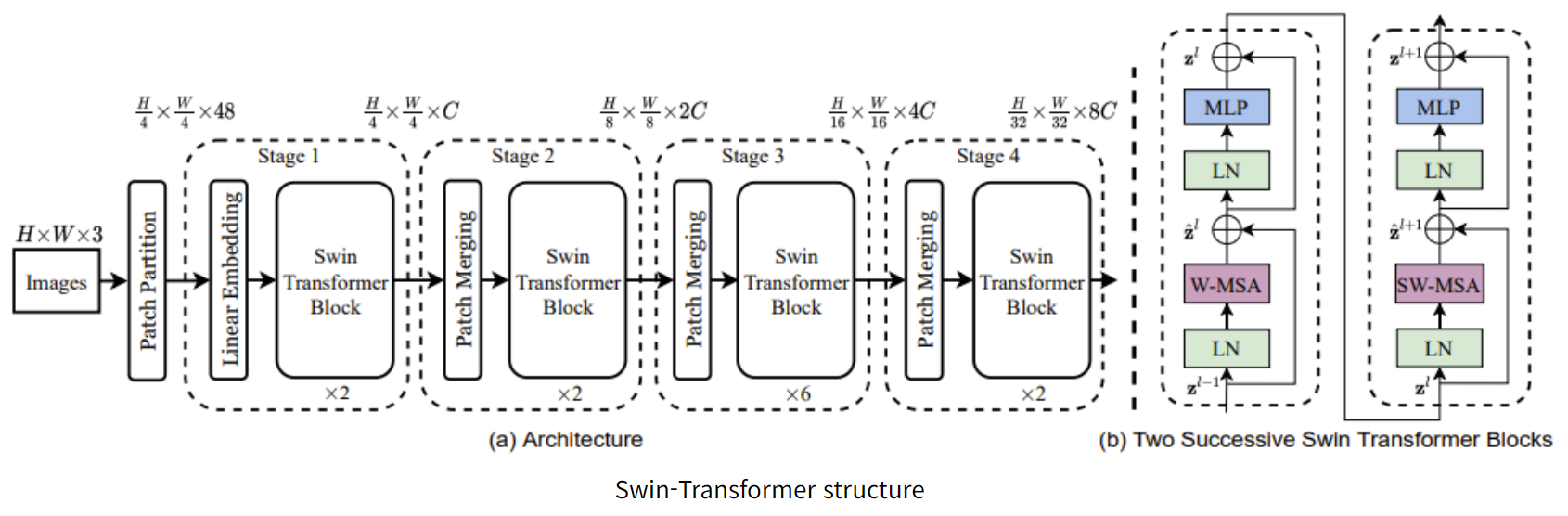
Swin Transformer: Hierarchical Vision Transformer using Shifted Windows
Introduction기존의 ViT window는 고정적이기 때문에 segmentation 하기가 어려웠다.Swin Transformer는 window를 세밀하게 쪼개는 것뿐만 아니라, 여러 모양의 window를 이용한다.단순하게 window 이용에서 그치지 않고 sh
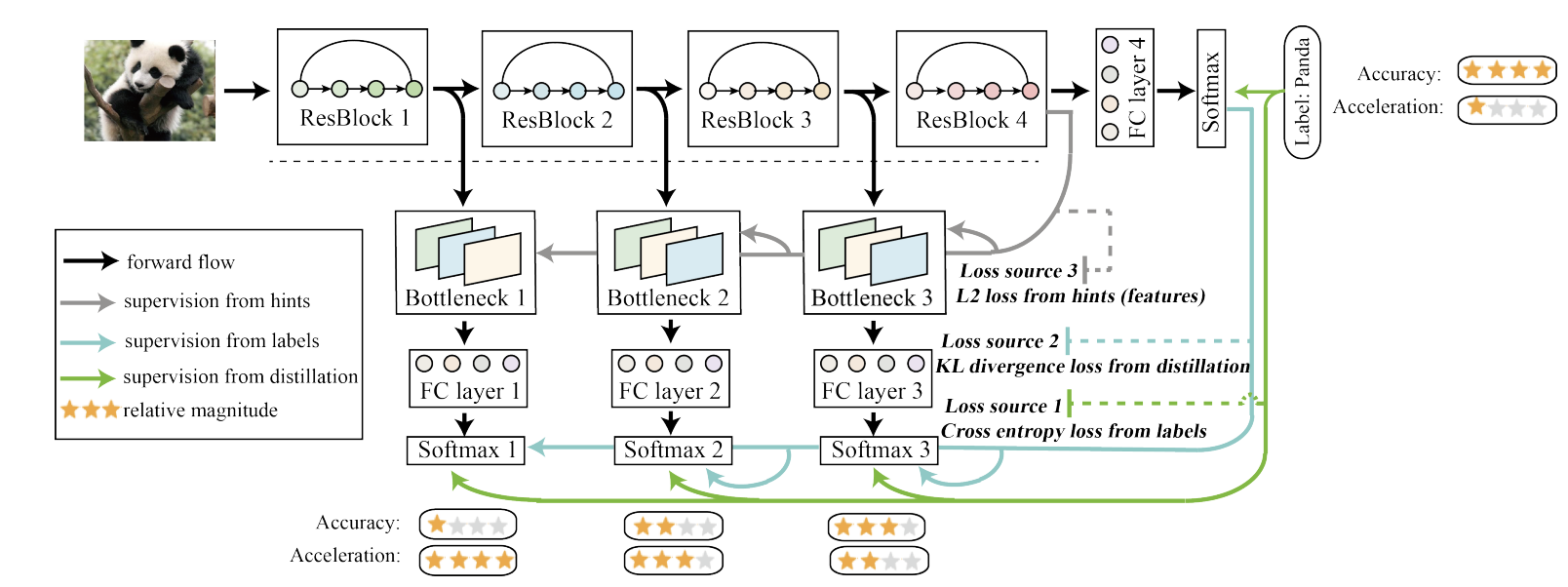
Be Your Own Teacher: Improve the Performance of Convolutional Neural Networks via Self Distillation
