
[Insight] 네트워크관리사 2급 실기 정리
경로제어판 → 네트워크 및 공유 센터 → 어댑터 설정 → IPv4설정IP AddressSubnet MaskDefault GatewayDNSIIS → 서버(루트) → FTP 사이트 추가설정사이트 이름실제 경로IP 주소포트인증권한FTP 기능 메뉴에서 문제 조건 수정필요 시
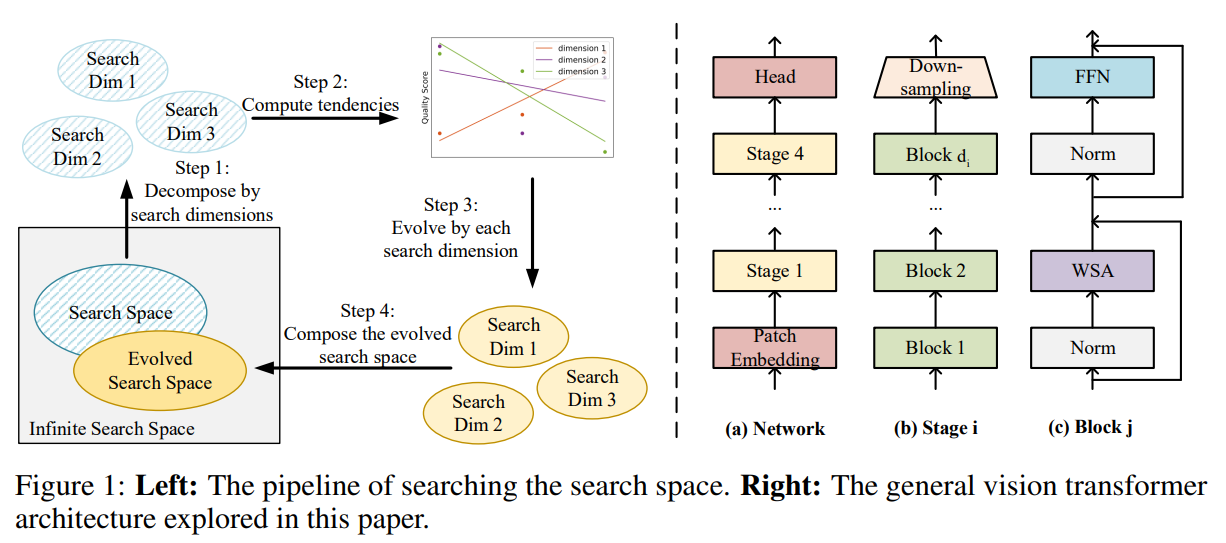
[논문 리뷰] S3: Searching the Search Space of Vision Transformers
기본 정보: 본 논문의 제목은 "Searching the Search Space of Vision Transformer"이며, Stony Brook University, Sun Yat-sen University, CAS, Microsoft Research Asia 소속
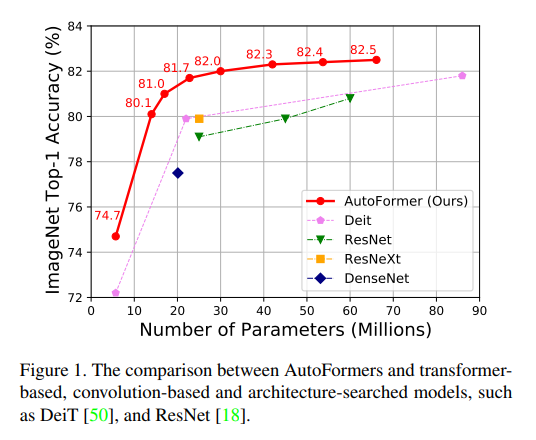
[논문 리뷰] AutoFormer: Searching Transformers for Visual Recognition
기본 정보: AutoFormer: Searching Transformers for Visual Recognition, Minghao Chen, Houwen Peng, Jianlong Fu, Haibin Ling 저, 2021년 발표 (Stony Brook Univers
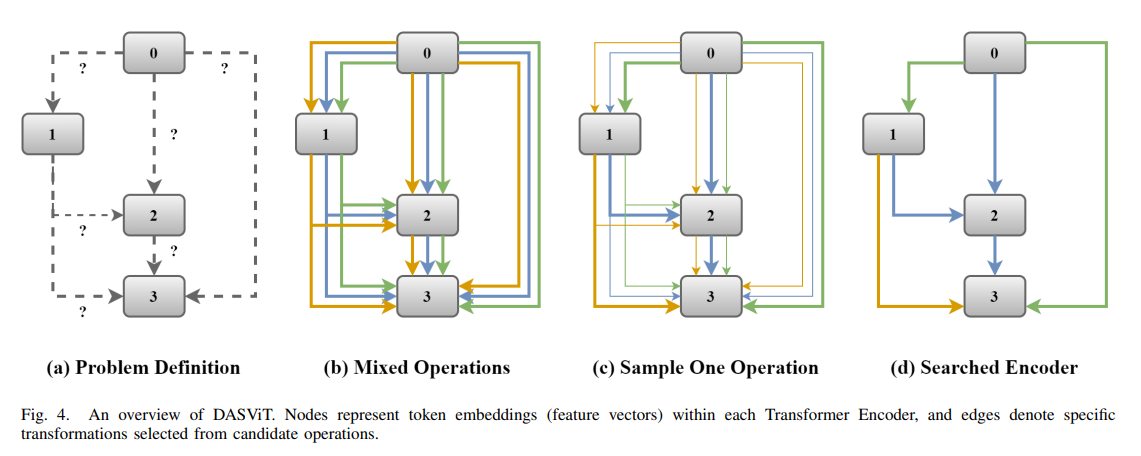
[논문 리뷰] DASViT: Differentiable Architecture Search for Vision Transformer
기본 정보 및 핵심 목적: 영국 Surrey 대학교의 Pengjin Wu, Ferrante Neri 및 중국 강남 대학교의 Zhenhua Feng 연구진이 arXiv를 통해 발표한 본 연구는, 최초로 경사하강법 기반의 미분 가능한 아키텍처 탐색(DARTS) 기법을 Vi
