
- 전체보기(67)
- Deep Learning(11)
- PyTorch(10)
- machine learning(7)
- 인공지능(6)
- Spring(4)
- CNN(4)
- ML(4)
- 기계학습(3)
- PCA(2)
- Linear Regression(2)
- 강화학습(2)
- group normalization(1)
- Lexical Retrieval(1)
- Eigen-Decomposition(1)
- Regularization(1)
- REST(1)
- ViT(1)
- rag(1)
- Minimax Algorithm(1)
- SVM(1)
- Vision Transformer(1)
- Embedding Model(1)
- NLP(1)
- 군집화(1)
- Fuzzy Logic(1)
- transfer learning(1)
- KNN(1)
- blind search(1)
- GoogleNet(1)
- EfficientNet(1)
- genetic algorithm(1)
- REINFORCE 알고리즘(1)
- DenseNet(1)
- MSE(1)
- Agentic Pattern(1)
- Heuristic Search(1)
- 비지도학습(1)
- Curse of Dimensionality(1)
- transformer(1)
- REST API(1)
- 차원의저주(1)
- SVD(1)
- Decision Boundary(1)
- api 명세서(1)
- filter(1)
- Xception(1)
- Semantic Retrieval(1)
- 랜덤 포레스트(1)
- REINFORECE(1)
- Agentic AI(1)
- Multiple Linear Regression(1)
- Decision Space(1)
- k-means(1)
- Knowledge Representation(1)
- segmentation(1)
- cost function(1)
- Resnet(1)
- Expert System(1)
- Gradient Descent(1)
- 지도학습(1)
- feature space(1)
- 탐색(1)
- 결정트리(1)
- 영상처리(1)
- Mobilenet(1)
- 앙상블(1)
- Alpha-beta pruning(1)
- Spatial Filtering(1)
- SEE(1)
- Bias-Variance Trade-off(1)
- Object Detection(1)
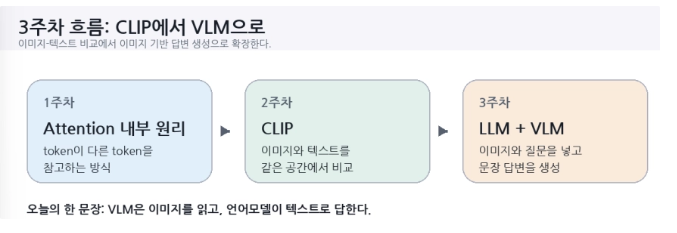
LLM과 VLM
LLM은 Large Language Model의 약자로, 대량의 텍스트를 학습한 언어 모델이다. LLM은 완성된 문장을 한 번에 만들어내는 것이 아니라, 앞에 나온 token들을 보고 다음 token의 확률분포를 예측하는 방식으로 문장을 생성한다. 즉, LLM의 기본