Abstract & Introduction본 논문에서는 self-distillation 학습 방법을 제안한다.전통적인 knowledge distillation인 사전 학습된 teacher 네트워크의 출력을 softmax처리 한 값을 활용하는 방법과 다른 self-dis
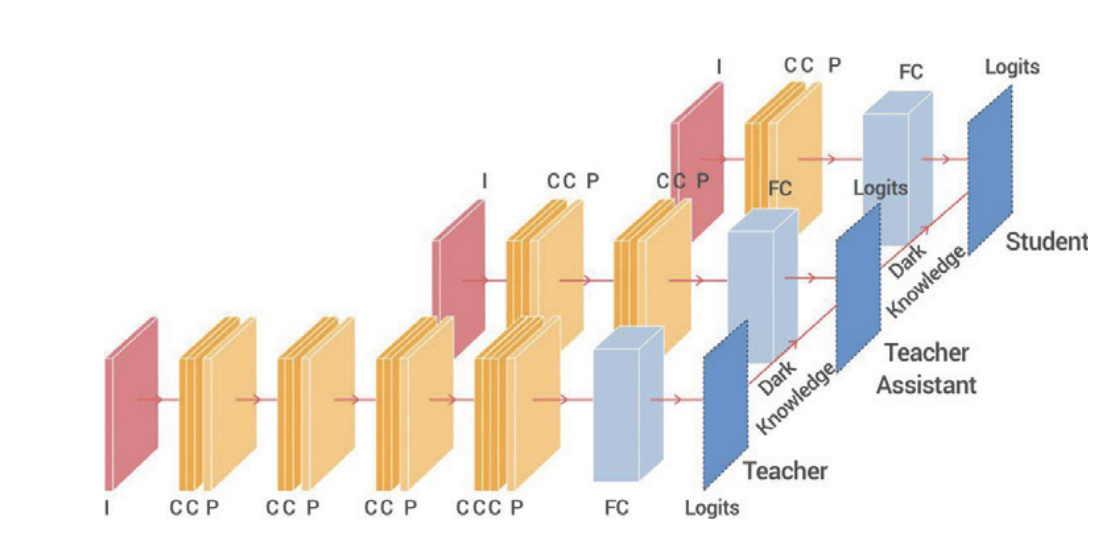
Improved Knowledge Distillation via Teacher Assistant (AAAI 2020)
AbstractDNN들이 강력하지만 모델의 크기와 무게가 너무 커서 edge device에는 응용되기 힘들기에, 이를 지식 증류로 압축하고 줄이려는 노력들을 해왔다.본 논문에서는 선생 모델과 학생 모델 사이의 간격이 크면 학생 모델의 성능이 감소한다는 문제점을 제시하고