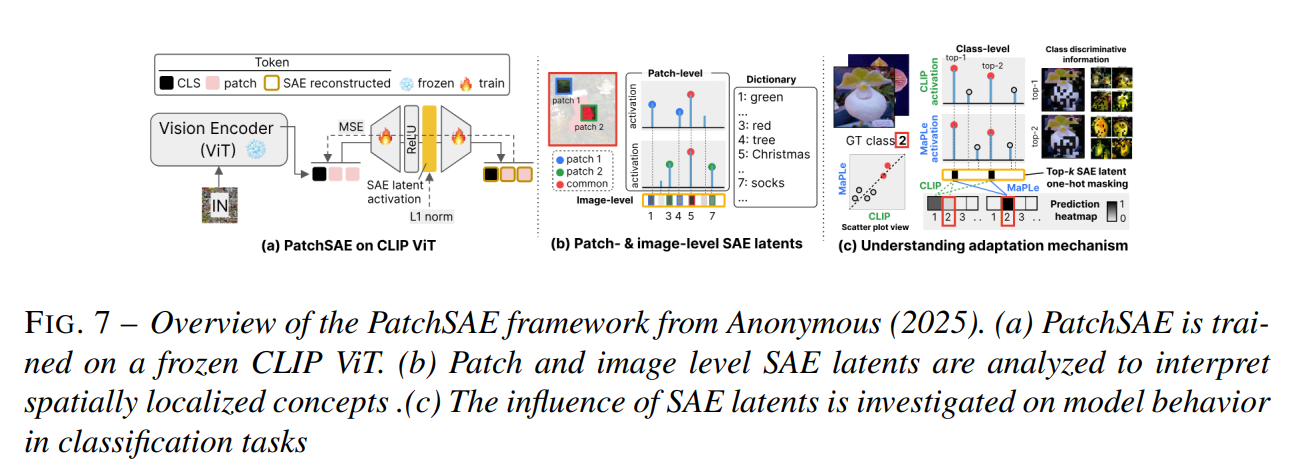
[논문 리뷰] Attention and Beyond: Explainability Techniques for Vision Transformers
논문 정보: "Attention and Beyond: Explainability Techniques for Vision Transformers" (주저자: Wadie El Amrani, 발표 연도: 2024/2025년 추정, 소속: Made In Tracker 및 UT
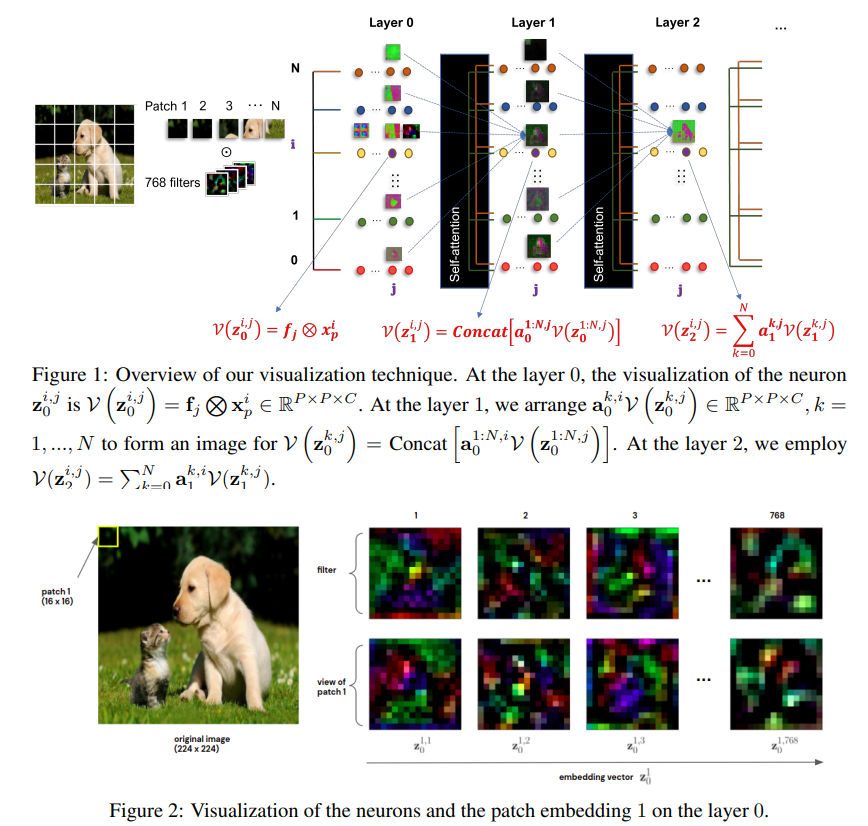
[논문 리뷰] Vision Transformer Visualization: What Neurons Tell and How Neurons Behave?
논문 기본 정보: 본 리뷰는 Van-Anh Nguyen 등이 2022년 작성한 "Vision Transformer Visualization: What Neurons Tell and How Neurons Behave?" 논문을 다루며, 비전 트랜스포머(ViT)의 특징 임
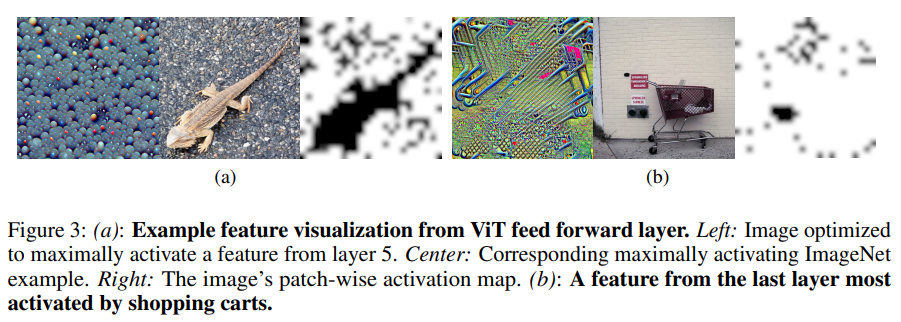
[논문 리뷰] What Do Vision Transformers Learn? A Visual Exploration
논문 정보: What Do Vision Transformers Learn? A Visual Exploration은 Amin Ghiasi, Hamid Kazemi, Eitan Borgnia, Steven Reich, Manli Shu, Micah Goldblum, And
[Robotics] 6. Robot CV Connection 정리