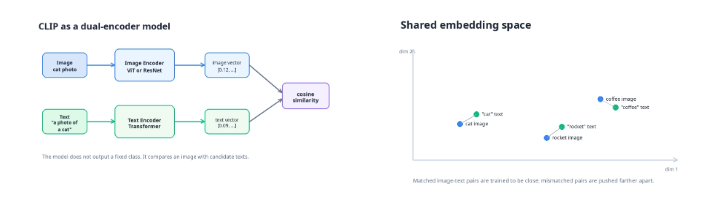
CLIP과 멀티모달 AI
멀티모달 AI는 이미지, 텍스트, 음성처럼 서로 다른 형태의 데이터를 함께 다루는 AI이다. 예를 들어, 이미지와 텍스트를 함께 다루는 경우, 사진과 문장을 비교하고 모델은 이미지와 각 문장이 얼마나 잘 맞는지 계산할 수 있다. CLIP은 이미지와 텍스트를 같은 벡터
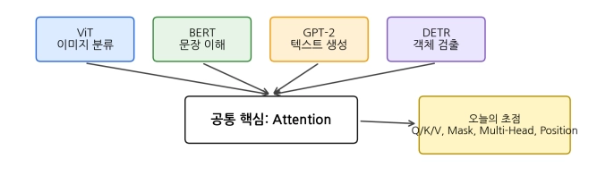
Attention과 Transformer
기존 RNN 기반 Sequence-to-Sequence 모델은 입력 문장을 순서대로 읽고, 마지막 hidden state 또는 하나의 context vector c에 입력 전체의 정보를 압축한 뒤 decoder로 전달하는 구조이다. 예를 들어 영어 문장 we see
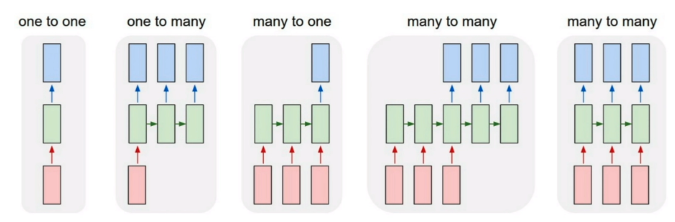
RNN, LSTM, and GRU
핵심 : 문장, 음성 신호, ECG 파형, 수요 곡선 같은 데이터는 단순히 독립적인 값들의 집합이 아니라 순서가 있는 객체이다. 따라서 순서를 고려할 수 있는 sequence model이 필요하다.기존 feed-forward layer는 입력 x 하나를 받아서 선형 변
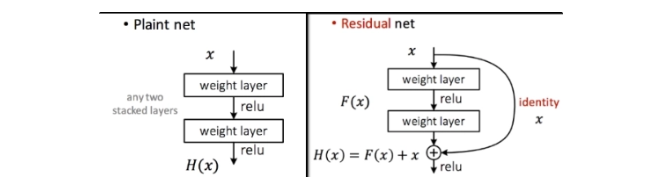
ResNet 이해
깊은 네트워크 학습을 어렵게 만드는 대표적인 문제로 gradient vanishing/exploding이 있다. 하지만 ResNet 논문에서 강조한 degradation problem은 단순히 gradient vanishing 때문만은 아니며, 깊은 plain net
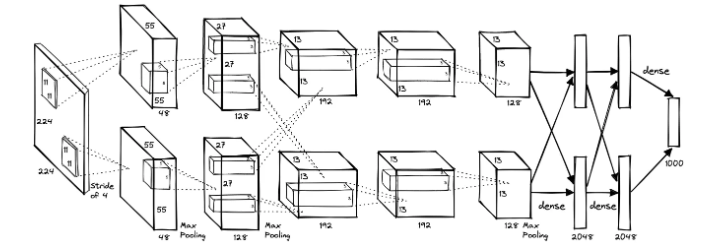
AlexNet
설정 수치에서 나오는 ILSVRC는 ImageNet Large Scale Visual Recognition Challenge 의 약자로, 매년 열린 이미지 인식 대회이다.2010년 데이터셋의 특징 :테스트 데이터의 정답 레이블이 공개되어 있어, 연구자들이 모델을 학습

Pytorch 모델 학습
CIFAR-10은 컴퓨터 비전 입문에서 가장 널리 쓰이는 이미지 분류 데이터셋이다.총 10개 클래스 (airplane, automobile, bird, cat, deer, dog, frog, horse, ship, truck)학습 데이터 : 50,000장 / 테스트

Segmentation & Connected Component Analysis
영상 분할(Segmentation)은 이미지를 여러 개의 영역(Region)으로 나누는 작업을 의미한다. 즉, 이미지 안에서 특정 객체(Object)와 배경(Background)을 구분하거나, 색상, 밝기, 텍스처 등이 유사한 픽셀들을 하나의 영역으로 묶는 과정이다.