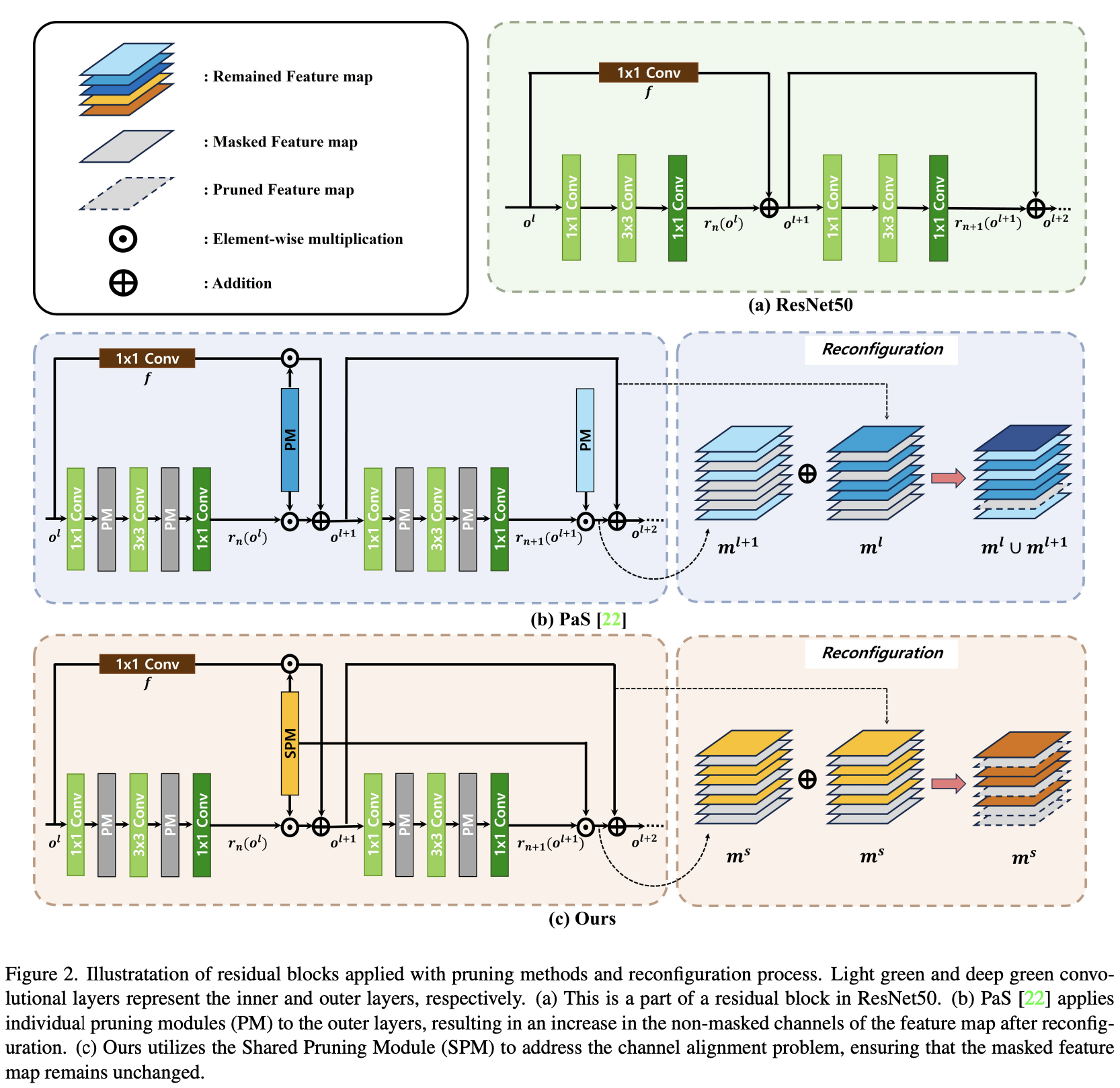
Pruning from Scratch via Shared Pruning Module and Nuclear norm-based Regularization (WACV, 2024)
대부분의 pruning 연구들은 pre-trained된 모델들에서 중복되는 채널들을 찾아내는 방법에 집중하고 있지만, 이는 규모가 있는 네트워크를 학습할 때의 비용과, 효율적인 재구성을 위해서 채널을 고르는 것의 중요성을 간과하고 있다고 할 수 있다.본
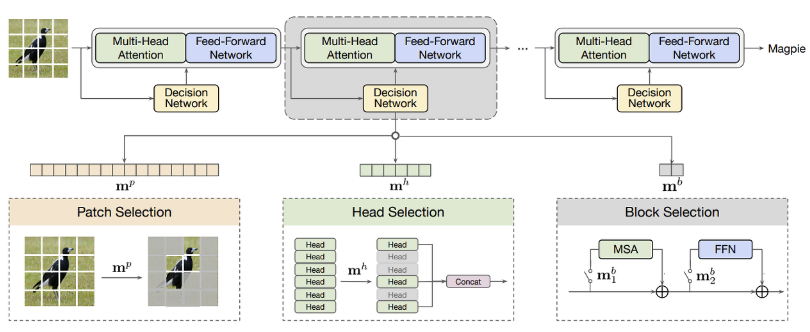