이 문서는 ROS2, 로봇 모델링, MoveIt, 컴퓨터비전이 하나의 로봇 작업 파이프라인으로 연결되는 과정을 정리한다. CV는 이미지에서 물체, 영역, 특징을 찾지만, 로봇이 행동하려면 그 결과가 depth, camera intrinsic, hand-eye calib
[Robotics] 5. CNN & Object Detection 이론 정리
이 문서는 컴퓨터비전이 사람이 설계한 feature에서 데이터로 학습한 feature로 확장되는 흐름을 정리한다. CNN은 convolution filter를 학습해 이미지의 지역 패턴을 추출하고, augmentation은 제한된 데이터에서 다양한 조건을 경험하게 해

[Robotics] 4. 고전 CV & Image Processing 이론 정리
이 문서는 딥러닝 이전의 컴퓨터비전 기초를 이미지의 수치적 표현과 규칙 기반 처리 관점에서 정리한다. 이미지는 픽셀 배열이며, grayscale/RGB, histogram, contrast, noise, edge, region 같은 신호 특성을 이해해야 이후 detec
[Robotics] 3. Isaac Sim 이론 정리
이 문서는 Isaac Sim을 로봇, 센서, 물리, 작업 시나리오를 가상 환경에서 검증하는 시뮬레이션 도구로 정리한다. Isaac Sim은 Omniverse와 USD 기반으로 로봇 모델, gripper, 물체, 물리 속성, camera/LiDAR/IMU/contact
[Robotics] 2. Robot Motion Tool 정리
0. 전체 내용 요약과 키워드 이 문서는 로봇의 구조를 정의하고, 그 구조를 실제 움직임으로 연결하는 과정을 정리한다. URDF/Xacro는 link, joint, visual, collision, inertial 정보를 통해 로봇의 몸과 운동학적 tree를 만든다. RViz는 이 모델과 TF, joint state, planning 결과를 시각화하고, ...