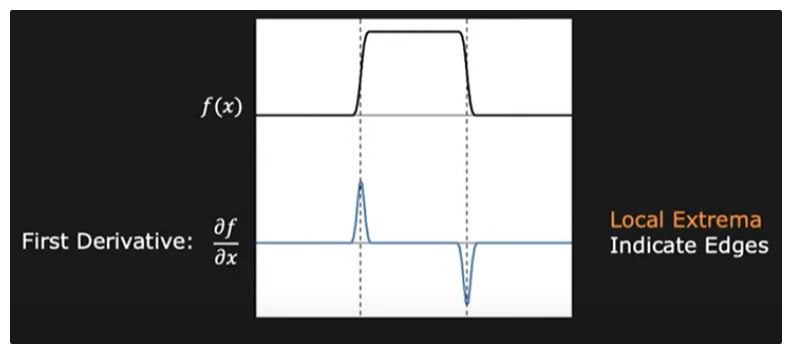
Edge Detection (에지 검출)
에지란, 이미지에서 픽셀 값(밝기나 색 등)이 급격히 변하는 지점을 의미한다. 예를 들어 물체의 테두리나 강한 명암 대비가 있는 경계 부분 등이 에지에 해당한다. 에지는 물체 인식 및 영상 분할의 기초가 되기 때문에 매우 중요한 정보이다. 영상에서 에지를 찾을 때 자
Corner Detection & Optical Flow
Corner Detection 코너란? 코너는 단순히 모서리처럼 보이는 점이 아니라, 어떤 작은 패치(patch)를 상하좌우 어느 방향으로 움직여도 원래 패치와 많이 달라지는 위치를 의미한다. 연속된 프레임에서 같은 점을 다시 찾으려면, 그 점 주변의 작은 이미지

YOLO
객체 탐지가 분류(classification)이나 분할(segmentation)과 어떻게 다른지 알아보자!Image Classification : 이미지 전체에 대해 하나의 라벨을 예측하는 것 (ex) 이 사진은 고양이인가? Localization : 이미지에 하나
OpenCV
cv2.imread(filename, flages) : 이미지를 읽어오는 함수flags : 색상 모드 지정 (ex) cv2.IMREAD_COLOR - 컬러 이미지로 읽기, cv2.IMREAD_GRAYSCALE - 그레이스케일로 읽기, cv2.IMREAD_UNCHANGE
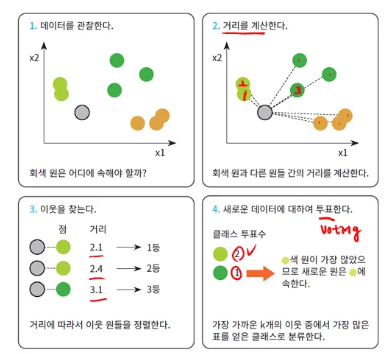
KNN, K-Means
kNN(k-Nearest Neighbor) 알고리즘은 k개의 가장 가까운 이웃 데이터를 찾고, 그 이웃들의 레이블을 기반으로 분류/회귀 문제를 해결하는 알고리즘을 의미한다. kNN 알고리즘은 새 데이터가 입력으로 들어오면, 이 포인트가 어떤 클래스에 속해있는지를 찾는
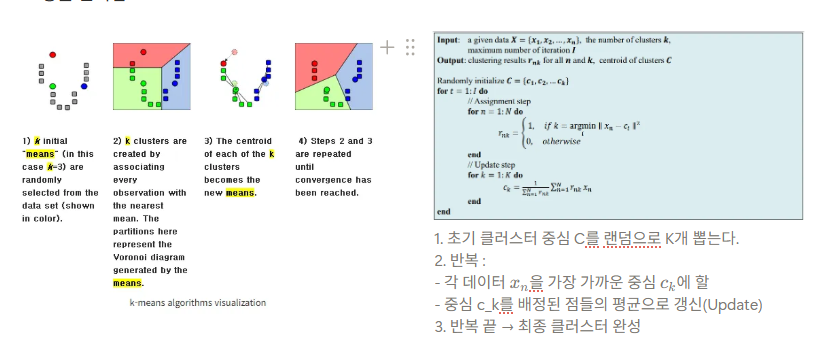
주성분분석과 군집화
차원의 저주(Curse of dimensionality)란, 학습 데이터에 비해 입력 차원의 수가 큰 경우 일정 차원을 기점으로 학습 능력이 급격히 감소하는 현상을 의미한다. 다시 말해, 특징 공간의 차원이 증가하면서 학습 데이터의 수가 특징 공간의 차원의 수보다 적
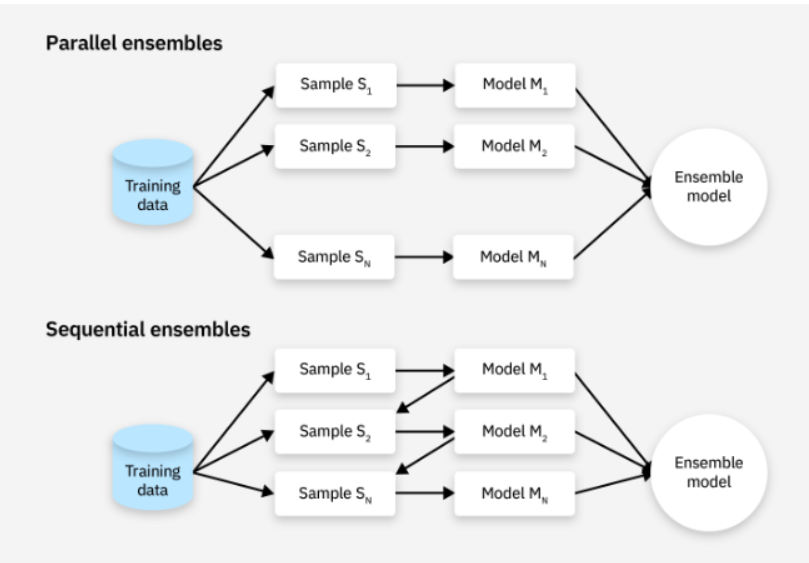