AdaViT: Adaptive Vision Transformers for Efficient Image Recognition (CVPR, 2022)
최근 self-attention을 기반으로 한 ViT들이 vision task들에서 놀라운 성능을 보이고 있는데, patch와 head와 block 개수의 증가로 인해 여전히 엄청난 computational cost를 요구하고
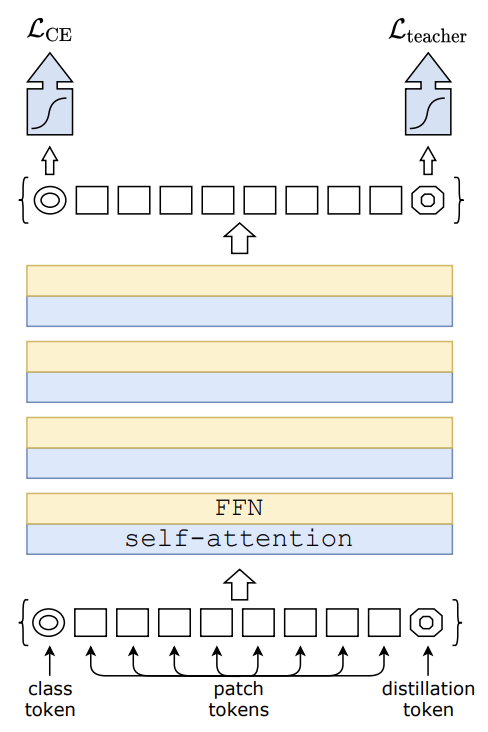
Training data-efficient image transformers & distillation through attention
Abstract DeiT의 특징은 크게 2 가지가 있다.ViT와 동일한 transformer 모델 구조를 가지고 있다.CNN 구조의 teacher모델의 