[Robotics] 1. ROS2 개념 정리
0. 전체 내용 요약과 키워드 이 문서는 ROS2를 로봇 시스템을 구성하는 분산 미들웨어로 정리한다. 핵심은 로봇 기능을 하나의 큰 프로그램이 아니라 여러 node로 나누고, node 사이를 topic, service, action으로 연결하는 방식이다. Topic은 지속적으로 흐르는 데이터, service는 요청과 응답, action은 시간이 걸리는 목...
[Project] MacGyvBot 로봇틱스 프로젝트 정리
MacGyvBot: 음성/GUI 기반 공구 전달 및 반납 로봇 어시스턴트MacGyvBot은 작업자가 공구 보관 장소까지 직접 이동하지 않아도, 로봇팔이 필요한 공구를 찾아 전달하고 사용 후 다시 서랍에 정리하는 ROS 2 기반 로봇 어시스턴트 프로젝트이다. 사용자는 음
[Business] 비즈니스 커뮤니케이션 이론 정리
비즈니스 커뮤니케이션을 공부하면서 가장 크게 느낀 점은, 커뮤니케이션이 단순히 말을 잘하는 기술이 아니라는 것이다. 말투, 태도, 표정, 복장, 전화 응대, 이메일 작성, 문자 한 줄까지 모두 상대에게 나를 보여주는 방식이다.결국 비즈니스 커뮤니케이션의 핵심은 상대와
[Business] Operation Management 이론 정리
생산운영관리(Operation Management, OM)를 한 학기 동안 공부하면서 가장 크게 느낀 것은, OM이 단순히 공장이나 생산라인을 관리하는 과목이 아니라는 점이다. 운영관리는 기업이 가진 사람, 자본, 설비, 원자재, 정보, 기술을 활용해 고객이 원하는 제
[Business] 마케팅 이론 정리