앙상블과 랜덤 포레스트
앙상블 기법이란, 여러 개 분류기를 생성하고, 그 예측을 결합함으로써 보다 정확한 예측을 도출하는 기법으로, Strong Classifier를 사용하는 대신 Weak Classifier를 조합하여 더 정확한 예측을 수행한다. 이는 단일 모델의 예측을 평가하는 것보다
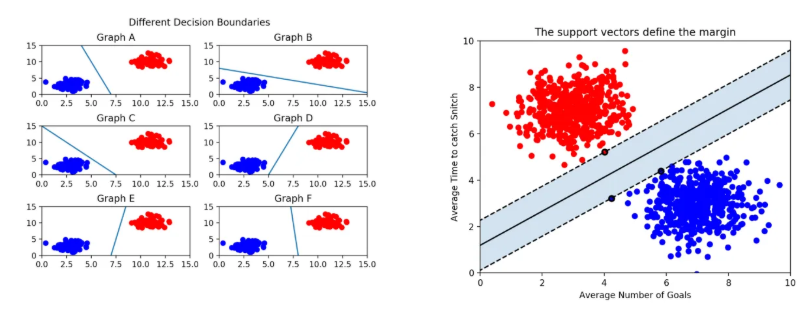
서포트 벡터 머신과 결정 트리
서포트 벡터머신은 선형/비선형 분류, 회귀, 이상치 탐색 등 복잡한 분류 문제에 적합한 다목적 기계학습 모델로, 중간 이하 크기의 데이터셋에 적합한 방법이다. 이는 분류를 위한 최적의 결정 경계를 찾는 것을 목표로 하며, 최적의 결정 경계라는 것은 다수의 결정 경계
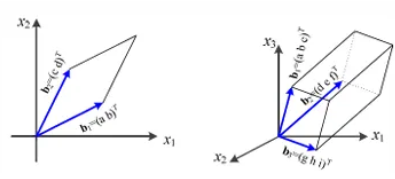
Eigen-Decomposition, PCA, SVD
벡터 : 방향과 크기를 갖는 대상행렬 : 여러 벡터를 열로 담은 구조행렬은 교환법칙이 성립하지 않는다. ($AB ≠ BA$)행렬은 분배법칙과 결합법칙이 성립한다.$A(B + C) = AB + AC$ (분배법칙), $A(BC) = (AB)C$ (결합법칙)행렬의 곱셈을 위
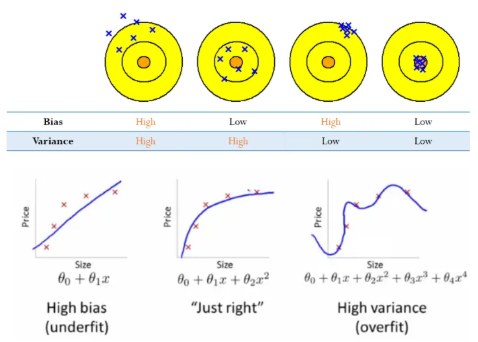
과대적합, 규제, Bias-Variance Trade-off
모델 선택과 과대적합 선형 회귀 (Linear Regression) 선형 회귀란, 두 번수 x, y에 대한 n개의 측정 값(ex. $(x1, x1), (x2, y2), … (xn, yn)$)이 있을 때, 주어진 가설(Hypothesis)에 대한 비용(Co
특징 공간과 차원의 저주
특징 공간(Feature Space)이란, 데이터의 각 샘플이 가진 여러 특징(feature)들을 좌표로 표현하는 다차원 공간이다. 쉽게 말해, 특징들이 수치회된 벡터 공간이라고 할 수 있다. 머신러닝에서는 데이터가 특징 공간 내의 점(벡터)으로 표현되며, 모델이 패

Fuzzy Logic
Fuzzy라는 단어는, 흐릿한, 불분명한이라는 의미를 가진다. 여기서도 알 수 있듯, 퍼지 논리(Fuzzy Logic)는 명확하게 구분되지 않는 개념을 수학적으로 다루는 방법, 다시 말해 정확하지 않거나(imprecise) 불완전한(incomplete) 정보를 처리하