지식을 증류 기법으로 학습한 student 모델을 사용하여 CNN의 inductive bias를 상속받는다.DeiT는
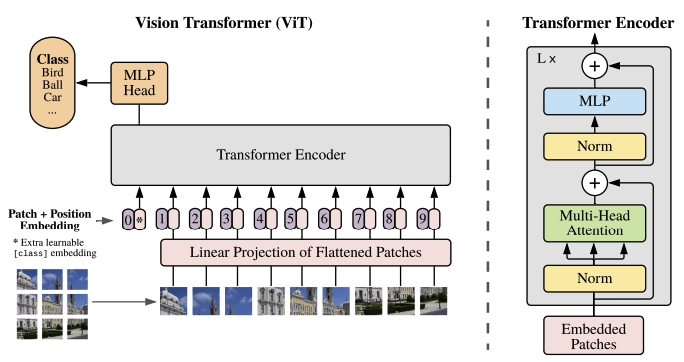
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale (ICLR 2021)
AbstractTransformer 구조는 등장 이래로 자연어 처리 분야의 표준으로 자리잡았고 컴퓨터 비전 분야에서 적용은 한정적이었다.비전 분야에서 attention은 CNN과 함께 적용되거나 convolution의 전체적인 구조는 유지하면서 특정 요소만 대체하는 데
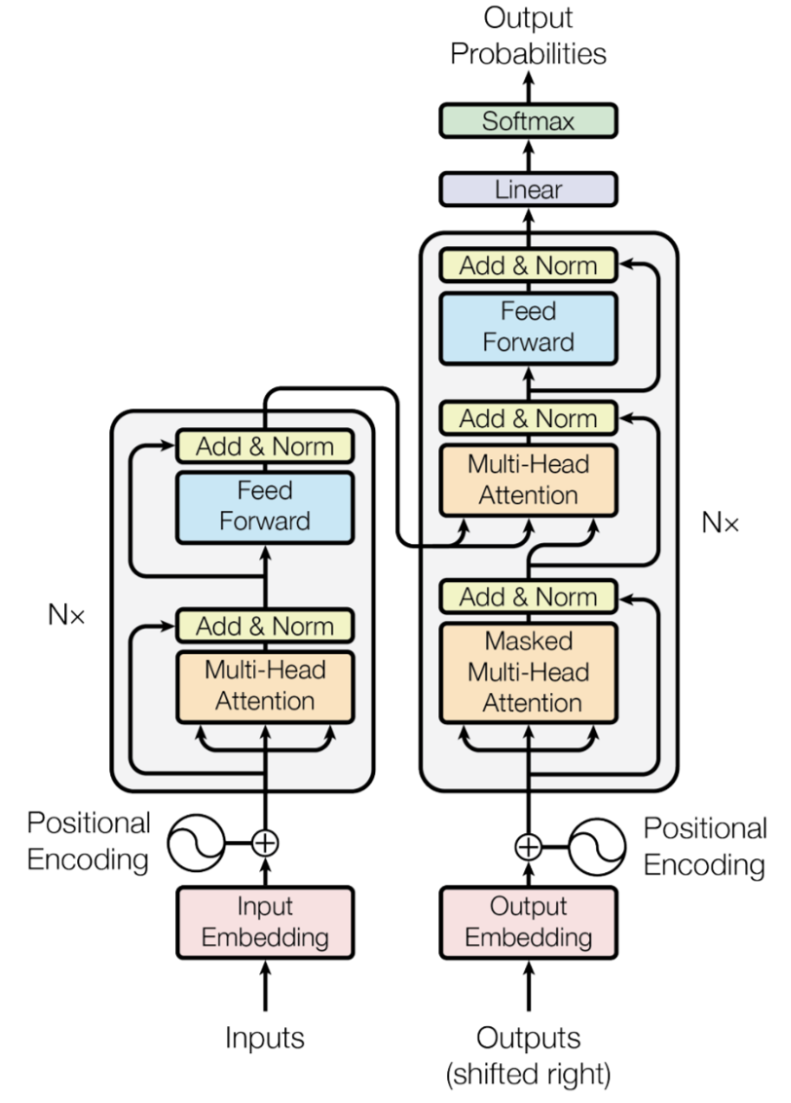