마케팅을 한 학기 동안 공부하면서 가장 크게 느낀 것은, 마케팅이 단순히 “물건을 잘 파는 방법”이 아니라는 점이다. 마케팅은 제품 자체를 설명하는 일이 아니라, 소비자가 그 제품을 어떻게 인식하게 만들 것인가를 설계하는 일에 가깝다. 즉, 제품의 기능, 가격, 디자인
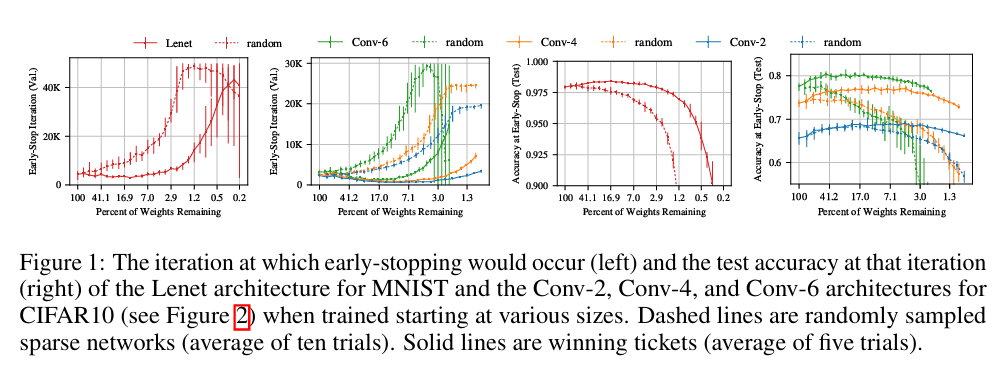
[논문 리뷰] THE LOTTERY TICKET HYPOTHESIS: FINDING SPARSE, TRAINABLE NEURAL NETWORKS
기본 정보: ICLR 2019에서 발표된 Jonathan Frankle과 Michael Carbin(MIT CSAIL)의 논문 "The Lottery Ticket Hypothesis: Finding Sparse, Trainable Neural Networks"입니다.목
[Insight] 네트워크관리사 2급 필기 정리
FTP는 응용 계층 프로토콜이다.HTTP는 응용 계층 프로토콜이다.HTTPS는 TLS를 통해 애플리케이션 계층 데이터를 암호화한다.SNMP는 응용 계층 프로토콜이다.IPsec은 OSI 3계층에서 동작한다.L7 스위치는 응용 계층에서 동작한다.메시지를 짧은 패킷으로 분할
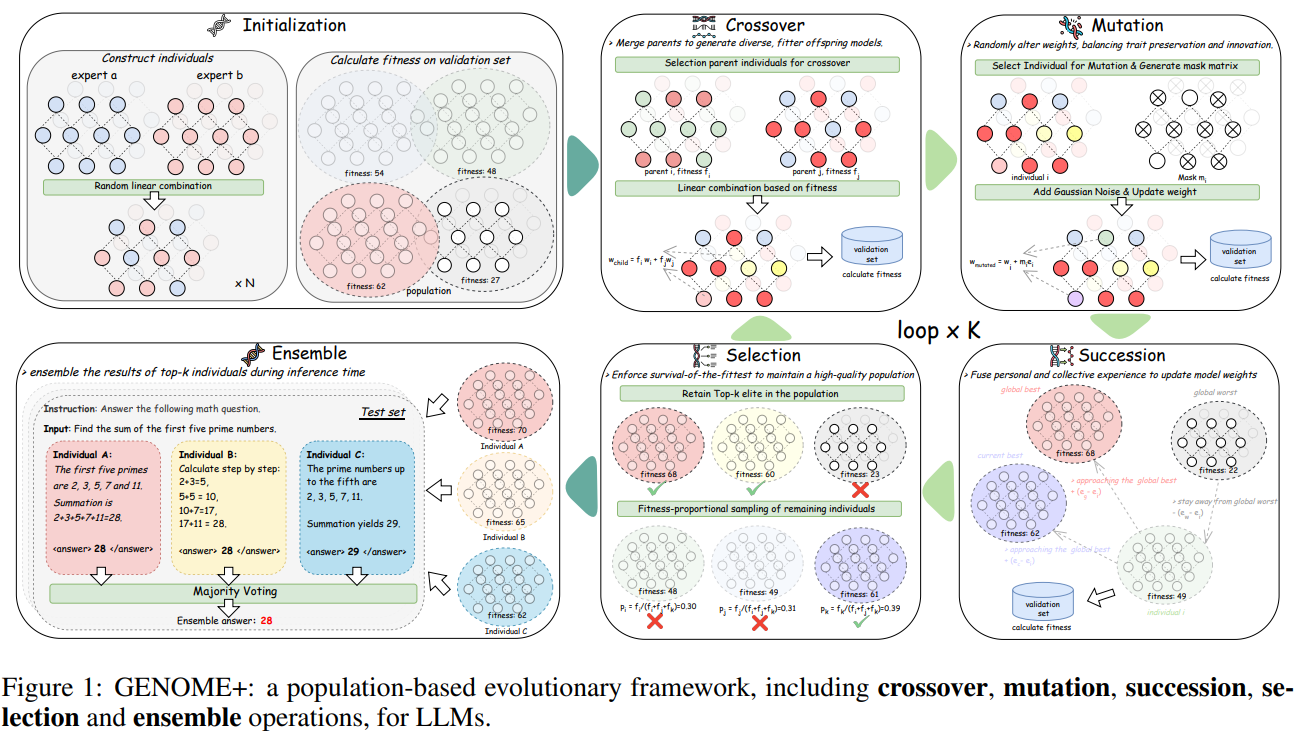
[논문 리뷰] NATURE-INSPIRED POPULATION-BASED EVOLUTION OF LARGE LANGUAGE MODELS
기본 정보: 본 논문은 "NATURE-INSPIRED POPULATION-BASED EVOLUTION OF LARGE LANGUAGE MODELS"라는 제목으로 Yiqun Zhang 등(Northeastern University, Shanghai AI Lab)이 202