Attention is All You Need (NeuIPS 2017)
Abstract성능 좋은 시퀀스 변환 모델은 대체로 인코더와 디코더를 포함한 복잡한 RNN 또는 CNN 신경망에 기반을 두고 있음본 논문은 재귀적으로 시퀀스를 처리하지 않는다는 점과, 컨볼루전을 제외하였다는 점, 그리고 오직 attention mechanism에만 기반
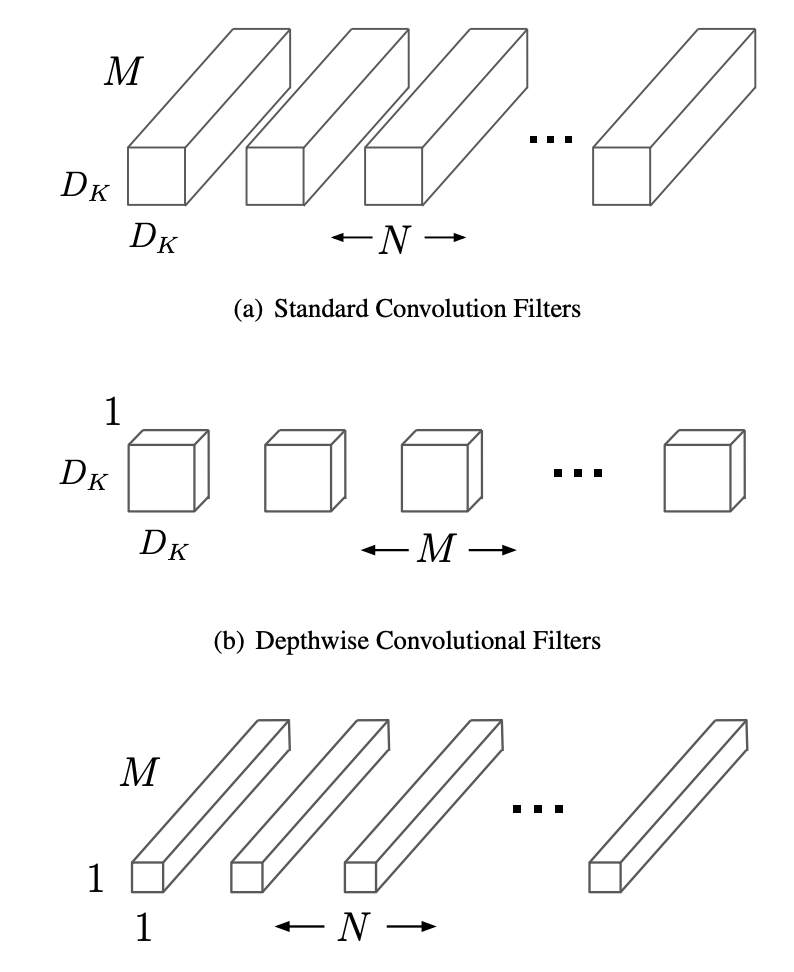
MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications
논문에서는 모바일/임베디드 비전 애플리케이션에서 효율적인 모델들을 제시한다. 무게가 가벼운 신경망을 개발하기 위해서, 깊이에 대해 분리가 가능한 컨볼루젼들을 사용하는 유선형의 모델 구조